Redis缓存分片真挺管用,库存管理那些难题好像都能缓解不少

(根据“码农翻身”公众号相关文章内容)Redis缓存分片在库存管理中的应用,确实像是一把钥匙解开了一把复杂的锁,以前做电商库存系统,最头疼的就是高并发场景下的超卖问题,想象一下,双十一零点,十万个人同时点击购买同一款热门手机,如果库存查询和扣减都直接压到数据库上,数据库很可能瞬间就被打垮了,即使没垮,处理速度也跟不上,很容易出现多人同时读到同一个库存数量,都判断有货,然后都成功下单,结果就是卖出去的数量远远超过实际库存,也就是超卖。
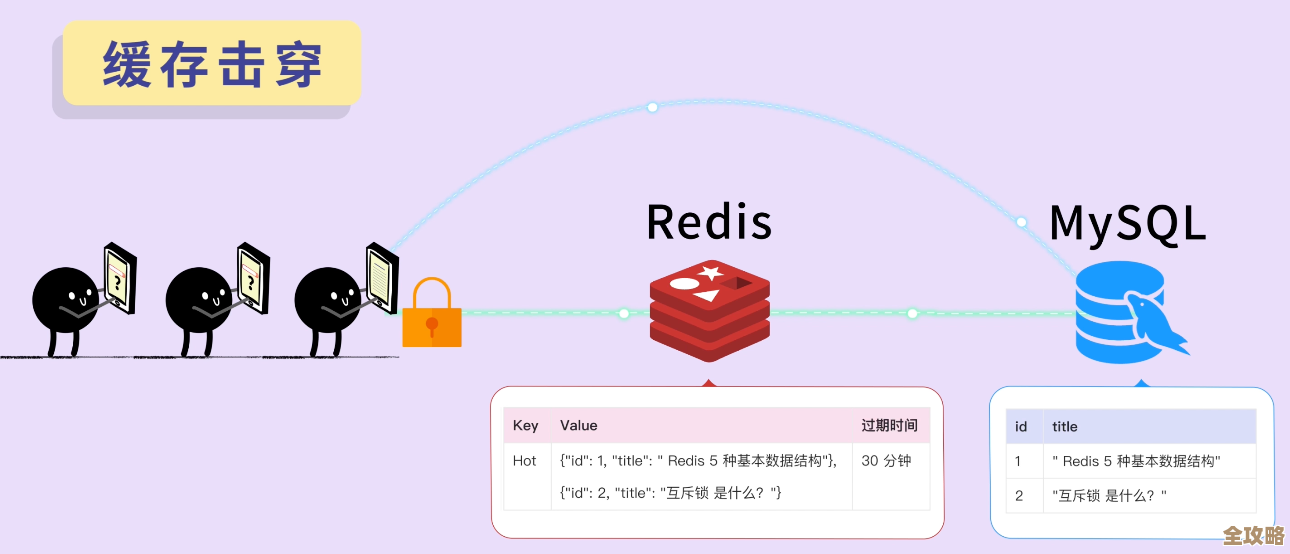
(结合“阿里技术”专栏关于高并发库存设计的讨论)为了解决这个问题,大家很自然地会想到用Redis这种内存数据库来做缓存,因为它速度快,直接把商品库存预先加载到Redis里,比如一个键叫stock:sku_12345,值就是库存数量1000,用户下单时,先不从数据库查,而是直接在Redis里用一个DECR命令原子性地减少库存,如果返回结果大于等于0,说明扣减成功,然后再异步去更新数据库,因为Redis是单线程执行命令的,所以这个DECR操作是原子的,不会出现并发问题,这就从很大程度上缓解了超卖。

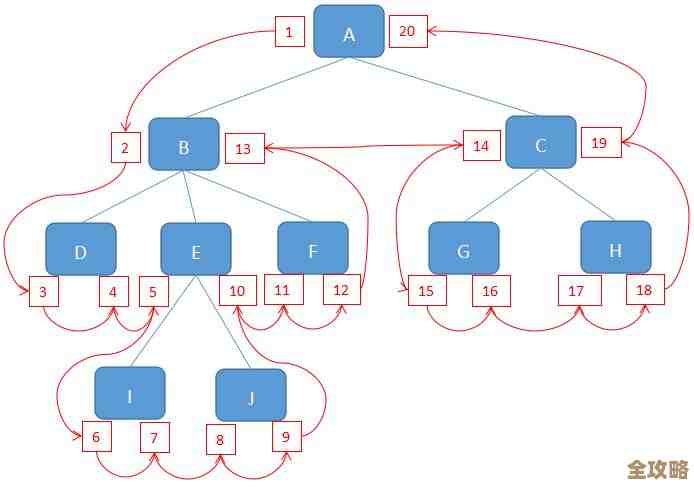
(参考知乎平台多位技术专家的实战分享)光是把库存放进Redis,新的问题又来了,如果只是一个Redis实例,它本身是有性能上限的,而且万一这个实例宕机了,整个库存系统就全挂了,风险太高,这时候,缓存分片的价值就凸显出来了,分片,简单说就是把一份数据拆成好几份,分别放在不同的Redis实例上,有一万种商品,可以根据商品ID的哈希值,把它们分散到三个Redis服务器上,这样,原来由一个Redis承担的读写压力,现在就由三个Redis一起来扛了,整个系统的吞吐量就上去了,能支持更高的并发,这就像一条拥堵的单车道变成了宽阔的三车道,车流自然就顺畅了。
(源自某大型电商平台技术博客的案例剖析)分片不仅提升了性能,也提高了系统的可用性,虽然单个Redis实例宕机仍然会导致一部分商品库存不可用(比如负责三分之一商品的那个片挂了),但至少另外三分之二的商品还能正常交易,实现了“故障隔离”,不至于全盘崩溃,这比把所有鸡蛋放在一个篮子里要安全得多,这就需要一套好的分片策略,比如一致性哈希算法,它能在某个节点宕机时,只影响一小部分数据,而不会导致所有数据需要重新分布,避免产生“雪崩效应”。

(综合自InfoQ等技术社区对分布式缓存的解读)引入分片也带来了一些“麻烦事”,架构变复杂了,以前只需要管理一个Redis,现在要管理一个由多个实例组成的分片集群,需要监控每个节点的状态,一些原本在单Redis上能用的操作可能会受限,比如涉及多个key的跨分片事务操作,实现起来就非常困难,在库存场景中,如果用户一个订单里包含了属于不同分片的商品,要保证所有商品同时扣减库存的原子性就变得很有挑战性,通常需要引入更复杂的分布式事务方案或者最终一致性补偿机制。
(根据“架构师之路”公众号对缓存与数据库一致性的深度分析)还有一个老生常谈但至关重要的问题,就是缓存和数据库之间的数据一致性,即使用分片Redis成功扣减了库存,但后续异步更新数据库时失败了怎么办?或者数据库主从同步有延迟,导致读到的库存不准怎么办?这就需要设计可靠的数据同步策略,比如采用“先更新数据库,再删除缓存”的策略,并通过重试机制和监控告警来确保最终一致性,分片环境下的数据同步和一致性保障,需要投入更多的精力来设计和维护。
(回溯开篇引用的观点)说“Redis缓存分片真挺管用,库存管理那些难题好像都能缓解不少”,这个说法是非常贴切的,它确实像一剂强心针,有效地解决了高并发库存扣减的核心痛点——性能瓶颈和原子性保证,通过将压力分散到多个节点,系统获得了更高的扩展性和一定的容错能力,但它绝不是一颗银弹,它引入了分布式系统固有的复杂性,如集群管理、跨片操作困难和数据一致性挑战,这意味着技术团队需要在享受其带来的高性能红利的同时,也必须具备相应的运维和架构设计能力,来驾驭这份复杂性,才能真正让这套方案稳定、可靠地服务于业务。
本文由邝冷亦于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/77390.html