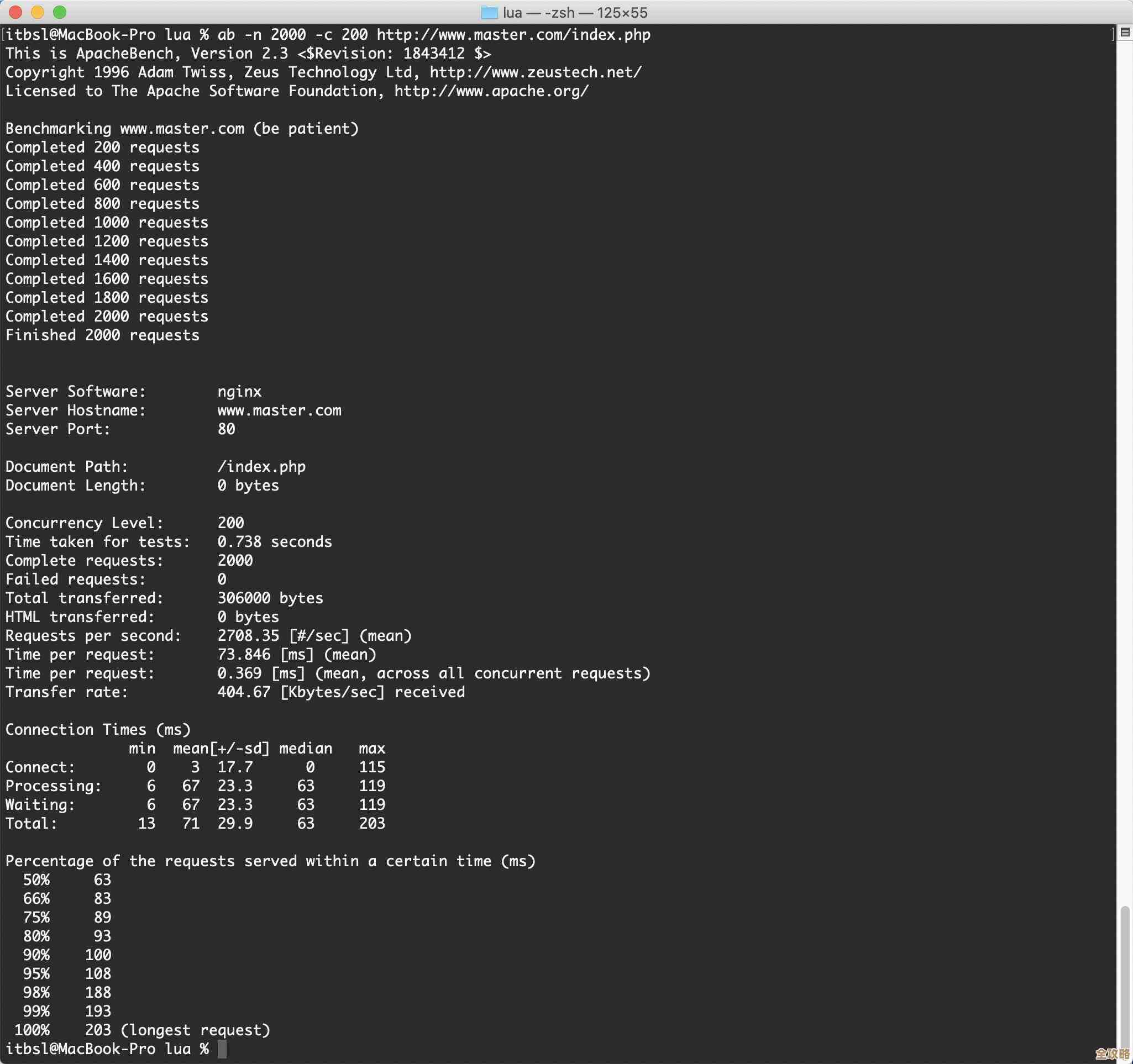
Redis本地内存溢出咋整,教你几招不让它崩溃

Redis本地内存溢出这事儿,确实挺让人头疼的,眼瞅着内存蹭蹭往上涨,警报呜呜响,服务随时可能挂掉,别慌,咱们一步步来,有几招实实在在的办法能把它稳住,不让它轻易崩溃。

第一招,别让数据“赖着不走”,赶紧给数据上个“闹钟”。 这是最基本也最有效的一招,很多数据放进去就没管过,成了“永久居民”,内存能不爆吗?你得给这些数据设置一个合理的过期时间(TTL),哪怕是业务上需要长期存在的数据,也可以评估一下,是不是真的需要永远存在?能不能设置一个很长的过期时间,比如几天甚至几个月,然后通过程序定期刷新?这能从根本上避免数据无限堆积,这个思路在Redis的官方文档里关于键过期的一章就强调过,管理内存的第一要务就是善用过期机制。

第二招,立好规矩,告诉Redis内存满了该“赶走”谁。 光设过期时间还不够,万一内存真的撑满了呢?所以你得提前定好“淘汰策略”,这就像房子住满了,新客人来了,你得决定请走哪一位老客人,Redis提供了好几条规矩让你选,你可以在配置文件里(redis.conf)设置maxmemory-policy,常用的有:

- allkeys-lru:比较通用,在所有的键里,挑最近最少用的那些淘汰掉,适合用来做缓存的情况。
- volatile-lru:只在设置了过期时间的键里,淘汰最近最少用的,这能保证没设过期时间的“重要数据”不被误伤。
- volatile-ttl:在设了过期时间的键里,挑那些剩余寿命最短的赶紧淘汰。 选哪条规矩,得看你的业务,如果全是缓存数据,用allkeys-lru很省心;如果混合了缓存和重要持久数据,就用volatile-lru,这条规矩是Redis内存管理的核心防线,在《Redis设计与实现》这本书里也花了大篇幅讲解各种淘汰算法的原理和选择。
第三招,给内存瘦身,检查有没有“虚胖”的数据。 不是数据太多,而是单个数据太大,比如一个字符串好几MB,或者一个集合里塞了几十万个成员,这种“大Key”特别消耗内存,还会拖慢操作速度,你得想办法找到它们并“拆解”掉。
- 可以用命令慢慢排查,比如用
redis-cli --bigkeys扫描一下(生产环境慎用,可能影响性能),或者用SCAN命令自己写脚本分析。 - 找到大Key后,想想能不能拆分,比如一个巨大的用户信息字符串,能不能拆成多个小键用哈希(hash)存储?一个存储了百万用户ID的集合,能不能按用户ID的范围拆分成多个小集合?这招需要业务配合改造,但效果显著。
第四招,终极手段:横向扩展,别把所有鸡蛋放一个篮子里。 如果前面几招都用了,内存还是紧张,那说明你的数据量真的超过了单台机器的能力,这时候就得考虑“分片”了,也就是把数据分散到多个Redis实例上去,你可以用客户端分片,也可以用Redis Cluster(官方集群方案),或者通过代理中间件(如Codis、Twemproxy)来实现,这相当于把一间大房子换成了几间小公寓,每间公寓的压力自然就小了,不过这会增加架构的复杂度,需要客户端支持,并且不是所有命令都能在集群中完美支持,关于分片和集群的详细方案,在Redis官网的集群教程中有完整的阐述,是解决内存和性能瓶颈的根本之道。
别忘了“防患于未然”的日常功课。
- 监控报警:给Redis的内存使用率设置监控,比如超过80%就告警,让你有充足的时间处理,而不是等到100%了才手忙脚乱。
- 定期分析:可以用像
redis-rdb-tools这样的工具,定期分析RDB持久化文件,看看内存都被哪些类型的数据、哪些前缀的键占用了,做到心中有数。 - 规范开发:和开发同学定好规范,存Redis必须设过期时间,避免存储大对象,优先使用更节省内存的数据结构(比如用hash代替一堆独立的string键)。
对付Redis内存溢出,核心思路就是:主动清理(过期)、定好规矩(淘汰)、优化数据(拆Key)、最终扩容(分片),结合监控和规范,完全可以让你的Redis稳稳当当地跑下去,不至于动不动就崩溃给你看,这些方法都是社区和官方在实践中总结出来的,照着做,准没错。
本文由帖慧艳于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/85200.html