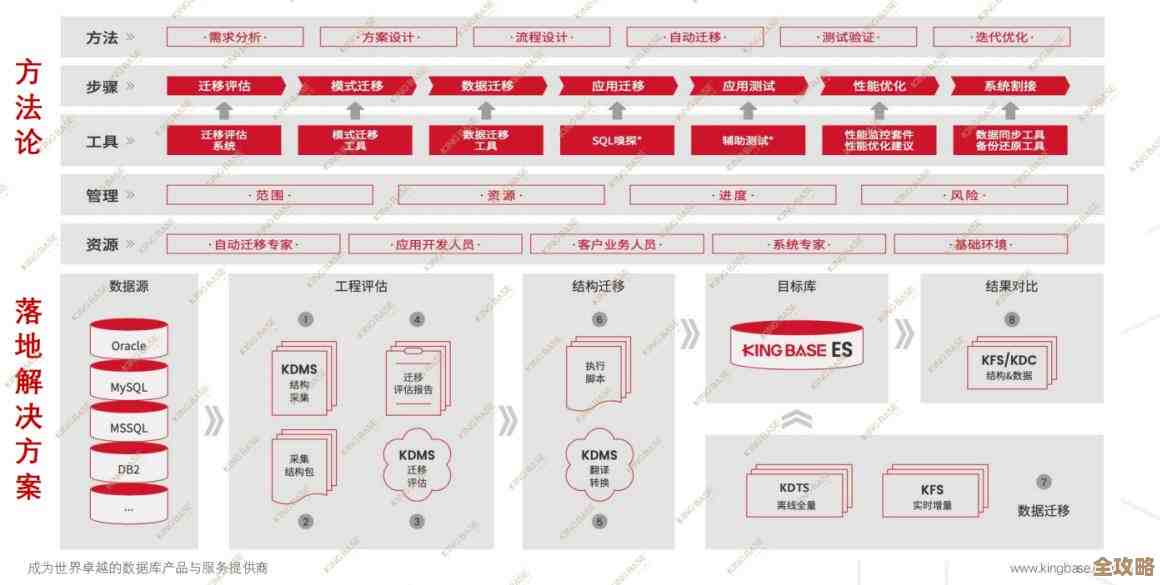
数据库性能提升那些事儿,先从索引的秘密开始慢慢说起

开始)
说到数据库性能提升,这确实是个让很多开发者和运维人员头疼又不得不面对的大话题,就像一家杂乱无章的图书馆,书多得数不清,但你要找一本特定的书时,如果没有任何目录和编号系统,你就得从第一个书架开始一本一本地翻,那效率可想而知,数据库也是一样,当里面的数据量越来越大,查询速度就会越来越慢,而解决这个问题最直接、也最有效的方法之一,就是用好索引,我们就从索引这个“秘密武器”开始慢慢聊。
索引到底是什么呢?我们可以用一个非常生活化的例子来理解,想象一下一本厚厚的字典,里面收录了成千上万个汉字,如果没有前面的拼音检索表或者部首检字表,你要找一个“数据库”的“库”字,是不是得从第一页开始,一页一页地往后翻?这简直就是大海捞针,但有了拼音检索表就完全不一样了,你知道“库”字的拼音是“ku”,然后你直接翻到“K”开头的部分,很快就能定位到“ku”这个音节,然后在下面找到“库”字以及它所在的页码,这个过程,数据库索引起的作用就跟这个拼音检索表一模一样。
在数据库里,索引就是一种特殊的“目录”,它保存了表中某一列或几列的值,以及这些值对应数据在磁盘上的实际位置(就像字典里的页码),当你执行一条查询语句,查找所有姓‘张’的员工”时,姓名”这一列上没有索引,数据库就得进行所谓的“全表扫描”,也就是把整个员工表从头到尾读一遍,检查每一行记录的姓名是不是“张”,数据量小的时候可能感觉不到,但如果有几百万甚至上千万条记录,这个查询就会慢得像蜗牛爬。
但如果你在“姓名”列上创建了索引,情况就大不相同了,数据库会先去这个“姓名索引”里查找“张”这个值,因为索引里的数据通常是经过排序的(比如按字母顺序),所以查找速度非常快,就像你查字典一样,找到“张”之后,索引会立刻告诉你所有姓“张”的员工记录存放在磁盘的哪些位置,数据库就可以直接“精准定位”到这些记录,大大减少了需要读取的数据量,速度自然就提上来了,这个原理在Oracle的官方文档和微软关于SQL Server的技术文章中都有核心阐述,即索引通过减少查询需要扫描的数据量来提升性能。
索引也不是越多越好,它就像一把双刃剑,虽然读数据(查询)变快了,但写数据(增加、修改、删除)就会变慢,为什么呢?因为每次你往表里插入一条新记录,或者修改、删除一条现有记录时,数据库不仅要更新表本身的数据,还要去更新所有相关的索引,以保证索引的准确性,这就好比你在字典里新加一个字,你不仅要把这个字写进正文,还得在拼音检索表和部首检字表里都加上这个字的条目,如果一个表上有十个索引,那么一次插入操作就可能引发十次额外的索引更新操作,写的开销就会很大,创建索引需要一个平衡,需要在查询速度和写入速度之间做权衡。

我们应该在哪些列上创建索引呢?这又是一个关键问题,有以下几个原则可以参考:
第一,为经常出现在查询条件(WHERE子句)中的列创建索引,你经常要按用户ID查信息,那就在用户ID列上建索引;经常按订单日期范围查询,就在日期列上建索引,这是最经典的用法。
第二,为需要做连接查询(JOIN)的列创建索引,比如两个表通过“部门ID”进行连接,那么在这两个表的“部门ID”列上建立索引,可以极大地加快连接速度。

第三,为经常需要排序(ORDER BY)或分组(GROUP BY)的列创建索引,因为索引本身是有序的,数据库可以直接利用索引的顺序来返回结果,避免了临时的排序操作,这在MySQL的优化指南中被多次强调为一种有效的优化手段。
也有一些情况创建索引可能效果不大,甚至没必要,一个列的值只有很少的几种可能(性别”列,只有“男”和“女”两种值),这种列我们称为“低选择性”列,在这种列上建索引,数据库通过索引查到的还是一大堆记录的地址,然后还得去逐一读取,性能提升有限,又或者,那些很少被用于查询的列,就没必要为它们建立索引,否则只会增加维护负担。
索引的类型也有很多种,就像图书馆里有按拼音排序的目录,也有按部首排序的目录,以适应不同的查找需求,最常见的叫B-Tree索引(平衡树索引),它非常适合处理等值查询(姓名=‘张三’”)和范围查询(日期 between ‘2023-01-01’ and ‘2023-12-31’”),还有一种叫“哈希索引”,它特别适合做等值查询,速度极快,但它不支持范围查询,这些不同的索引结构在《数据库系统概念》这本经典教材中有详细的对比分析。
还有一个容易被忽略但非常重要的概念叫“复合索引”,也叫“组合索引”,它不是只针对一列,而是针对多个列一起建立的索引,你经常需要按“城市”和“姓氏”来查询客户,那么创建一个(城市,姓氏)的复合索引,会比单独在城市上建一个索引、在姓氏上再建一个索引要高效得多,复合索引的顺序很重要,它遵循“最左前缀”原则,意思是,查询条件必须包含复合索引最左边的列,才能有效地利用这个索引,比如你创建了(城市,姓氏)索引,那么查询条件里只有“城市”时可以走索引,只有“姓氏”时可能就用不上这个索引了,这个原则在众多数据库的实践中被证明是正确使用复合索引的关键。
索引是提升数据库查询性能的利器,但它不是凭空变出来的魔法,理解它的工作原理,就像理解了图书馆的目录系统一样,能让你知道如何高效地找到你想要的数据,也要清醒地认识到索引带来的开销,避免盲目创建,这仅仅是数据库性能优化的第一步,后面还有查询语句的优化、表结构的设计、硬件配置等等很多“事儿”值得我们慢慢探讨,但无论如何,掌握了索引的秘密,你就已经拿到了打开数据库高性能大门的第一把钥匙。 结束)
本文由称怜于2025-12-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/67046.html