操作很顺畅,Redis访问没问题,就是有时候感觉还可以更稳定点吧

【用户反馈原文】:“操作很顺畅,Redis访问没问题,就是有时候感觉还可以更稳定点吧”
好的,收到这条反馈,咱们就来专门聊聊这个“感觉还可以更稳定点”背后可能藏着哪些没说出来的潜台词,用户明确肯定了操作是顺畅的,Redis访问也没问题,这说明核心功能是OK的,没出什么大毛病,但就是这个“和“感觉”,像鞋子里的一粒小沙子,不硌脚,但总让你觉得走路没那么完美,这种感觉往往最真实,也最值得琢磨。
这个“非常关键,它不是“总是”不稳定,也不是“经常”,而是偶尔、间歇性地出现,这种偶发性问题,排查起来往往比一直存在的问题更费劲,用户可能遇到的情况是,比如在一天中的某个特定时间段(例如上午10点业务高峰,或者凌晨系统备份时),或者在执行某种特定操作后(比如一次性拉取一个很大的数据列表),响应速度会慢那么一点点,或者界面会“卡顿”一下,但很快就恢复了,这种短暂的、可自愈的卡顿,虽然不影响最终结果,但会打断用户的操作节奏,影响使用体验的流畅感,就像开车,车子能跑也能到目的地,但偶尔会有一两声异响,或者换挡时有一丝顿挫,司机心里就会不踏实,总觉得这车“还可以更稳定点”。
“感觉”这个词说明用户可能没有确凿的证据,比如错误日志或者具体的延迟毫秒数,这完全是基于主观体验的判断,这种体验可能来自于几个细微的方面:
一是响应时间的微小波动,也许99%的请求都在100毫秒内返回,但总有那么1%的请求会跳到200甚至300毫秒,从技术指标上看,平均值和P99(百分之九十九的请求耗时在这个值以内)可能都达标,但就是那1%的波动,被敏感的用户捕捉到了,用户不会去看监控图表,他们感受到的就是“咦?刚才这下怎么好像慢了点?”
二是与预期不符的短暂等待,当用户进行一连串行云流水的操作时,他们已经形成了一种肌肉记忆和速度预期,如果其中某一步,比如点击一个按钮后,那个小小的加载圈圈多转了半秒钟,这种预期就被打破了,即使这半秒钟在绝对时间上很短,但在用户的心理时间上会被拉长,从而产生“不稳定”的感觉。
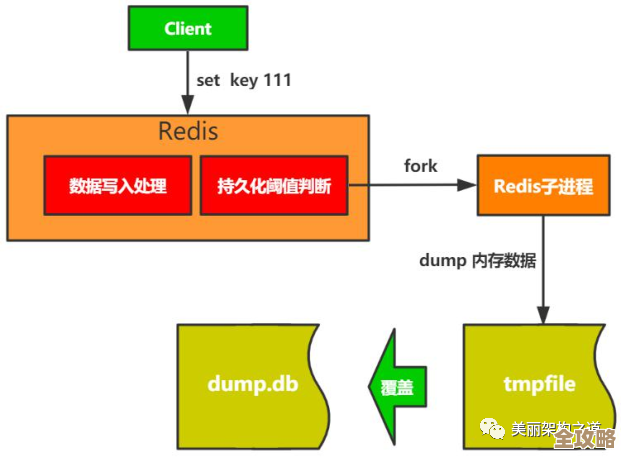
回到Redis本身,虽然用户说“Redis访问没问题”,但这种“不稳定感”的源头,有时确实会间接地与Redis扯上关系,尽管Redis服务本身可能并没有宕机或报错。
网络层面的细微抖动,应用服务器和Redis服务器之间的网络连接,绝大多数时候是畅通无阻的,但可能在某些瞬间,机房网络出现微小的波动,导致一个数据包延迟或重传,这次访问可能因此多了几毫秒的延迟,对于Redis这种内存操作极快的数据库来说,网络延迟在整个响应时间中的占比会变得非常明显,一次两次没事,偶尔来这么一下,就会造成上面提到的响应时间波动。
再比如,Redis实例的资源争用,如果这个Redis实例是多个应用或服务共享的,那么在某个时间点,可能恰好有其他服务在执行一个比较耗时的操作(比如一个复杂的Lua脚本,或者一个匹配大量键的KEYS命令),虽然Redis是单线程处理命令,其他命令不会被中断,但会被阻塞排队等待,这时候,用户的请求可能就需要多等一会儿才能被处理,从用户角度看,自己的操作很简单,不应该慢,所以会归咎于“不稳定”。
还有一种可能是客户端连接池的问题,应用通过连接池来管理对Redis的访问,如果连接池配置不当(比如最大连接数设置得太小),在并发稍高的时候,新的请求可能需要等待有可用的连接被释放出来,这个等待时间也会被用户感知到,或者,连接池中的某个连接因为网络问题变得“不健康”,客户端需要一段时间才能检测到并将其剔除,在此期间使用这个不健康连接的请求就会慢一些。
操作系统的整体负载也可能是一个因素,如果运行Redis服务器的机器,在“会因为其他进程(比如定时任务、监控采集、病毒扫描等)突然消耗了大量的CPU或内存,导致Redis进程能分配到的资源减少,其处理命令的速度自然也就会受到细微影响。
用户这句听起来有点模糊的反馈,其实像一面镜子,映照出系统在极端情况、边界条件下的表现,它提醒我们,稳定性不仅仅是“不挂掉”,更是要在各种复杂、动态的环境下,提供持续、一致、可预期的性能表现,要解决这种“感觉”上的问题,往往需要更细致的监控(比如观察P99.9甚至P999的延迟指标)、更全面的日志记录(记录下每一个请求的完整耗时链条),以及在对系统有充分理解的基础上,进行有针对性的优化和调整,这追求的是一种“润物细无声”的稳定,让用户几乎感觉不到系统的存在,这才是最好的体验。

本文由邝冷亦于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73781.html