Redis面试题汇总练习,帮你快速掌握重点和难点内容

Redis到底是什么?它能做什么?
来源:几乎所有面试题开篇都会问这个问题,Redis全称是Remote Dictionary Server,远程字典服务,你可以把它理解成一个速度非常快、但数据主要存在内存中的“超级数据库”,它支持多种数据结构,比如字符串、列表、哈希、集合等,因为它读写都在内存里,所以速度比读写硬盘的数据库(如MySQL)快得多,主要用途是:作为缓存(最常用),降低后端数据库的压力;也可以做简单的消息队列;存储会话(Session);实现计数器、排行榜等功能。
Redis支持哪些数据类型?你最熟悉哪一种?
来源:这是最基础也是最常问的问题,Redis不是只存简单的字符串,它支持五种核心数据结构:
- String(字符串):最基本类型,可以存文本、数字甚至图片二进制数据。
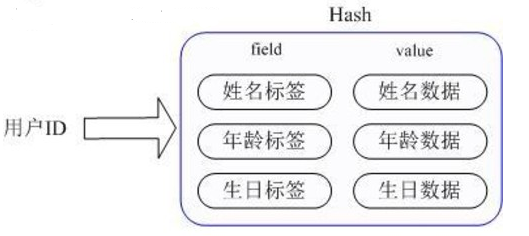
- Hash(哈希):类似于Java里的Map或Python的字典,适合存储对象(比如一个用户的姓名、年龄、性别等信息)。
- List(列表):一个有序的字符串列表,可以从两头插入或弹出元素,可以做消息队列或时间线。
- Set(集合):无序且元素唯一的集合,可以用来存标签、共同好友等。
- Sorted Set(有序集合):和Set类似,但每个元素都关联一个分数(score),可以根据分数排序,完美适用于排行榜。
面试官可能会追问你每种数据类型的应用场景,以及你项目中具体是怎么用的,用String做缓存;用Hash存用户信息;用Sorted Set做游戏排行榜。
为什么Redis这么快?

来源:这个问题几乎必问,用来考察你对Redis底层原理的理解,主要原因有几点:
- 基于内存:数据存在内存中,读写操作不受硬盘I/O速度的限制。
- 单线程模型:Redis的核心网络模型是单线程的(新版本引入了多线程处理其他任务,但核心命令处理仍是单线程),这避免了多线程的上下文切换和竞争条件带来的开销,非常高效,很多人误以为单线程是缺点,其实在内存操作下,这反而是保证原子性和高性能的关键。
- 高效的数据结构:Redis自己实现了一套像“跳跃表”、“压缩列表”这样的数据结构,非常节省内存且高效。
- I/O多路复用:使用epoll这样的机制,让单个线程能高效处理大量的网络连接请求。
什么是缓存穿透、缓存击穿、缓存雪崩?怎么解决?
来源:这是Redis应用中的经典问题,考察解决实际问题的能力。
- 缓存穿透:指的是查询一个根本不存在的数据,这个数据在缓存和数据库中都没有,每次请求都会直接打到数据库上,失去了缓存的意义。解决方案:对不存在的key也缓存一个空值(并设置较短的过期时间);使用布隆过滤器(Bloom Filter)在查询前先做一层过滤。
- 缓存击穿:指的是一个非常热点的key在过期瞬间,大量请求同时涌来,导致所有请求都落到数据库上,就像在缓存上击穿了一个洞。解决方案:设置热点数据永不过期;或者使用互斥锁(mutex),只让一个请求去数据库加载数据,其他请求等待。
- 缓存雪崩:指的是缓存中大量的key在同一时间过期,或者Redis服务宕机,导致所有请求都落到数据库,造成数据库压力巨大甚至崩溃。解决方案:给不同的key设置随机的过期时间,避免同时失效;如果是Redis宕机,需要考虑搭建高可用架构,比如Redis主从复制或集群。
Redis如何实现持久化?RDB和AOF有什么区别?
来源:因为Redis数据在内存,重启会丢失,所以持久化是保证数据安全的关键。

- RDB(快照):在指定的时间间隔内,将内存中的数据生成一个快照文件(dump.rdb)保存到硬盘。优点:文件紧凑,恢复大数据集速度很快。缺点:可能会丢失最后一次快照之后的数据(比如5分钟持久化一次,服务器宕机就会丢失5分钟数据)。
- AOF(追加日志):记录每一次写操作命令,以日志的形式追加到文件末尾,当Redis重启时,会重新执行AOF文件中的所有命令来恢复数据。优点:数据安全性高,最多丢失一秒的数据(如果配置为每秒同步一次)。缺点:AOF文件通常比RDB文件大,恢复速度慢。
生产环境中通常两者结合使用,用AOF来保证数据不丢失,用RDB来做冷备。
怎么保证Redis里的数据是和数据库(如MySQL)里的一致?
来源:这是使用缓存时必然会遇到的难题,当更新了数据库的数据后,如何同步更新缓存? 常见的策略有几种:
- 先更新数据库,再删除缓存:这是比较常用的策略,先更新数据库,成功后,使缓存失效(删除对应的key),下次查询时,发现缓存没有,再从数据库加载,这种策略出现不一致的概率较低。
- 先删除缓存,再更新数据库:这种策略下,在更新数据库的间隙,可能会有其他请求把旧数据又加载到缓存里,导致脏数据,可以通过“延迟双删”等策略来缓解。 这个问题没有完美的银弹,面试官主要想考察你对数据一致性复杂性的认识,以及根据业务场景权衡的能力。
Redis是单线程的,如何理解它的高并发能力?
来源:常作为对“为什么快”这个问题的深入追问,需要澄清一个概念:Redis的“单线程”指的是执行命令的模块是单线程的,但像持久化、网络I/O等操作是由其他线程或子进程处理的,它的高并发能力正源于此:单线程避免了锁的开销,同时通过非阻塞I/O多路复用来处理海量的网络连接,CPU不是瓶颈,内存速度和网络带宽才是,所以它能轻松处理数万的并发连接。

有没有用过Redis的分布式锁?怎么实现的?
来源:在分布式系统中,控制多个服务对共享资源的访问是一个常见需求,Redis可以通过SET key value NX PX milliseconds这个命令来实现一个简单的分布式锁。
NX表示只有当key不存在时才能设置成功。PX设置一个过期时间,防止锁的持有者挂掉导致锁永远无法释放。 但这里有很多细节要注意,比如设置一个唯一的值作为value,防止误删其他客户端的锁;以及如何安全地释放锁(使用Lua脚本保证原子性),更复杂的场景可能会用到Redlock算法。
Redis的内存用完了会怎么样?
来源:考察对Redis配置和内存管理的了解,这取决于maxmemory-policy这个配置项,默认是noeviction,即内存满后,新写入操作会报错,其他策略包括:
allkeys-lru:尝试回收最近最少使用的键。volatile-lru:只从设置了过期时间的键中回收最近最少使用的键。allkeys-random:随机删除键。 需要根据业务特点选择合适的淘汰策略。
如何设计一个合理的Redis键名(Key)?
来源:看似简单,但能体现项目经验,好的键名设计要具备可读性、可管理性和高效性,一般会采用类似“业务名:对象名:唯一标识[:字段]”的模式,比如user:1001:info,order:20231001:status,避免使用过长的键名(浪费内存),也避免使用特殊字符,要考虑键的过期时间设置,避免无用的key长期占用内存。
本文由召安青于2026-01-02发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73222.html