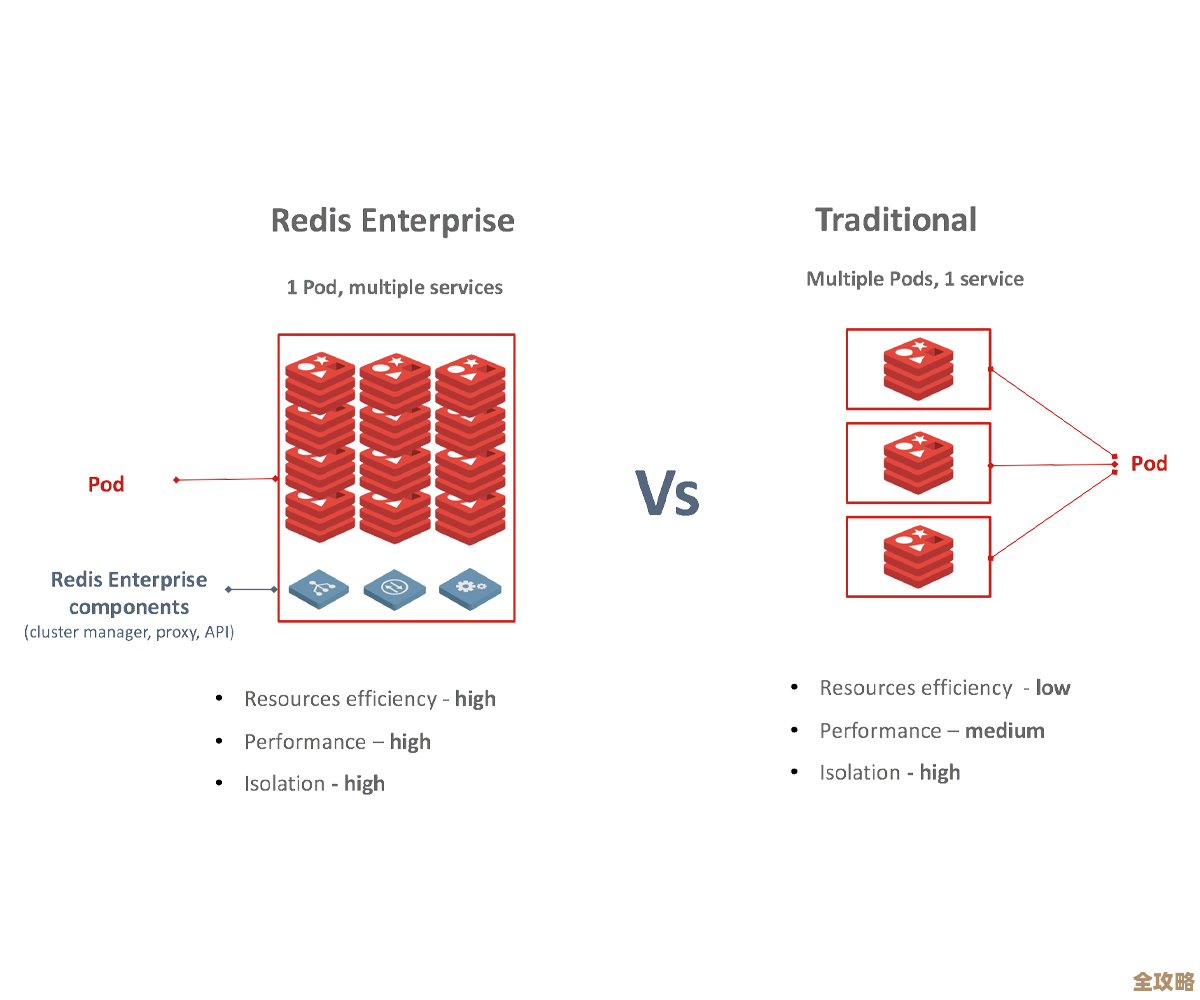
Redis数据库设计文档怎么写才算精准优化,解决方案其实没那么复杂

关于Redis数据库设计文档怎么写才算精准优化,解决方案其实没那么复杂,这个问题的答案其实就藏在日常的开发习惯里,很多团队把文档写成了命令的罗列,或者是一堆复杂概念的堆砌,这反而让文档失去了指导意义,真正精准优化的文档,核心不在于用了多少高级术语,而在于它是否能清晰地回答几个关键问题,让任何一个读到文档的开发者都能迅速理解“为什么这么用”以及“出了事怎么办”。
最重要的部分是“业务场景描述”,这一部分绝对不能含糊其辞,不能只写“用于缓存”,这太宽泛了,要写清楚是缓存什么数据?比如是“商品详情页的静态信息”,这个数据的读频率是多少?是每秒几万次还是每分钟几次?写频率呢?数据更新的触发方式是什么?是管理员在后台修改后主动更新,还是等待缓存自然过期?预期的缓存命中率要达到多少?比如要求99.9%,数据一致性要求高吗?是允许几分钟的延迟,还是必须秒级同步?这些具体的数字和场景,是后续所有设计决策的基石,没有这个基础,任何优化都是空中楼阁。(参考来源:Redis官方文档中关于使用模式的部分,强调理解工作负载是第一步)
是“数据结构设计”,这里要避免直接甩出一个“使用Hash结构”就完事了,精准的文档会解释“为什么选这个结构”,要存储用户会话信息,选择Hash而不是多个String,理由要写清楚:因为一次会话获取通常需要所有字段,Hash的HGETALL命令一次网络IO就能拿到,而用多个String需要多次IO,性能差,要考虑到内存使用,如果字段很多但经常只访问其中一两个,那可能String更合适,还要考虑过期时间,会话是需要整体过期的,Hash可以设置一个整体的TTL,而一组String管理起来很麻烦,甚至要写上如果未来要添加新字段,这个结构是否容易扩展,这样的解释,才能体现“优化”的思考过程。
第三点是“键名规划”,这是最容易忽视但影响深远的地方,好的键名不是随意的,它本身就是一种设计,文档里要明确规定键的命名规范,用冒号分隔形成一种层次结构:“业务名:对象类型:对象ID”,user:session:12345”,这样做的好处是,当你想手动排查问题或者写脚本批量管理时,可以使用“KEYS user:session:*”这样的模式来匹配所有会话键,统一的规范避免了不同开发者写出风格迥异的键名,导致后期维护混乱,这看似简单,却是保证长期可维护性的关键优化点。
第四,必须包含“过期与内存管理策略”,Redis是内存数据库,内存是命根子,文档不能只说“设置过期时间”,要明确具体策略。“用户会话数据设置30分钟过期,采用惰性删除和定期删除策略,由Redis自身管理”,对于可能增长很快的数据,比如排行榜,要写明“采用ZSET结构,只保留前1000名,每次更新后使用ZREMRANGEBYRANK修剪”,对于内存不足时的应对策略,要根据业务重要性选择maxmemory-policy,如果内存满了,优先淘汰最近最少使用的键(allkeys-lru)”,把这些策略白纸黑字写下来,能有效防止内存泄漏和服务器崩溃。
第五点是“异常情况与降级方案”,一个健壮的系统设计必须考虑失败,文档里要回答:如果Redis完全不可用了,系统会怎样?“缓存宕机后,所有请求将直接访问后端数据库,数据库需要能承受压力,报警系统会立即通知运维人员。”对于热点Key问题,也要有预案:“如果某个商品突然变成爆款,其缓存Key访问量巨大,可以考虑使用本地缓存(如Guava Cache)做二级缓存,或者将Key拆分成多个子Key进行分散。”把这些解决方案写在文档里,团队在遇到问题时就不会慌乱。
文档应该是一个“活文档”,它不应该在项目启动后就被遗忘,可以在文档开头注明“版本号”和“最后更新时间”,当业务发生变化,比如用户量翻倍、新增了某个复杂查询,都需要回过头来评审和更新这份设计文档,最初用String缓存一篇文章内容没问题,但当文章内容巨大时,可能就要考虑改用更节省内存的数据结构或者压缩算法了,这个变更决策和原因就应该记录在文档的新版本中。
一份精准优化的Redis设计文档,更像是一份针对特定业务场景的“问答记录”和“思考过程记录”,它抛弃了华而不实的模板,聚焦于为什么这么设计、怎么应对各种情况,它不需要很深奥的专业术语,但需要把业务逻辑和技术选择之间的因果关系讲透彻,这样的文档,才能真正指导开发,避免踩坑,实现真正的“优化”。(参考来源:多位资深工程师在技术社区分享的关于架构文档写作心得的总结)

本文由太叔访天于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/82027.html