Redis集群服务器老是出问题,怎么才能彻底搞定这故障烦恼呢?

“Redis集群服务器老是出问题,确实非常让人头疼,这就像家里一个关键的电闸老是跳闸,搞得整个系统都不得安宁,要彻底搞定这个烦恼,不能光想着每次出问题了去重启一下或者临时补一补,得从根子上想办法,建立一个完整的预防和处理体系,根据一些常见的运维实践和社区经验,我们可以从以下几个方面系统性地入手。
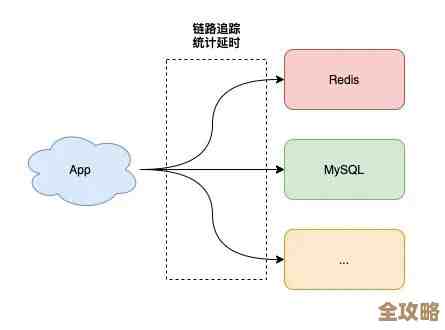
最要紧的是把监控做到位,你不能等到服务器都挂了才知道出事了,那太被动了,这就好比给服务器装上健康监测手环,你需要监控哪些关键指标呢?一是内存使用率,这是Redis最容易出问题的地方,内存用满了就会导致写入失败或者触发淘汰机制,影响服务,二是连接数,看看是不是有异常的大量连接,可能是客户端没有正确释放连接导致的,三是CPU使用率,如果持续很高,说明服务器压力太大,四是网络带宽和延迟,网络不稳定会直接导致集群节点间通信失败,造成集群分裂,五是关键命令的执行情况,比如有没有大量的慢查询,市面上有很多现成的监控工具,比如Prometheus配上Grafana来做可视化 dashboard,让你对集群的状态一目了然,一旦这些指标出现异常,监控系统要能第一时间通过短信、邮件或者钉钉之类的工具告警给你,让你能抢在问题恶化前介入。
要做好容量规划和管理,别让服务器‘撑着了’,很多故障都是因为内存不足引起的,你得定期检查业务增长情况,预估未来一段时间需要的内存容量,提前进行扩容,扩容不是简单加内存,Redis集群扩容涉及到数据迁移,最好在业务低峰期操作,要关注内存碎片率,过高的碎片率会浪费大量内存,必要时需要重启节点来整理碎片(但这本身有风险,需谨慎),对于数据的过期时间也要合理设置,避免无用数据长期占用内存。

第三,架构设计要合理,Redis集群本身是为了解决单点故障和容量瓶颈的,但如果你的架构设计得不好,集群的优势也发挥不出来,客户端连接方式很重要,应该使用智能客户端或者代理模式,让客户端能感知集群节点变化,自动重连到正确的节点,避免因为某个节点宕机导致整个服务不可用,再比如,持久化策略要根据业务对数据安全性的要求来选择,如果允许分钟级别的数据丢失,可以用RDB持久化,性能好,如果要求更高,可以用AOF,或者混合使用,但要清楚AOF文件会越来越大,重写时会消耗资源,网络层面,确保集群节点之间的网络是稳定且低延迟的,最好都在同一个机房的内网中,避免跨机房部署带来的网络不确定性。
第四,制定清晰的运维规范和应急预案,人总会犯错,但好的流程能减少犯错的可能,要规范操作,比如严禁在线上的Redis集群直接执行keys *这种可能引发长时间阻塞的危险命令,对于任何变更,比如版本升级、配置修改,都要先在测试环境充分验证,然后制定详细的回滚方案,最重要的是,必须有一个写好的应急预案,并且定期演练,预案里要写清楚,当出现‘集群主节点宕机’、‘集群脑裂’、‘内存爆满’、‘响应变慢’等典型故障时,第一步做什么,第二步做什么,谁来负责,联系谁,这样真出了事才不会手忙脚乱,平时可以用混沌工程的方法,故意在测试环境模拟节点故障,检验系统的容错能力和团队的应急反应速度。

第五,深入理解故障背后的根本原因,每次故障解决后,不能就这么过去了,一定要组织复盘,写事故报告,弄清楚到底是为什么出的问题:是代码bug?是配置错误?是容量不足?还是人为误操作?只有找到了根因,才能采取针对性的措施,防止同样的问题再次发生,这可能意味着你需要修改代码、优化配置、加强培训或者改进工具。
保持软件版本的更新也是很重要的,Redis社区会不断修复已知的bug和发布新特性,定期评估升级到稳定新版本的可能性,但同样,升级必须在测试环境充分测试。
彻底搞定Redis集群的故障烦恼,没有一劳永逸的银弹,它需要你转变思路,从被动的‘救火’转变为主动的‘防火’,通过建立完善的监控预警体系、做好容量规划、优化架构设计、制定严格的运维流程和应急预案,并坚持从每次故障中学习,你就能大大降低故障发生的频率,即使发生了也能快速、冷静地解决,从而真正摆脱没完没了的故障烦恼。”
本文由歧云亭于2026-01-12发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/79385.html