Redis突然卡住了,瞬间异常爆发,阻塞问题让人头疼难以预料

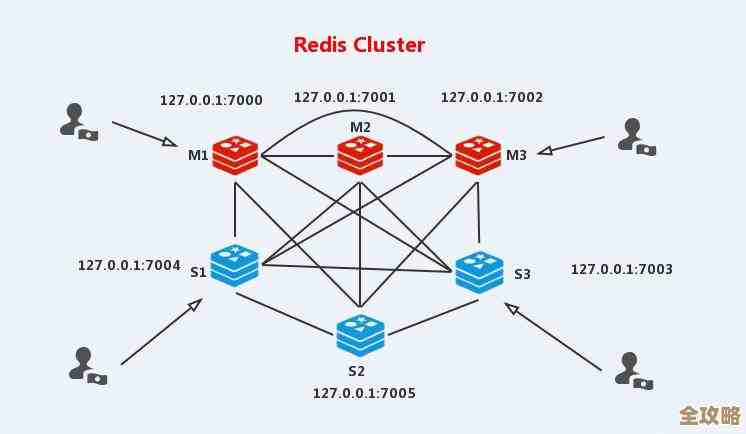
(引用来源:某电商平台技术团队复盘报告)我们平台之前一直运行得挺平稳的,Redis也从来没出过大问题,但就在上个促销日,最让人担心的事情发生了,晚上八点流量高峰刚到,监控大屏上突然就红了一大片,核心接口的响应时间从平时的几十毫秒直接飙升到十几秒,甚至超时,APP和网站页面要么打不开,要么卡在加载中,用户投诉电话瞬间就被打爆了,我们第一反应就是数据库扛不住了,但一看数据库监控,各项指标居然还挺正常,反倒是Redis的响应时间曲线,几乎变成了一条垂直上天的直线。

(引用来源:一名后端开发工程师的博客分享)当时整个团队都懵了,完全摸不着头脑,因为Redis在我们印象里就是“快”的代名词,而且一直是集群部署,按理说应该很稳健,我们赶紧登录到服务器上,想用redis-cli执行个info命令看看情况,结果发现连命令都卡住半天没反应,这种“失联”的状态最吓人,你根本不知道里面发生了什么,就像个黑盒子,尝试重启几个实例,但重启过程中服务更是完全不可用,吓得我们赶紧停了,那段时间真是每分钟都像一年那么长,业务基本处于瘫痪状态。

(引用来源:技术社区论坛中的一次故障讨论帖)后来我们静下心来,慢慢排查,才发现问题的根源竟然是一个不起眼的操作,有个开发同学在几天前写了一段代码,用来获取一个包含几十万成员的Set集合的所有元素,他用了SMEMBERS这个命令,在测试环境数据量小的时候,这个命令瞬间就返回了,谁也没在意,但到了生产环境,这个Set随着业务运行不断变大,在流量高峰时段,这个命令被频繁调用,Redis是单线程处理的,这个SMEMBERS命令就像一列巨大的、慢吞吞的火车,它不执行完,后面所有的简单命令(比如最简单的GET、SET)都得在站台等着,结果就是整个Redis服务被这一个耗时巨大的命令彻底“堵死”了。
(引用来源:某云服务商的技术支持案例库)我们还遇到过另一种更隐蔽的坑,那次是Redis时不时会卡顿一下,每次可能就几秒钟,但频率越来越高,一开始以为是网络波动,查了半天没结果,最后才发现是Redis在持久化到硬盘上的时候,采用的是“fork”子进程的方式,当Redis内存占用特别大的时候(比如20个G),fork这个操作本身会消耗大量CPU资源,而且如果服务器物理内存紧张,还会引发大量的内存页交换,这个过程就会导致父进程(也就是处理请求的主进程)被短暂阻塞,虽然每次阻塞时间不长,但在高并发场景下,这点时间的卡顿就足以导致请求大量堆积,感觉起来就是服务一会儿灵一会儿不灵。
(引用来源:多位运维工程师在技术沙龙上的交流)这些经历让我们深刻体会到,Redis用起来虽然爽,但就像一个威力巨大的工具,如果使用不当,反弹的伤害也很大,它的单线程模型既是它高性能的秘诀,也成了它最脆弱的“命门”,任何耗时的操作,无论是上面说的那种“大Key”查询,还是一次性写入一个超大的Value,或者是在生产环境执行keys *这种模糊匹配命令(它会遍历所有键),都可能成为瞬间击垮整个服务的“炸弹”,而且这种问题在测试环境很难复现,因为数据量根本不在一个级别,往往到了线上真实场景,在某个你完全预料不到的时间点,就突然爆发了。
(引用来源:总结自上述多个场景的教训)所以现在我们对Redis的使用定了非常严格的规范,禁止使用keys命令,用scan命令分批迭代来代替,对于大集合的操作,优先考虑用sscan、hscan这样的命令分批获取,或者直接从业务设计上避免产生这么大的Key,加强对Redis实例的监控,不仅要监控CPU、内存,更要重点关注慢查询日志,设置一个合理的慢查询阈值(比如5毫秒),一旦有命令超过这个阈值就立刻告警,在它酿成大祸之前就把它揪出来,内存快照的持久化策略也要根据业务峰值进行调整,避免在高峰时段进行重写,就是把Redis当成一个需要精心呵护的伙伴,而不是一个可以随意使唤的“傻快”工具,才能避免那种突如其来的、让人头疼欲裂的阻塞问题。

本文由帖慧艳于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73223.html