Redis集群性能到底咋样,实际操作验证和体验分享

我之前在一个用户量挺大的电商项目里,亲身经历了从单机Redis切换到Redis集群的全过程,说实话,一开始心里是有点打鼓的,毕竟听人说集群会有点性能损耗,操作也变复杂了,但业务增长太快,单机内存眼看就不够用了,还有单点故障的风险,不上集群不行,下面我就聊聊自己实际折腾下来的真实感受。
最关心的性能问题:是变快了还是变慢了?
答案是:看情况,但绝大多数场景下,你觉得是“更快了”,尤其是整体吞吐量。

-
单条命令的延迟: 理论上,因为集群模式下,客户端需要先根据key计算应该发到哪个分片(他们叫slot),然后再发请求,这个多出来的步骤会带来一丁点的延迟,但说实话,在实际网络环境中,这点延迟增长微乎其微,正常业务根本感觉不到。 我用测试工具压测过,在局域网环境下,单次GET/SET操作的延迟增加可能连零点几毫秒都不到,对于大部分要求毫秒级响应的业务来说,完全可以忽略不计,担心集群会“变卡”的朋友可以放宽心。
-
吞吐量(QPS): 这是集群最大的优势所在,单机Redis的性能再高,也是有上限的,CPU和网络带宽就那么多,我们把数据分到三个主节点上,相当于把压力也分摊了,最直观的感受就是,在大促期间做秒杀活动,以前单机Redis的CPU使用率经常飙到90%以上,响应开始变慢,上了集群之后,每个节点的负载都很均衡,CPU使用率基本维持在50%-60%,整个系统非常稳定,吞吐量几乎是线性增长。如果你的业务瓶颈在于并发量太大,那集群带来的性能提升是立竿见影的。
实际操作中的一些体验和“坑”:

-
键值设计变得超级重要: 这是我最想强调的一点!Redis集群要求单个命令操作的多个key必须位于同一个slot,而slot是由key的hash tag决定的,我们有个需求是要同时删除一个用户的所有购物车商品(多个key),如果这些key没有使用相同的hash tag(比如都用
{userId}包起来),那么你就没法直接用DEL key1 key2 key3这种命令,因为key可能分布在不同的节点上,会导致命令执行失败,我们必须改造代码,要么用hash tag保证这些key在同一个slot,要么就只能一个个删除,或者使用Lua脚本(但Lua脚本也有要求所有key在同一个节点的限制)。上集群前,一定要仔细梳理业务,规划好key的命名规则,这是个细致活,但能避免后面很多麻烦。 -
批量操作要小心: 像
MSET、MGET这种批量命令,同样受到上面说的“多key必须在同一slot”的限制,我们一开始没注意,导致很多批量操作的代码报错,后来要么拆成单个命令执行(会牺牲一点性能),要么就重新设计key,市面上一些好的Redis客户端(比如Java的Lettuce)支持自动根据key的slot分组,然后并行发送到不同节点,最后合并结果,这算是一个不错的解决方案。 -
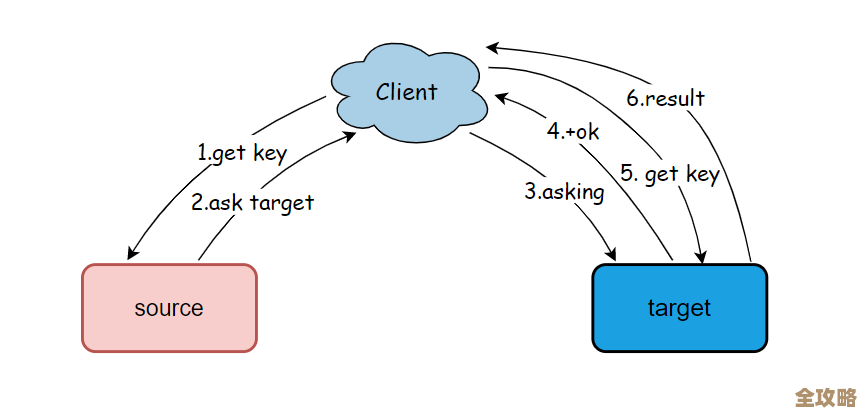
运维复杂度确实增加了: 以前只需要监控一个Redis实例,现在要同时监控好几个主节点和从节点的状态、内存、网络等,虽然有了集群管理工具,但心理压力还是比单机大,比如有一次,我们一个主节点的物理机网络出了点问题,触发了故障转移,从节点切换成了主节点,这个过程虽然是自动的,但也导致了有几秒钟的服务不可用和少量写入失败。集群的高可用不是百分百无缝的,要有容错和重试机制。

-
资源消耗更多: 这个很好理解,原来跑一个Redis实例,现在至少要跑三个(三主三从是最小要求),对服务器资源(CPU、内存)的消耗肯定是成倍增加的,这是为了获得高可用和高并发必须付出的成本。
总结一下我的体验:
Redis集群的性能表现,在应对大数据量和高并发场景时是非常出色的,它通过分布式架构解决了单机的根本性瓶颈,你感受到的那一点点理论上的延迟损耗,在巨大的吞吐量收益面前基本可以忽略。
它绝对不是简单地换个配置就能无缝使用的,它对你使用Redis的方式提出了更高的要求,特别是数据模型设计和key的规划,如果你之前的代码写得很随意,上集群时的改造工作量可能会不小。
我的建议是:如果你的数据量不大(比如几个G),并发也不高,单机Redis加个从库做备份就足够了,简单省心,但一旦你预估业务会快速增长,或者已经遇到了单机性能瓶颈,那就应该尽早规划和迁移到集群模式,提前把key的设计规范好,这样后面会顺利很多,Redis集群是个非常成熟和可靠的解决方案,只要你用对了,它会是你系统稳定运行的强大后盾。
本文由召安青于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/77195.html