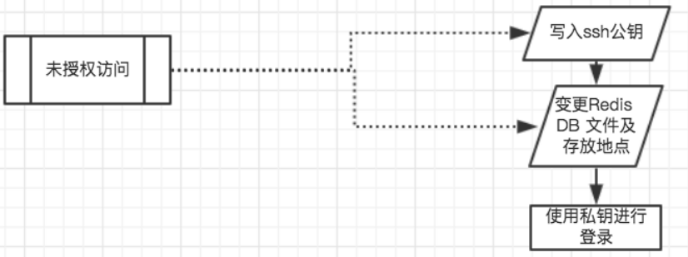
Redis 集群那些事儿,想搞明白它到底是咋回事就得先知道这些东西

Redis集群那些事儿,想搞明白它到底是咋回事就得先知道这些东西
要想弄懂Redis集群,你不能一上来就扎进那些复杂的配置命令里,那样很容易晕,你得先把它想象成一个团队,这个团队是为了解决单个Redis成员(我们叫它单节点或者单实例)能力有限的问题而组建的,单个Redis成员虽然干活利索,但有两个致命的短板:一是它的内存是有限的,数据多了就存不下了;二是它只有一个,万一它病倒了(服务器宕机),整个服务就瘫痪了。
Redis集群的核心目标就是两个:数据分片(把海量数据分散存放,解决内存不够的问题)和高可用(保证服务7x24小时不间断,即使有成员倒下也能立刻顶上)。
第一件大事:数据怎么分家?——说说分片

你有一个超大的字典,一个人根本背不动,怎么办?很自然的想法是,找几个人来,把字典撕成几份,每人负责背一部分,Redis集群干的就是这个“撕字典”和“分配任务”的活儿。
那具体怎么“撕”呢?Redis集群采用了一种叫做“哈希槽”(Hash Slot)的机制(根据《Redis设计与实现》中的描述),你可以把哈希槽想象成16384个(0到16383号)固定的小抽屉,这些抽屉会均匀地分配给集群里的每一个主节点(Master Node),当你存一个数据时,比如想存 user:1001 这个键,集群会用一个公式计算一下:CRC16('user:1001') % 16384,算出来一个介于0到16383之间的数字,假设是5000,那么好了,这个 user:1001 键值对就会被放进编号5000的那个小抽屉里,而这个小抽屉被分配给了哪个主节点,数据就实际存储在那个主节点上。
这样做的好处非常明显:数据被均匀打散了,每个节点只承担一部分数据,合起来就能存下海量数据,扩容缩容很方便,如果想增加一个节点,只需要从现有每个节点上挪一部分抽屉(哈希槽)给新节点就行;想减少一个节点,就把它的抽屉全部分给其他节点,这个挪动抽屉的过程是由集群管理系统自动完成的,虽然会影响正在挪动的那部分数据,但不会导致整个集群不可用。

第二件大事:如何保证有人病倒也不停工?——谈谈高可用
团队不能因为一个人请假就散伙吧?Redis集群的高可用机制借鉴了“主从复制”和“故障自动转移”的思想(这种模式在分布式系统中很常见,如Redis官方文档所述)。
在集群里,每个主节点都不是孤军奋战的,它都配有一个或多个“跟班”,我们称之为从节点(Slave Node),从节点就像是主节点的备份,它通过复制技术,实时地、几乎一模一样地同步主节点上的所有数据。

平时,写操作只找主节点,读操作可以找主节点也可以找从节点(分担读压力),这时,从节点的主要任务就是“ standby”(待命),一旦主节点因为某种原因(比如机器宕机)失联了,它的从节点们就会立刻察觉到(集群节点之间通过一种叫“Gossip”的协议互相通信,就像团队成员之间时不时交头接耳一下,确认彼此都还健在),这时,其中一个从节点会挺身而出,经过内部投票选举,升级成为新的主节点,接管之前那个主节点负责的所有“小抽屉”(哈希槽)。
这个过程是自动的,所以对于使用Redis集群的应用程序来说,它可能只是瞬间感觉到了一次连接闪断,重连之后就能继续正常工作,几乎感知不到后台已经发生了“政权更替”,这就实现了高可用。
一些你必须要了解的“团队规矩”
了解了分片和高可用这两个核心,你还得知道这个团队的一些特殊工作方式,不然用起来会踩坑。
- 有些命令不能乱用:因为数据是分片存储的,所以那些需要同时操作多个键的命令,如果这些键恰好不在同一个节点上,就无法执行,比如你不能直接对跨节点的多个键进行集合的交集(
SINTER key1 key2)操作,除非这些key都有相同的哈希标签(后面会提),这是和单机Redis最大的不同之一。 - 客户端得聪明点:连接单机Redis,你告诉客户端一个地址就行,但连接集群,客户端需要更“聪明”,它需要先获取一份“抽屉分配地图”(槽位映射表),知道哪个键应该去找哪个节点,当客户端收到一个命令,比如要操作
user:1001,它会自己先算出这个键在5000号抽屉,然后根据地图直接连接5000号抽屉所在的那个主节点进行操作,这就叫“智能客户端”,如果客户端拿到的地图过时了(比如刚刚发生了故障转移),节点会告诉它“你找错了,这个键现在归那个谁管”,客户端会根据这个提示更新地图并重试,也有更简单的“代理模式”帮你处理这些事。 - 哈希标签——让一家人整整齐齐:我们就是希望某些相关的键能存放在同一个节点上,
user:1001:profile和user:1001:orders,这时就可以用哈希标签,你把这部分用括起来,比如键名写成user:{1001}:profile和user:{1001}:orders,集群在计算槽位时,只会计算内部内容的哈希值,这样这两个键就会被分配到同一个节点上,那些跨键的操作也就能执行了。
Redis集群就是一个通过哈希槽分片来解决数据容量问题,通过主从复制+故障自动转移来解决高可用问题的分布式系统,理解了这个“团队”的分工协作机制和它的特殊规矩,你就算真正搞明白Redis集群是咋回事了。
本文由帖慧艳于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/82209.html