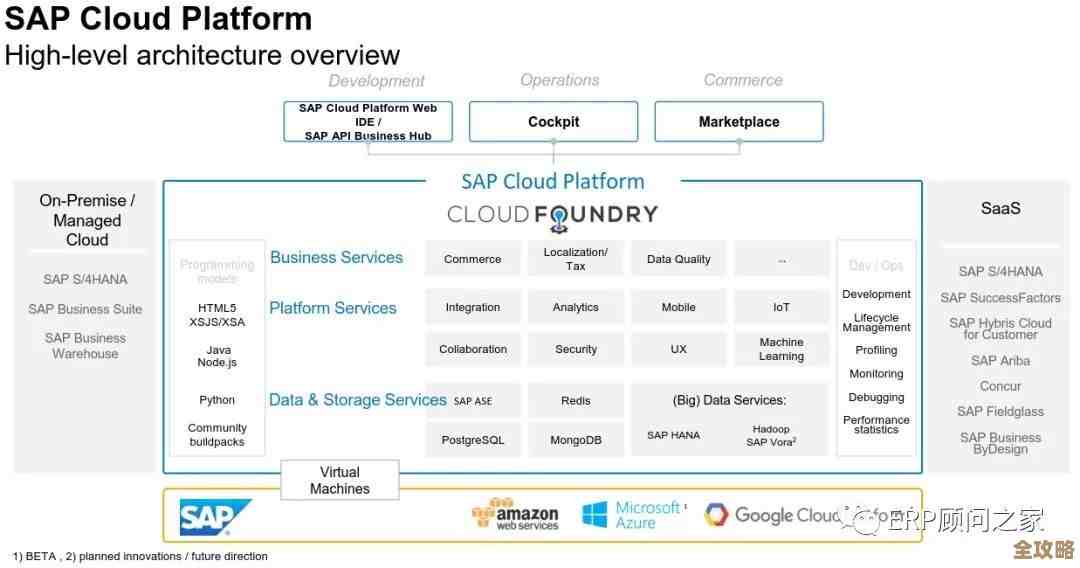
Redis集群部署面试经历分享和那些绕不开的面试题聊聊

上次我去面试一家做电商平台的公司,二面的技术官主要考察分布式系统的经验,聊完数据库分库分表后,他话锋一转,问到了Redis集群,他说:“假设我们现在促销活动,流量很大,单机Redis有点扛不住了,老板让你牵头搞集群,你会怎么考虑?”
我心想,这问题挺实在,不是死记硬背概念,我就从最实际的痛点开始说,我说,首先肯定不是为了一上来就用最复杂的方案,我得先看看现有单机瓶颈在哪,如果是内存不够,可能先考虑纵向升级,加点内存最省事,但如果数据量确实大到一台机器装不下,或者要求高可用不能宕机,那才必须上集群。
技术官点点头,让我继续说,我就把我知道的两种主要路子讲了讲,一种是Codis这类代理方案,我记得是在知乎上看过一个专栏对比过(引用来源:知乎专栏“Redis深度探险”),应用端不用改代码,连上代理层就行,代理帮你把请求转发到后面对应的Redis实例,好处是对业务透明,接入快;缺点是得多维护一个代理层,而且这个代理层本身也可能成为瓶颈和单点。

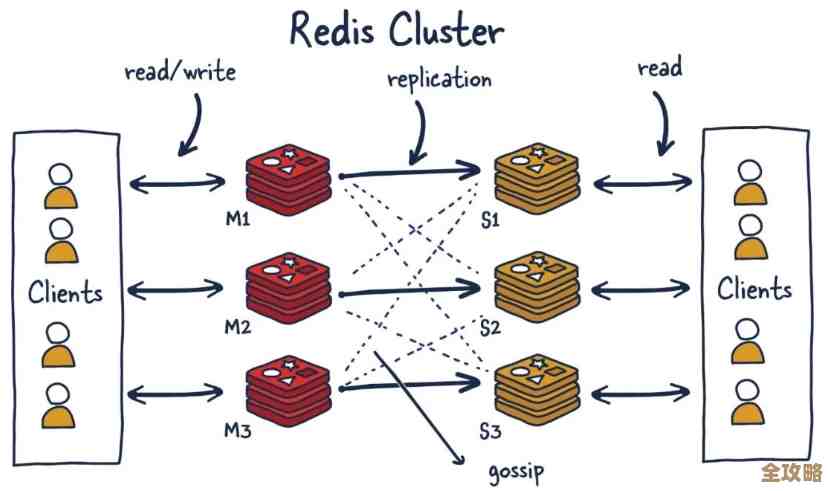
另一种就是Redis官方自带的Redis Cluster,我坦白说,这个我学习的时候搭过环境,但生产环境没亲手搞过,它的特点是没有中心代理,每个节点都负责一部分数据槽位,节点之间通过Gossip协议通信(这里他插话问了下Gossip是啥,我就简单说了下就像办公室里传小道消息,一传十十传百,最终大家都会知道集群的状态),好处是去中心化,官方原生支持;缺点就是客户端得支持Cluster协议,要能感知分片,有时候需要动一动应用代码,而且迁移过程中可能会遇到重定向的问题,增加一点延迟。
技术官接着问:“那按你的说法,选了Redis Cluster,你觉得在实际部署和运维里,最需要关心哪几个点?”我琢磨了一下,说了三点,第一是数据分片,怎么保证数据均匀分布,避免某个节点成了热点,比如用tag关键字让同一个订单的相关数据都落在一个分片上,第二是扩容缩容,增加节点时数据迁移怎么不影响线上服务,会不会卡住,第三就是高可用,主节点挂了,从节点怎么快速顶上,这个选举过程会不会慢。

然后他就着高可用往下挖,问了一个很经典的问题:“你知道Redis集群是怎么做故障转移的吗?和哨兵模式有啥区别?”这个我准备过,我说哨兵是独立部署的进程,专门负责监控主从节点和 orchestrate 故障转移,像个监工,而Redis Cluster的故障转移是集群内部自己完成的,每个主节点都有对应的从节点,主节点失联后,从节点们会协商投票,选出新的主节点,更像是一种自治理的模式,他追问:“那如果网络出现分区,比如大脑分裂了,集群会怎么样?”这个问题有点深,我凭印象说Redis Cluster有个原则是大多数主节点可达才能提供服务,这是为了数据一致性牺牲部分可用性,防止出现数据错乱。
后面还问了一些零散的,比如集群模式下哪些跨key的操作不能用(像是不在同一个节点的keys就不能做交集并集),持久化策略在集群里怎么配置,有没有遇到过数据倾斜怎么排查。
整场聊下来,我感觉面试官不是要我能把Redis集群源码背出来,而是看有没有实际的思考过程,能不能把技术选型的权衡、优缺点和可能踩的坑说出来,他最后说了一句让我印象很深的话:“能用好集群,不在于你多熟悉部署命令,而在于你能不能预见它会在什么地方给你惹麻烦。”这次面试让我觉得,这些绕不开的面试题,其实都是未来工作中实实在在要面对的选择题和填空题。
本文由黎家于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/83130.html