Redis过期问题终于有新办法了,解决那些烦人的数据失效场景难题

(引用来源:阿里云开发者公众号文章《Redis过期问题终于有新办法了,解决那些烦人的数据失效场景难题》)
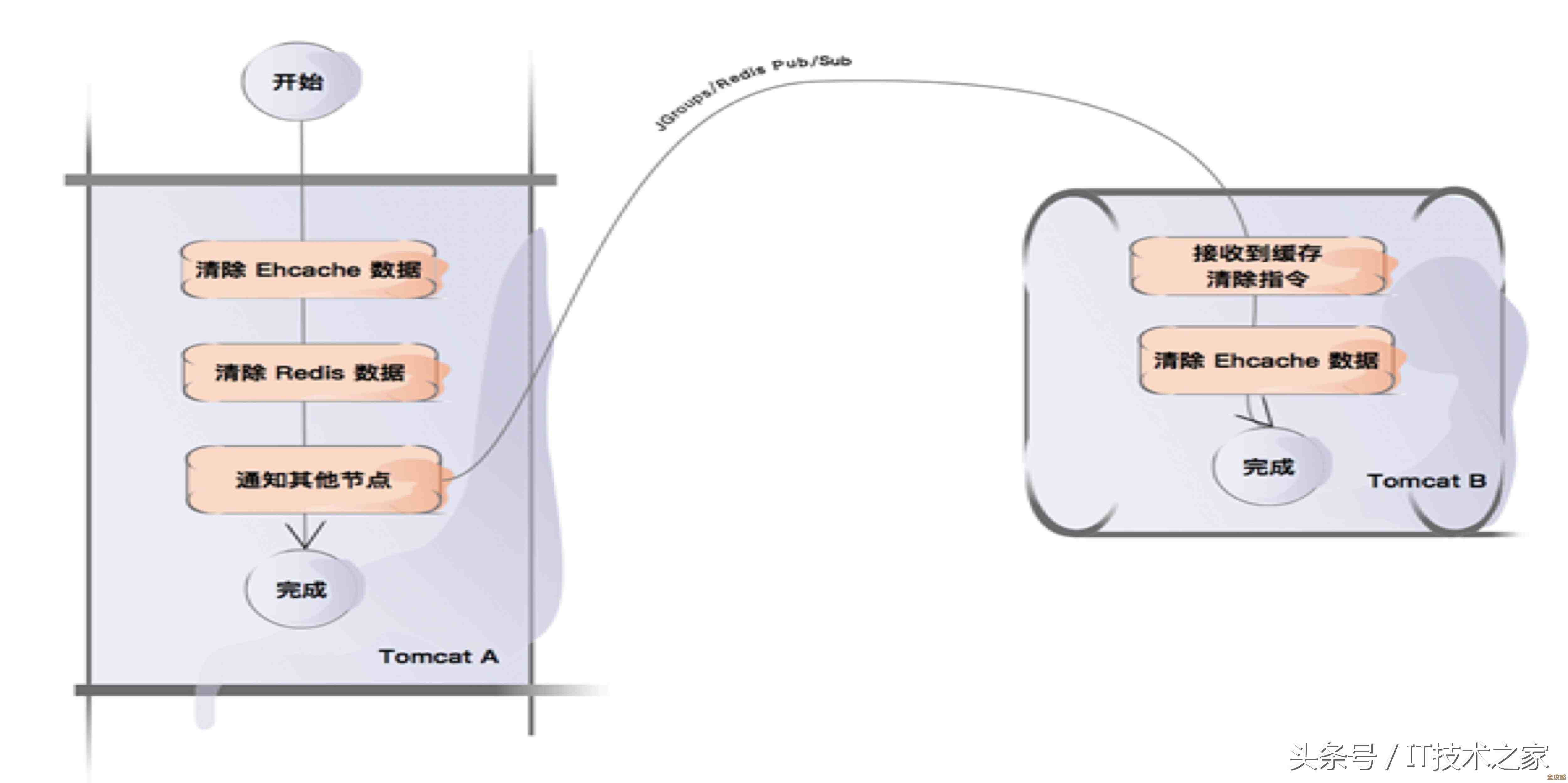
Redis这个工具,我们很多人都在用,主要就是拿它来当缓存,因为它速度特别快,但用过的人肯定都遇到过一些头疼的问题,尤其是关于数据过期删除的,我们经常设定了数据的存活时间,想着到时候它自己就没了,挺省心的,但实际情况往往没那么简单,有时候数据该失效没失效,有时候又失效得太突然,搞得系统直出问题。
这篇文章里提到的新办法,其实是从一个我们可能没太注意的底层机制入手,提出了一些新的思路和用法,来对付这些烦人的场景,它不是说要推翻Redis原来的过期策略,而是在理解和利用这个策略的基础上,变得更聪明。
先说说最经典的第一个难题:缓存雪崩,这名字听起来吓人,其实意思就是,如果在某个时间点,大量缓存数据集体失效了,就像大坝决堤一样,所有的请求一下子都涌向了后面的数据库,数据库根本扛不住这么大的压力,可能直接就瘫痪了,整个服务也跟着挂掉,以前我们想了不少办法,比如给不同的数据设置不同的、稍微随机一点的过期时间,避免它们同时失效,但这需要提前规划,而且有时候防不胜防。
文章里提到的新思路是什么呢?它建议我们可以利用Redis的一个特性,就是它删除过期键的两种主要方式:一种叫“惰性删除”,就是只有当有人来查询这个键的时候,Redis才发现它过期了,然后顺手把它删掉;另一种叫“定期删除”,Redis会隔一段时间抽检一部分键,把里面过期的清理掉,这个新办法更强调主动出击,而不是被动等待,我们可以有意识地不让大量数据在同一秒到期,而是让它们的过期时间均匀分布在一个时间段里,更进一步,甚至可以有一个后台任务,在缓存快要大面积失效之前,偷偷地去提前重新加载一部分热点数据,相当于给缓存“续命”,这样就能平滑地过渡,不会让数据库瞬间压力山大。
第二个让人郁闷的问题是:缓存穿透,这指的是,有人(可能是恶意攻击者)一直在查询一个根本不存在的数据,因为数据不存在,所以Redis里肯定没有,每次查询都会直接打到数据库上,如果这种请求非常多,数据库就惨了,要不停地空跑查询,浪费资源,还可能拖慢正常服务。
对付这个问题,常见的做法是把这个不存在的Key也缓存起来,设一个短的过期时间,比如几分钟,这样短时间内同样的无效请求过来,Redis就能直接返回空结果,保护了数据库,但这个办法有个小缺点,就是如果攻击者用海量的、不同的、根本不存在的Key来请求,你缓存也缓存不过来。
文章中提到的新视角是,可以结合使用布隆过滤器这种数据结构,在查询Redis之前,先让请求经过布隆过滤器这一关,布隆过滤器可以非常高效地判断一个元素“一定不存在”或者“可能存在”于某个集合里,我们可以把系统中所有存在的Key都放到布隆过滤器里,当一个查询请求过来,先问布隆过滤器这个Key是否存在,如果布隆过滤器说“一定不存在”,那就不用再去查Redis和数据库了,直接返回空结果,这样就彻底把无效请求挡在了门外,极大地减轻了压力,虽然布隆过滤器有极小的误判率(即可能把存在的Key误判为不存在),但在缓存穿透这个场景下,这个小小的代价是完全值得的。
第三个棘手的情况是:热点数据失效,想象一下,某个明星突然爆出大新闻,他相关的商品信息或者微博数据就成了热点,被千万人同时访问,如果这个时候,保存这个热点数据的缓存恰好到期失效了,会发生什么?瞬间就会有海量的请求同时发现缓存没了,然后它们会齐刷刷地冲向数据库,去重新加载数据,这个瞬间的并发压力非常恐怖,很可能直接把数据库打垮,即使缓存很快被重建,但这一瞬间的崩溃已经足以导致服务不可用。
针对这个,文章介绍了一种更精细的控制策略,核心思想是使用分布式锁机制来保证只有一个请求线程能去数据库加载数据,具体怎么做呢?当多个请求同时发现某个热点Key失效时,不要让它们都去查数据库,而是让这些请求先去尝试获取一个与这个Key相关的锁,谁抢到了这个锁,谁就负责执行从数据库加载数据并回填到缓存的任务,而其他没抢到锁的请求怎么办呢?它们不是傻等着,也不是直接去查数据库,而是可以短暂地休眠一下,比如几毫秒,然后重新去缓存里查询,因为很可能就在这短短的几毫秒内,那个抢到锁的幸运请求已经成功把数据加载到缓存里了,这样,绝大部分请求最终都能从缓存中得到数据,只有第一个请求真正访问了数据库,完美地避免了惊群效应,这种做法对代码有一些要求,但确实是解决热点并发失效的利器。
文章还提到了一种场景,就是业务上需要非常精确的过期控制,比如搞秒杀活动,库存缓存必须在准点失效,不能有一丝一毫的延迟,或者是一些金融交易场景,对时间的准确性要求极高,Redis自身的过期删除因为是后台任务,或多或少会有一点延迟,不是完全精确到秒的。
对于这种需求,新办法是采用“业务层主动删除”结合“过期时间”的双重保障,也就是说,我们依然给数据设置上Redis的过期时间,作为一种兜底的清理机制,但同时,在业务逻辑代码里,当判断条件满足时(比如秒杀时间一到),我们主动地、显式地去调用Redis的删除命令,立即移除这个Key,这样,业务上的精确性由我们自己的代码保证,而万一代码有遗漏,Redis的过期机制还能在后面帮忙清理,避免了脏数据一直残留,这种主动出击的方式,把控制的主动权拿回到了开发人员手中。
这篇文章的核心思想就是,面对Redis过期带来的各种难题,我们不能光是依赖Redis的默认行为,而是要更深入地理解其内部机制,然后结合一些巧妙的设计模式、额外的工具(如布隆过滤器、分布式锁)以及业务逻辑上的主动干预,形成一个更立体、更健壮的防护体系,这样一来,那些曾经让人心烦的数据失效场景,就不再是那么可怕的难题了。

本文由黎家于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/71121.html