大数据数据库工具到底都有哪些,哪些比较实用值得一试呢?

要搞清楚大数据数据库工具,首先得明白为什么会有这么多不同类型的工具,传统的关系型数据库(比如MySQL、PostgreSQL)在处理海量数据时,就像是用一辆小轿车去拉一整座山的货物,不是车不好,而是活儿不对路,大数据场景下,数据量太大(Volume)、数据产生和变化的速度太快(Velocity)、数据的种类五花八门(Variety),这“3V”挑战催生了各种专门化的工具。
这些工具可以从不同角度分类,但最核心的区别在于它们如何处理和分析数据,也就是所谓的“处理范式”,下面我就围绕这个核心,介绍几类主流的工具,并重点说说哪些比较实用、值得一试。

Hadoop生态圈:批处理的“老大哥”
提到大数据,Hadoop是绕不开的鼻祖,它核心的思想是“分而治之”,把巨大的数据和计算任务拆分成小块,分发给一群普通的电脑去处理,最后再把结果汇总起来,这就像是请一个建筑队来盖楼,而不是靠一个工程师单干。

- HDFS(Hadoop Distributed File System):这是Hadoop的存储核心,一个分布式的文件系统,它能把超大文件切块,然后分散存储在多台机器上,保证了数据的可靠性和可扩展性,你可以把它想象成一个大工地的集中仓库。
- MapReduce:这是Hadoop最初的计算模型,处理数据分两步走:“Map”阶段是分工,让每台机器处理自己手上的数据;“Reduce”阶段是汇总,把各台机器的初步结果合并成最终答案,这个过程虽然强大,但编程相对复杂,速度也偏慢,适合处理对实时性要求不高的海量历史数据(即批处理)。
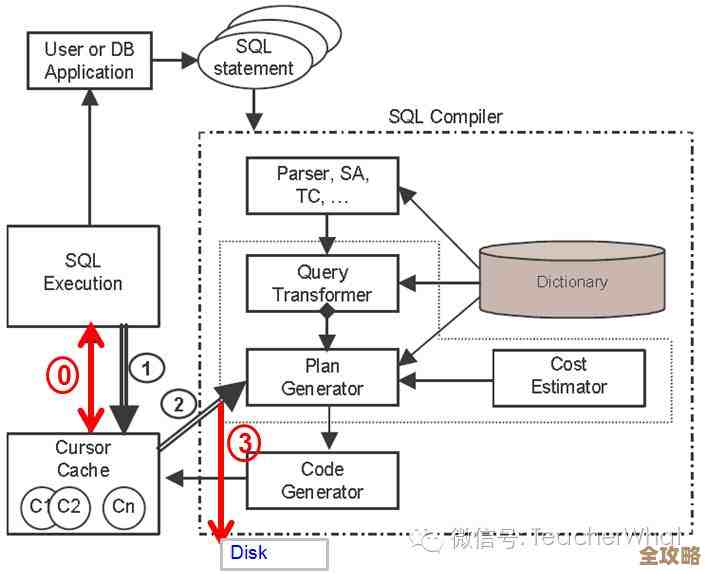
- 值得一试的实用工具:Hive Hive可以说是让Hadoop变得“亲民”的关键工具,它允许你使用类似SQL的语法(称为HiveQL)来查询存储在HDFS上的数据,背后它会自动把你的SQL翻译成MapReduce任务去执行,对于熟悉SQL的数据分析师来说,这大大降低了学习成本,可以快速开始对海量数据进行探索和分析,尽管现在有更快的工具,但Hive在数据仓库、离线报表等场景中依然非常稳定和实用。(来源:Apache软件基金会官方文档及社区实践)
实时计算与流处理:要“快”的选手
当业务需要实时监控、实时推荐或实时风控时,等几个小时后出结果的批处理就太慢了,这时就需要流处理工具,它们像是一条永不停止的流水线,数据一来就立刻处理。

- Apache Kafka:首先得有个高速的数据通道,Kafka就是一个高吞吐量的分布式消息队列,它就像数据的高速公路,负责接收、缓存和分发源源不断产生的实时数据流,很多实时处理系统都以Kafka作为数据源。
- 值得一试的实用工具:Apache Flink Flink是当前流处理领域的明星,它的设计理念是“流处理优先”,认为批处理只是流处理的一种特例,这意味着Flink在处理实时数据流时具有极低的延迟和高吞吐率,它提供了精确一次处理(Exactly-once)的语义保证,确保数据既不会丢也不会重复计算,这对于金融交易等关键业务至关重要,Flink也支持类似SQL的API,易用性很好,如果你有强烈的实时数据处理需求,Flink是非常值得投入学习的工具。(来源:Flink官方文档及各大科技公司的技术博客分享)
- 另一个选择:Apache Spark Spark严格来说是一个统一的分布式计算引擎,它不仅能做批处理,通过Spark Streaming模块也能做微批处理(把数据流切成很小的时间片来近似实时处理),Spark的优势在于其内存计算,速度比Hadoop MapReduce快很多,且生态丰富(包括机器学习库MLlib、图计算库GraphX),如果你的场景是准实时,并且需要混合使用批处理、流处理和机器学习,Spark是一个综合实力很强的选择。(来源:Spark官方文档)
新型的NoSQL数据库:不拘一格的“特长生”
关系型数据库要求数据有固定的结构(schema),但大数据时代很多数据是半结构化(如JSON日志)或无结构的,NoSQL数据库放弃了关系模型,在不同场景下追求极致的性能。
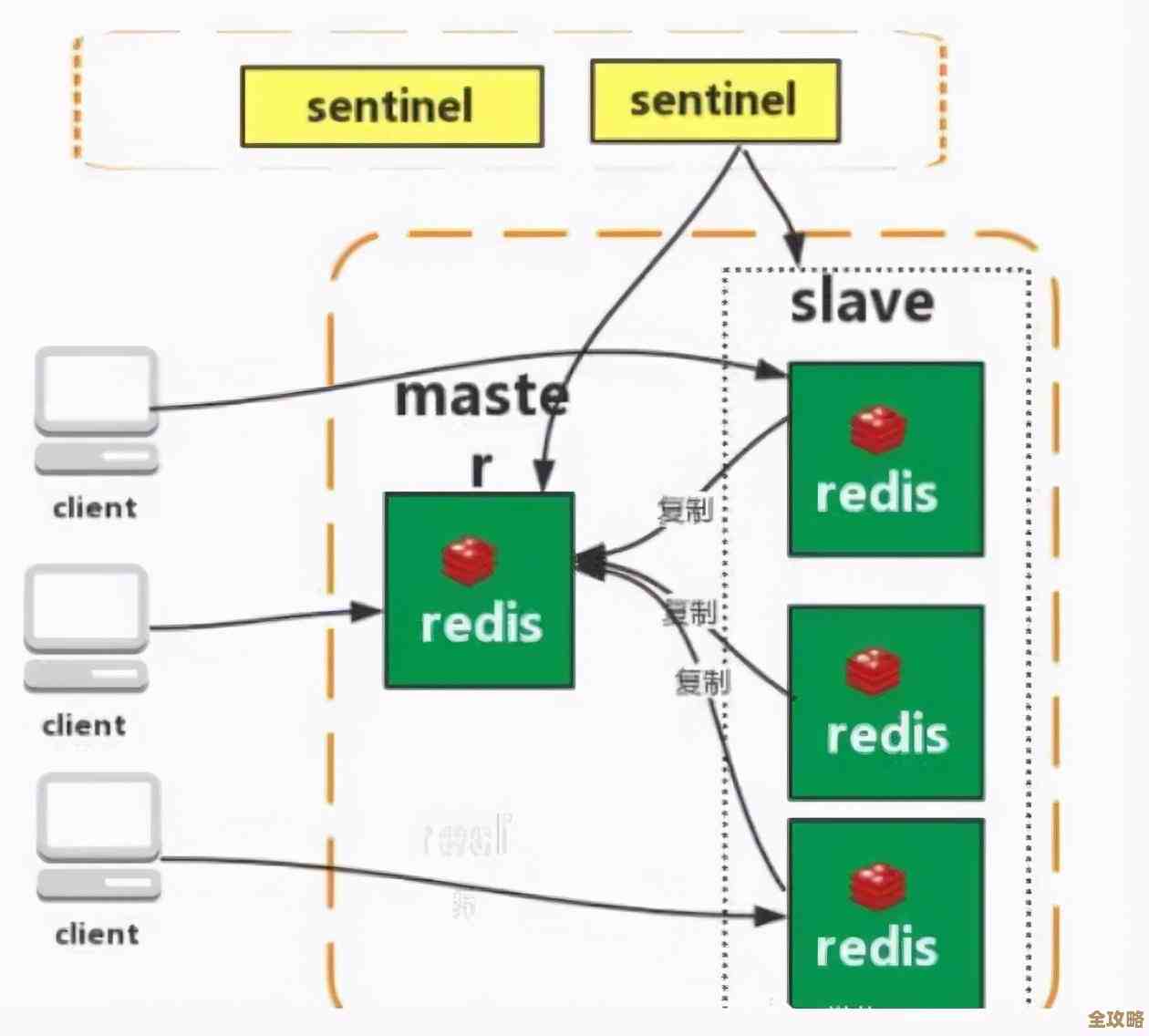
- 键值数据库:像一个大字典,通过唯一的Key来快速查询Value,简单粗暴,速度极快。Redis是其中最著名的代表,常被用作缓存,提升应用速度。
- 文档数据库:数据以类似JSON的文档格式存储,非常灵活,适合存储产品目录、用户配置等。MongoDB是这方面的主流选择,开发者上手容易。
- 列式数据库:传统数据库按行存储,而列式数据库按列存储,当需要快速扫描和分析某几列的数据时(比如统计所有用户的年龄分布),效率极高。Apache HBase(基于HDFS)和ClickHouse是典型代表,特别是ClickHouse,在处理大规模数据分析查询时,速度惊人,在互联网公司的日志分析和BI报表领域非常流行,非常值得一试。(来源:DB-Engines排名及各数据库官方文档)
- 图数据库:专门用于处理关系数据,比如社交网络、反欺诈分析,它用节点和边来存储数据,能高效查询复杂的关联关系。Neo4j是这方面的领导者。
总结与建议
这么多工具,到底该学哪个、用哪个?这完全取决于你的具体需求:
- 如果是做传统的、周期性的海量数据分析(T+1报表等):可以从Hive入手,稳定且学习曲线平缓。
- 如果需要实时处理数据流(实时监控、实时推荐):Flink是当前的技术前沿,前景广阔。
- 如果需要一个全能型选手,兼顾批处理、准实时和机器学习:Spark生态成熟,是不错的选择。
- 如果需要极高速度的交互式查询分析(OLAP):可以重点关注ClickHouse。
- 如果应用需要灵活的、半结构化的数据存储:MongoDB很适合快速开发。
一个成熟的大数据平台往往是多种工具的组合,比如用Kafka接收数据,用Flink进行实时处理,将结果存入ClickHouse供业务查询,同时原始数据也存入HDFS,由Hive或Spark进行离线深度分析,理解每种工具的核心优势和适用场景,才能在实际工作中做出最实用的选择。
本文由召安青于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/70185.html