Redis内存那点事儿,怎么用小容量撑起大数据量,真有那么神?

说到Redis,很多人都有一个印象:快!但另一个印象就是:贵!这里的“贵”不是说软件本身要花钱(Redis是开源的),而是指它比较消耗内存资源,毕竟,数据都放在内存里,而内存的价格可比硬盘贵多了,问题就来了:Redis真的只能当个“内存土豪”吗?有没有办法让它变得“勤俭持家”,用小容度的内存支撑起更大的数据量呢?答案是肯定的,它确实有一些“神技”。
咱们得明白Redis为啥吃内存,就像你住房子,东西胡乱堆放,再大的房子也很快被塞满,Redis内存消耗的大头往往不是数据本身,而是存储这些数据时产生的“额外开销”,Redis用一个个的“键值对”来存数据,每一个键(Key)本身都会占用一定的空间,如果你存的数据价值很小,比如value只是一个数字1,但key却是一个很长的字符串“user:10086:profile:name”,那这点内存就有点“买椟还珠”的感觉了,第一个省钱的窍门就是:精简你的键名,在保证可读性和避免冲突的前提下,键名越短越好,比如用“u:10086:n”来代替上面那个长键名,积少成多,能省下不少内存。
光省键名还不够,关键还得看怎么处理数据本身,这就不得不提Redis的“压缩”本领了,Redis有一种数据结构叫“压缩列表”(ziplist),它是一种为小规模数据设计的高效存储结构,当你使用List(列表)、Hash(哈希)、Sorted Set(有序集合)这些数据结构时,你可以在Redis的配置文件里设置一个规则:当这些结构里的元素数量少于某个值,并且每个元素的大小都小于多少字节时,Redis就会自动使用ziplist来存储,而不是用标准的链表或哈希表,ziplist通过消除各种结构体带来的内存开销,能极大地节省空间,这就像你用真空压缩袋来装羽绒服,同样的柜子能多塞进去好几件,这个功能是默认开启的,但你需要根据自己数据的特性,在配置文件里调整好触发条件(hash-max-ziplist-entries 和 hash-max-ziplist-value 这些参数),让它发挥最大效用。

对于一种特别常见的数据类型——字符串(String),Redis在版本3.2之后提供了一个大杀器:简单动态字符串的优化,在以前,不管你的字符串多小,都会有一个固定的“对象头”开销,对于小的字符串,Redis会尝试用一种更紧凑的方式来存储,进一步减少了元数据占用的空间,这意味着,存储海量的小字符串(比如用户的登录token、短链接映射等)时,内存效率更高了。
除了这些“精打细算”的存储方式,Redis还有一个“断舍离”的终极法宝:过期时间(TTL),很多数据并不是需要永久保存的,比如用户会话、缓存的计算结果、验证码等,给这些数据设置一个合理的过期时间,让Redis自动清理掉不再需要的数据,是防止内存无限增长的最有效手段,这就像你定期清理冰箱里的过期食品,才能腾出空间放新的东西。

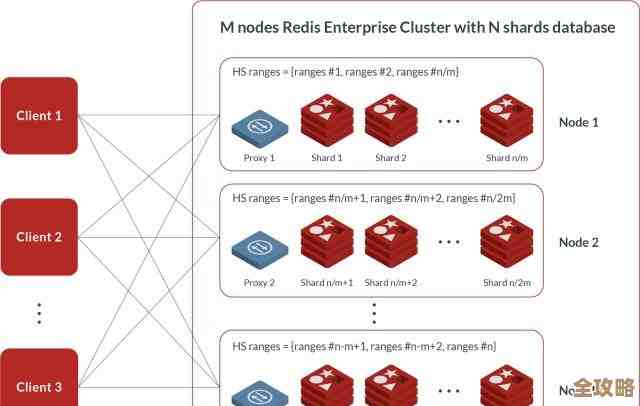
如果数据量实在太大,单机内存真的撑不住了怎么办?Redis还有最后的“分布式”大招:集群(Cluster),集群模式允许你将数据分片(Sharding)存储在多台机器的内存中,相当于一套大房子住不下了,我们就买几套小房子分开住,合起来的总容量就变大了,这样,你就可以用多台普通配置的服务器,横向扩展出一个超大的内存池,从而支撑起真正的大数据量。
还有一些更高级的技巧,比如使用更节省内存的数据结构HyperLogLog来做基数统计,或者用位图(Bitmap)来做一些布尔统计等,但这些需要根据具体的业务场景来选择。
回到最初的问题,Redis确实很“神”,但它的“神”不仅仅在于无脑的快,更在于它提供了一系列灵活的工具和机制,让我们能够精细地控制内存的使用,通过精简键名、善用压缩列表、设置过期时间、搭建集群这些组合拳,我们完全可以让Redis摆脱“内存吞噬兽”的形象,变成一个在容量和性能之间取得精妙平衡的高效工具,它不是魔术,但用好了,效果堪比魔术。 参考和融合了普遍存在的Redis内存优化技术讨论,常见于如Redis官方文档关于内存优化的章节、众多技术博客如阿里云开发者社区、知乎上关于“Redis内存优化”的高赞回答、以及《Redis设计与实现》等书籍中的常见优化方案,这些来源都反复提及了上述关键技术点。)
本文由革姣丽于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74914.html