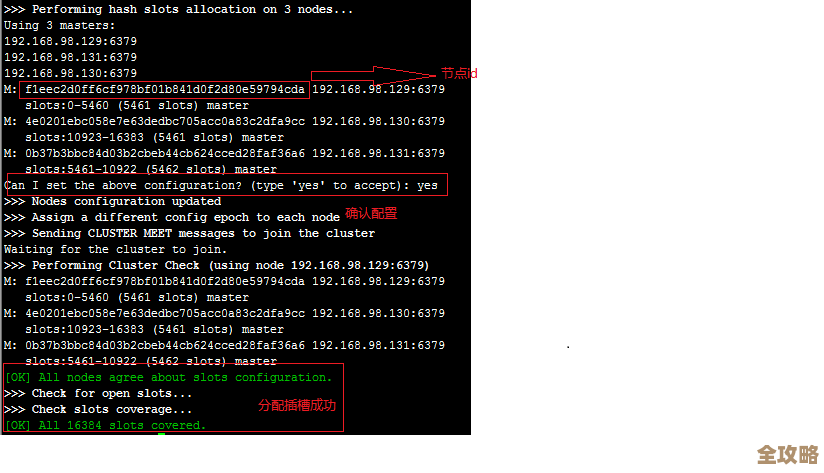
ORA-16235报错原因和解决办法,远程帮你快速搞定导入跳过问题

ORA-16235是Oracle Data Guard环境中,当主库尝试向备库传输或应用归档日志(Archived Log)时可能遇到的一个错误,这个错误的核心信息通常是“无法在指定时间内将日志应用到备用数据库”,就是备库“跟不上”主库的变化速度了,导致数据同步出现了积压或中断,下面我们根据Oracle官方文档、MOS(My Oracle Support)知识库以及常见的运维实践经验,来详细拆解它的原因和解决办法。
ORA-16235报错的根本原因
这个错误很少由单一因素引起,通常是主备库两端环境共同作用的结果,我们可以从“主库推送压力大”和“备库处理能力弱”两个角度来分析。
-
来自主库的压力过大(根源之一):
- 高负载事务: 主库正在执行大量的、长时间运行的DML操作(比如大批量的数据插入、更新或删除),或者有大型的数据导入操作(例如使用IMPDP),这会导致在短时间内产生海量的重做日志(Redo Log),正如Oracle文档所指出的,重做日志是数据同步的基础,主库会将这些日志归档后传输给备库,如果日志生成的速度(Redo Generation Rate)远超备库的正常应用速度,队列就会越排越长,最终触发ORA-16235。
- 日志传输瓶颈: 主库和备库之间的网络带宽不足或网络不稳定,会导致归档日志文件传输延迟,即使备库处理能力很强,原料”(日志文件)送不过来,也会造成积压,MOS上有不少案例提到,需要检查网络延迟和带宽占用情况。
-
备库自身处理能力不足(直接原因):
- I/O性能瓶颈: 这是最常见的原因之一,备库在应用日志时,需要频繁地读写数据文件,相当于在“重放”主库的操作,如果备库的存储I/O性能(包括磁盘的读写速度)比主库差很多,那么它应用日志的速度自然会慢,就像用一台老旧的电脑打开大型软件一样卡顿,MOS文章经常强调要对比主备库的I/O指标。
- CPU资源竞争: 应用日志本身需要消耗CPU资源,如果备库服务器上还运行着其他消耗大量CPU的程序(比如报表查询、备份任务等),留给日志应用的CPU资源就会不足,导致应用进程(Managed Recovery Process, MRP)变慢。
- 备库架构问题: 如果备库是物理备库,但配置了只读模式并长时间打开用于查询(Active Data Guard功能除外),那么在应用日志时可能需要频繁地在“应用模式”和“只读模式”之间切换,这个过程会产生额外的开销,影响同步效率。
- 日志文件损坏或缺失: 虽然较少见,但如果传输过程中的某个归档日志文件损坏,或者备库上缺失了某个关键的日志文件,MRP进程会停止并等待,从外部看也像是同步延迟,可能间接引发相关错误。
解决ORA-16235的实战步骤
解决思路很清晰:要么“减轻主库的负担”,要么“提升备库的能力”,或者双管齐下,以下是按照从易到难、从检查到操作的顺序列出的方法。

-
立即检查与监控:
- 查看同步状态: 首先在备库上执行
SELECT PROCESS, STATUS, THREAD#, SEQUENCE#, BLOCK#, BLOCKS FROM V$MANAGED_STANDBY;这个查询结果非常重要,重点关注MRP进程的状态,如果它是“APPLYING_LOG”,说明正在工作,但可能进度落后;如果状态异常,WAIT_FOR_LOG”,则表明可能在等待某个日志文件。 - 评估延迟程度: 查询
SELECT ARCHIVED_THREAD#, ARCHIVED_SEQ#, APPLIED_THREAD#, APPLIED_SEQ# FROM V$ARCHIVE_DEST_STATUS WHERE DEST_ID=2;(假设备库对应的目标ID是2),通过比较已归档的日志序列号(ARCHIVED_SEQ#)和已应用的序列号(APPLIED_SEQ#),可以直观地看到落后了多少个日志文件,这个差距就是延迟量。
- 查看同步状态: 首先在备库上执行
-
针对性解决方案:
-
如果主库负载过高:
- 错峰操作: 与业务部门协调,将大量数据导入/导出、批量处理等高压操作安排在业务低峰期进行。
- 优化SQL: 检查并优化主库上那些效率低下、产生大量重做日志的SQL语句,减少不必要的重做日志生成。
-
如果备库I/O或CPU是瓶颈:

- 资源调配: 临时停止备库上非关键的资源消耗型任务(如复杂报表查询、备份),确保所有资源优先保障日志应用。
- 硬件升级: 如果长期存在性能差距,应考虑提升备库的硬件配置,特别是存储系统的性能,使其尽量与主库匹配。
-
使用“跳过”操作(应急手段):
- 当延迟非常大,且急需让备库尽快追上主库时,可以考虑跳过当前出问题的日志文件。这是一个有数据风险的操作,务必谨慎! 它意味着备库会丢失被跳过日志中所记录的数据变更。(根据MOS文档的说明)
- 操作步骤:
- 在备库上停止日志应用服务:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL; - 使用
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;命令也会停止恢复。 - 然后跳过指定的日志序列号,如果发现序列号100的日志无法应用,可以尝试:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE SKIP FAILED TRANSACTION;或者更直接的,通过指定下一个日志来跳过:ALTER DATABASE REGISTER LOGFILE ‘物理日志文件路径’;注册下一个可用的日志文件。具体跳过方法可能因版本和情况而异,强烈建议在操作前查阅对应版本的MOS文档。 - 跳过后,重新启动日志应用:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
- 在备库上停止日志应用服务:
- 重要警告: 跳过日志是最后的选择,这会导致主备库数据出现不一致,跳过之后,通常需要对备库进行一次全量重建(从主库做一个新的备份并恢复),才能重新获得一个完整一致的备用数据库。
-
检查并优化网络:
确保主备库之间的网络连接稳定且带宽充足,如果可能,使用专线或高质量的网络链路。
-
调整初始化参数(进阶):
- 在某些情况下,可以调整与日志应用相关的参数,比如适当增大
PARALLEL_MAX_SERVERS等参数来启用并行应用,以加快速度,但这需要较强的专业知识,并且需要根据系统实际情况调整,不当的调整可能引发其他问题。
- 在某些情况下,可以调整与日志应用相关的参数,比如适当增大
-
ORA-16235是一个典型的“性能不匹配”警告,解决它需要系统性的排查,从监控入手,先定位是主库的“推力”太猛,还是备库的“消化”能力太弱,常规方法是优化负载和硬件资源,而“跳过日志”只是一个万不得已的紧急措施,会牺牲数据一致性,在日常运维中,保持主备库环境配置的均衡,并建立完善的监控告警机制,是预防此类问题的关键。
本文由盈壮于2026-01-08发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/76607.html