Oracle绑定变量用起来效率能提升多少,背后原理到底是啥?

关于Oracle绑定变量用起来效率能提升多少,以及背后的原理,我们可以从一个非常生活化的比喻开始,想象一下你去一家生意兴隆的咖啡店买咖啡。
没有绑定变量(硬解析) 你走到柜台前说:“我要一杯大杯的加糖加奶油的拿铁咖啡。” 咖啡师点点头,开始找配方、准备材料、制作,后面又来一个人说:“我要一杯中杯的无糖脱脂的卡布奇诺。” 咖啡师虽然刚做完拿铁,但卡布奇诺是另一套做法,他得放下手里的东西,重新去查卡布奇诺的配方,换一种牛奶,换一种制作流程,每一个顾客点完全不同的咖啡,咖啡师每次都要从头开始“思考”和“准备”,柜台很快就堵住了,队伍行进得非常慢。
使用绑定变量(软解析) 这次你走到柜台前说:“我要一杯咖啡,型号是大的,类型是拿铁,糖度是加糖,奶型是奶油。” 聪明的咖啡师立刻明白了,你用的是标准点单模板,他脑子里已经有一个固定的高效流程(Parse Tree,解析树),后面的人只需要说:“我也要一杯咖啡,型号是中杯,类型是卡布奇诺,糖度是无糖,奶型是脱脂。” 咖啡师不需要重新学习怎么做咖啡,他只需要根据你提供的几个关键参数(绑定变量),套用到那个高效的固定流程里就行了,速度飞快,队伍畅通无阻。
这个咖啡店就是Oracle数据库,咖啡师就是数据库的SQL引擎,而你点的咖啡的具体要求(大杯、拿铁)就是SQL语句。绑定变量,就是那个“标准点单模板”里的占位符(1, :2),它把变化的数值(比如100, ‘张三’)从固定的SQL语句结构中分离出来。
效率能提升多少?
这个提升是数量级的,尤其是在高并发、重复执行频繁的系统中(比如电商网站、银行交易系统),提升主要体现在两个方面:
-
减少解析时间(CPU消耗): 这是最直接的提升,根据Oracle官方文档和大量实践案例(如Oracle官方优化手册、《Oracle Database Concepts》),一次硬解析的成本是一次软解析的数十倍甚至上百倍,当一个SQL语句首次执行时,数据库必须进行“硬解析”:检查语法、检查语义(表名、列名是否存在)、检查权限、在成千上万的执行计划中找一个最优的(这步最耗资源),如果每秒有1000次查询都不使用绑定变量,数据库就要做1000次这样沉重的“思考”,CPU很快就会被解析工作占满,真正执行查询的时间反而少了,而使用绑定变量,除了第一次是硬解析,后面的999次都是几乎零成本的“软解析”,数据库只需要把新的变量值套用进第一次生成的执行计划里即可,CPU压力骤降,系统吞吐量会成倍增长。

-
减少共享池的争用和碎片(内存消耗): Oracle有一个核心内存区域叫“共享池”(Shared Pool),它就像一个“菜谱库”,存放着所有解析过的SQL语句和执行计划,如果不使用绑定变量,每一条带不同值的SQL(比如
SELECT * FROM users WHERE id=1和SELECT * FROM users WHERE id=2)都会被数据库认为是两条完全不同的“菜谱”,都会在共享池里占据一块空间,瞬间,共享池就会被大量几乎一模一样的“菜谱”塞满,导致内存浪费和频繁的内存清理(Age Out),这又会引发更多的硬解析,形成恶性循环,而使用绑定变量,无论查询一万个不同的用户ID,在共享池里都只有一条“菜谱”(SELECT * FROM users WHERE id=:id),极大地节省了内存,稳定了共享池。
背后原理到底是啥?
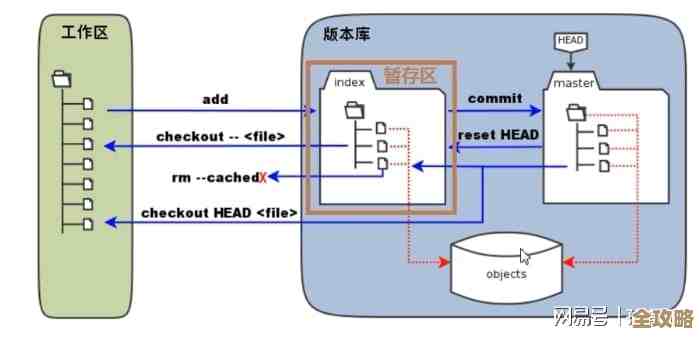
原理的核心就在于共享池和游标共享。
-
SQL语句的“指纹”:当Oracle收到一条SQL语句时,它会先对其进行哈希运算,生成一个唯一的“指纹”,数据库会用这个指纹去共享池里查找,看是不是已经存在相同的“指纹”(即已经解析过的SQL)。

-
硬解析的沉重代价:如果没找到(即库缓存未命中,Library Cache Miss),就会触发硬解析,这个过程非常复杂,包括:
- 语法分析: 检查SQL语句的语法是否正确。
- 语义分析: 检查涉及的表、视图、列等对象是否存在,以及当前用户是否有权限访问。
- 执行计划生成: 这是最耗资源的一步,优化器(Optimizer)会考虑表的统计信息、索引、数据分布等多种因素,生成多个可能的执行计划,并计算每个计划的成本(Cost),最终选择一个它认为最优的计划。
-
绑定变量如何破局:当你使用绑定变量时,比如
SELECT name FROM users WHERE id = :v_id,无论你后续传入的:v_id是100、200还是300,这条SQL语句的“指纹”始终是不变的,当数据库第一次执行它时,会进行完整的硬解析,生成执行计划,并将这个“语句-计划”组合缓存在共享池中,第二次及以后执行时,数据库计算指纹,发现共享池里已经有完全匹配的条目了(库缓存命中,Library Cache Hit),它就完全可以跳过昂贵无比的硬解析步骤,直接取出上次缓存的执行计划,将新的变量值绑定进去,然后执行,这个过程就是“软解析”,速度极快。
一个需要了解的例外:绑定变量窥探
绑定变量并非完美无缺,这里有一个重要的技术点需要了解,叫做绑定变量窥探,在第一次硬解析时,优化器会“窥探”一下你传入的变量值是什么,并用这个值来生成执行计划,比如users表,如果id=1的数据占了全表的90%(极端例子),那么对于id=1这个查询,全表扫描可能比走索引更快,如果第一次执行碰巧传入了id=1,优化器就生成了一个全表扫描的计划并缓存,后续即使你查询id=99999(可能只有一行数据),数据库也会盲目复用那个全表扫描计划,导致性能灾难,这就是为什么在数据分布极度不均匀的列上,使用绑定变量有时反而会带来问题的原因(Oracle后续版本有自适应游标共享等机制来缓解此问题)。
总结一下
使用Oracle绑定变量,效率的提升是革命性的,主要节省了CPU和内存这两大最宝贵的数据库资源,从而极大地提升了系统的并发处理能力和稳定性,其背后的核心原理,是通过将SQL语句的结构与值分离,使得数据库能够最大限度地复用已经辛苦准备好的“执行计划”,避免了重复性的、高成本的“硬解析”过程,它就像给数据库设计了一套标准化的流水线作业,让数据库从手工作坊变成了高效工厂。
本文由畅苗于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/70228.html