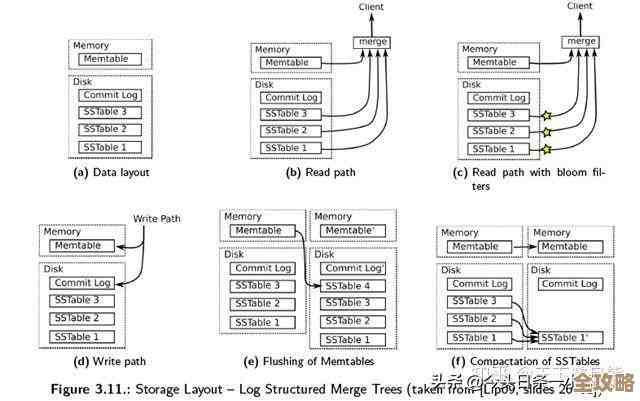
Redis运维那些事儿,框架搭建和实操经验聊聊

主要参考自多位资深运维工程师的社区分享、技术博客以及《Redis设计与实现》一书中的运维相关章节)
说起Redis运维,很多刚开始接触的人可能觉得就是启动一下服务,改改配置,但真要在生产环境里把Redis用得稳如老狗,里头的事儿可就多了,我今天就想到哪儿说到哪儿,聊聊搭建和实操中那些容易踩坑的地方。
第一部分:框架怎么搭?别一上来就蛮干

你得想清楚用Redis来干啥,是纯粹做缓存,还是当数据库用?这个选择直接决定了你的搭建策略,如果只是缓存,数据丢了可能还能从数据库再拉一次,配置可以奔放一点;要是当数据库使,那持久化、数据安全就是天大的事,容不得半点马虎。
(参考多位工程师的共识)单机Redis最简单,但绝对是生产环境的大忌,除非是测试或者小的不能再小的项目,否则一定要搭集群,主从复制(Master-Slave)是最基础的保障,弄一个主节点负责写,挂几个从节点负责读和备份,这样好处多:一来读写分离能减轻主节点压力,二来主节点万一挂了,还能快速切到一个从节点顶上,不至于服务全挂。
哨兵(Sentinel)这套东西,可以说是主从模式的“管家”,光有主从还不够,因为主节点挂了需要人手动去切换,这中间服务可就中断了,哨兵就是干自动监控和切换这活儿的,一般哨兵也得搭个奇数个,比如3个,它们自己会开会投票,决定主节点是不是真挂了,然后集体选举出一个新的主节点,搭建的时候,哨兵的配置文件里一定要把它同伴的地址都写对喽,不然它们找不到对方,这会就开不成了。

更复杂或者数据量巨大的,就得用Redis Cluster了,它把数据分片存储在多个节点上,能水平扩展,但Cluster搭建和维护起来也更麻烦,比如扩容缩容的时候得小心处理数据迁移。
第二部分:实操里的坑,一个个都是教训
-
内存是关键:Redis是内存数据库,内存用完了可就真完了,运维的眼睛得时刻盯着内存使用率。(参考某电商运维案例)光看总使用量还不够,得看看有没有那种单个特别大的Key(我们叫它“大Key”),比如一个List里塞了几十万条数据,这种大Key不仅占地方,操作起来还特别慢,容易把整个实例拖垮,还有“热Key”,就是某个Key被疯狂访问,所有请求都打到一个节点上,也可能导致瓶颈,定期用
redis-cli --bigkeys扫一扫,或者用监控工具分析一下访问模式,很有必要。
-
持久化配置是门艺术:RDB是快照,AOF记的是操作日志,很多人纠结用哪个,稳妥的做法是两个都开,RDB用来做定期的完整备份,恢复起来快,AOF用来保证数据安全性,就算服务器突然宕机,最多也就损失一秒的数据(如果配置为每秒同步一次),但AOF文件会越来越大,所以要配置自动重写机制,压缩日志,这里有个坑:重写的时候如果数据量巨大,会非常耗CPU和内存,最好选在业务低峰期自动触发。
-
慢查询日志不能关:Redis有个慢查询日志功能,默认超过10毫秒的操作都会记下来,你可别小看这10毫秒,对于内存操作来说这已经算很慢了,定期检查慢查询日志,能帮你发现哪些命令效率低,是不是用了
KEYS *这种全库扫描的“自杀式”命令,或者有没有复杂的Lua脚本执行太久了,发现问题命令就得优化,比如用SCAN代替KEYS。 -
网络和安全不能忘:别把Redis服务暴露在公网上!这是血泪教训,最好绑定在内网IP上,如果客户端和Redis不在同一台机器,网络延迟会直接影响Redis的响应时间,还有,给Redis设个复杂点的密码,虽然性能有一丁点影响,但安全第一啊。
-
监控和告警是生命线:没有监控的Redis就是在裸奔,起码要监控这几样:内存使用率、连接数、每秒操作数(QPS)、延迟时间(Latency),一旦这些指标有异常,比如内存突然暴涨、延迟升高,告警系统要能立刻通知到你,这样你才能在问题变成事故之前介入处理。
Redis运维就是个细活儿,需要持续的关注和优化,搭建好框架只是第一步,后期的监控、调优、排障才是真正的挑战,多看看别人的经验,自己多动手实践,慢慢就能摸出门道了。
本文由度秀梅于2025-12-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/66994.html