MySQL数据库那些架构设计上的事儿,聊聊常见套路和实用技巧

说到MySQL数据库的架构设计,其实就跟盖房子差不多,你不能等到人住进去了,才发现墙是歪的或者房间不够用,才开始砸墙扩建,数据库也一样,一开始设计得好,后面能省心很多;如果设计得不好,那简直就是程序员的噩梦,天天忙着“救火”,下面就来聊聊这里面常见的一些套路和实用技巧。
第一,先说说表结构设计,这是基础。

- 套路:用自增ID做主键,但别迷信它。 几乎每个表都会有一个叫
id的字段,设置成AUTO_INCREMENT,让它自己增长,这招很简单,保证了每一行数据都有唯一标识,而且按顺序写入对性能有好处,但有时候也不能全靠它,比如订单表,你可能会想用“日期+随机数”自己生成一个订单号来做主键,这样业务上一眼就能看出些信息,一般情况下,用自增ID是稳妥的选择。(来源:常见的MySQL设计实践) - 技巧:学会优雅地“拆表”。 当一个表里的字段太多,比如用户表,既有登录名、密码这些经常要用的信息,又有个人简介、头像地址这些不常用的信息,你就可以考虑“垂直分表”,把常用的字段放在一个表里(比如
user_base),不常用的放在另一个表里(比如user_profile),两个表通过用户ID关联,这样查询常用信息时,速度会快很多,因为需要读取的数据块变小了,这就好比你把最常穿的衣服放在衣柜最外面,不常穿的收进储物箱,找起来就快了。(来源:数据库性能优化中的垂直分表概念) - 技巧:别让字段“太胖”,选择合适的类型。 比如存储状态 status,可能就几个值(0,1,2),用
TINYINT就足够了,别动不动就用INT,存储手机号、身份证号这种定长字符串,用CHAR比用VARCHAR可能更合适,因为存取效率更高,这就像打包行李,东西大小固定就用小盒子规整装好,东西大小不一再用软包,空间利用率才高。(来源:MySQL数据类型选择的最佳实践)
第二,再聊聊索引,这是数据库的“目录”。

- 套路:索引不是越多越好。 索引就像书前面的目录,能让你快速找到内容,但目录太多、太细,维护目录本身就要花时间,而且每增加一页内容,可能都要更新好几个目录,数据库也一样,索引会降低数据插入、更新和删除的速度,因为数据库不仅要改数据,还要改索引,只在经常用来做查询条件的字段上建索引。(来源:对索引副作用的基本认知)
- 技巧:联合索引要讲究“最左前缀”原则。 如果你经常按“城市”和“年龄”组合查询用户,那么建立一个(城市, 年龄)的联合索引就比单独为城市和年龄各建一个索引要高效,但要注意,这个联合索引就像是电话簿,先按姓排,同姓的再按名排,如果你只知道“名”(年龄),而不知道“姓”(城市),这个索引就基本上用不上了,所以字段的顺序很重要。(来源:MySQL联合索引的工作原理)
- 技巧:小心隐式转换导致索引失效。 比如你给手机号字段
phone(是VARCHAR类型)建了索引,但查询时写了WHERE phone = 13800138000(数字,没加引号),MySQL可能会进行类型转换,导致无法使用索引,变成全表扫描,写SQL时,类型一定要匹配。(来源:SQL编程中常见的索引失效场景)
第三,当数据量真的大起来后,就得考虑“分库分表”了。
- 套路:先垂直分,再水平分。 垂直分库就是把不同的业务表放到不同的数据库服务器上,比如用户相关的表一个库,订单相关的表一个库,这样减轻单台服务器的压力,当单个表的数据量太大(比如几千万行),查询慢得受不了时,就要水平分表了,也叫Sharding,就是把一个表的数据,按某种规则(比如用户ID取模、按时间范围)拆分成多个结构完全一样的表,分散到不同的数据库或服务器上。(来源:应对大数据量的常见架构演进路径)
- 技巧:分表键的选择是重中之重。 用来决定数据分配到哪张表的那个字段(比如用户ID)叫分表键,一定要选查询条件中最常用到的那个字段,这样才能保证大部分查询都能直接定位到某一张具体的表,避免扫描所有表,比如电商订单,大部分查询都是按用户查自己的订单,那用
user_id做分表键就很合适。(来源:分库分表策略设计的核心考量) - 技巧:承认跨库查询的复杂性,从业务上规避。 一旦分了库分表,原来一句简单的
JOIN查询可能就废了,因为数据分散在不同的机器上,这时候,通常的做法是“代码里拼凑”,比如先查到一个库里的数据,拿到ID列表,再去另一个库里查对应的数据,或者干脆不做关联,用空间换时间,把需要的数据冗余存储,这就要求在架构设计时,提前想好业务查询模式。(来源:分布式数据库环境下关联查询的挑战与解决方案)
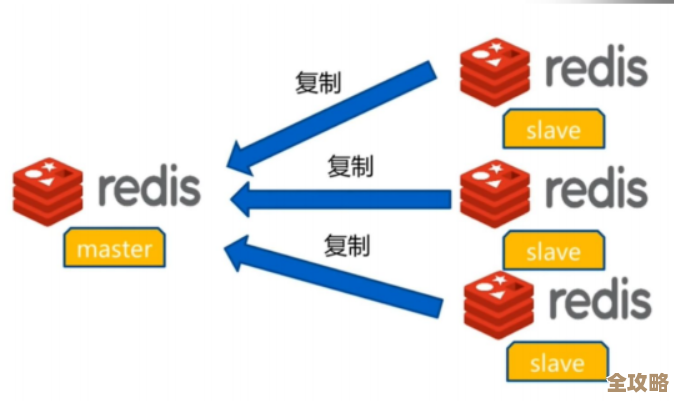
别忘了读写分离。
- 套路:一主多从,主库写,从库读。 这是非常普遍的套路,搞一个主库(Master),专门负责接收写操作(增、删、改),然后挂好几个从库(Slave),通过复制主库的日志来同步数据,这些从库专门负责处理读操作(查),这样就把读写的压力分开了,大大提升了系统的处理能力。(来源:缓解数据库读压力的经典架构模式)
- 技巧:注意主从延迟带来的“尴尬”。 数据从主库同步到从库有毫秒级的延迟,这就可能导致用户刚下单成功,马上查询订单却发现找不到,对于这种“写后立即读”的场景,有一种叫“强制走主库”的技巧,就是让这个特定的查询请求直接去主库读,牺牲一点性能保证数据立刻可见。(来源:读写分离架构中数据一致性问题的处理经验)
MySQL的架构设计就是一个不断权衡和取舍的过程:在读写性能、存储空间、开发复杂度、数据一致性之间做选择,没有一劳永逸的最优解,只有最适合当前业务场景的方案,最好的办法就是,前期多花点时间把基础打牢,同时预留出扩展的可能性,等业务真的发展到那一步时,才能平稳地演化。
本文由歧云亭于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75143.html