Redis通道怎么用来快速存数据,效率提升还有那些技巧分享

Redis本身就是一个非常快的内存数据库,但要用到极致,尤其是在大量数据读写的场景下,确实需要一些技巧,通道(Pipeline)是其中最关键的技术之一,但它不是全部,下面就直接说说怎么用通道,以及配合其他哪些方法能更快。
Redis通道(Pipeline):把多个请求“打包”发送
想象一下,你要往仓库里搬10箱货,最慢的方法就是搬一箱,走到仓库放下,再回来搬第二箱,这样来来回回,大部分时间都花在路上了,不用通道的Redis操作就是这样,客户端发送一个命令(比如SET一个键值对),然后等待Redis服务器处理并返回结果,之后再发送下一个命令,这个来回通信的网络延迟(RTT)就成了主要的性能瓶颈。
通道的作用就是让你能一次性把10箱货都放在一个小推车上,推一趟送到仓库,大大减少了走路的时间,通道允许客户端一次性将多个命令打包成一个请求发送给Redis服务器,然后一次性接收所有命令的返回结果。
根据Redis官方文档 中的说明,使用通道后,在因为网络延迟而变慢的场景下,性能提升可以达到惊人的几倍甚至几十倍,尤其是在客户端和服务器物理距离较远(比如跨机房、跨地域)的情况下,效果尤其明显。
怎么用呢? 以Python的redis-py库为例,不用通道的代码是循环执行:
for key, value in large_data.items():
r.set(key, value)
而使用通道的代码是:
with r.pipeline() as pipe:
for key, value in large_data.items():
pipe.set(key, value)
pipe.execute() # 一次性发送所有set命令
就是把多个命令先“积攒”起来,最后用一句execute()统一发送,这里要注意,一次打包的命令数量也不是越多越好,通常建议在几千到一万个左右,避免单个数据包太大或长时间阻塞服务器,需要根据实际情况测试找到一个平衡点。
除了通道,还有哪些提速技巧?
光用通道还不够,配合以下方法能让效率再上一个台阶。
-
使用批量操作命令:通道的“最佳拍档” 通道解决了网络往返的问题,而Redis本身提供的一些批量命令则能减少服务器解析命令的次数,是“强强联合”。
- MSET/MGET: instead of 循环SET或GET多个键,直接用
MSET key1 value1 key2 value2 ...和MGET key1 key2 ...,服务器执行一条MSET命令比通过通道执行10条SET命令的内部开销更小。 - HMGET/HMSET: 对于Hash类型,同样有批量操作字段的命令。
- :理想模式是“批量命令 + 通道”,即使MSET一次能处理100个键值对,当你需要处理10万条数据时,你可以用通道来批量发送1000条MSET命令(每条MSET命令包含100个键值对),这样既利用了批量命令的高效,又利用了通道减少网络延迟的优势。
- MSET/MGET: instead of 循环SET或GET多个键,直接用
-
连接池(Connection Pool):避免频繁建立连接的开销 建立TCP连接是一个成本很高的操作,如果每次操作Redis都新建一个连接,用完就关,那会浪费大量资源,连接池的作用就是预先建立好一批连接并维护起来,当应用程序需要时,直接从池子里拿一个现成的连接来用,用完后不是关闭,而是放回池子里供下次使用,这省去了反复建立和断开连接的开销。大多数Redis客户端都默认开启了连接池,你只需要在初始化客户端时配置好池子的大小等参数即可,一般无需额外操心,但要知道它的重要性。
-
键名设计要简短且有意义 虽然键名是字符串,看起来无所谓,但在海量数据下,键名的长度直接影响内存占用和网络传输量,一个
user:1000:profile就比user_information_id_1000_complete_profile要好得多,在保证可读性和避免冲突的前提下,键名越短越好。 -
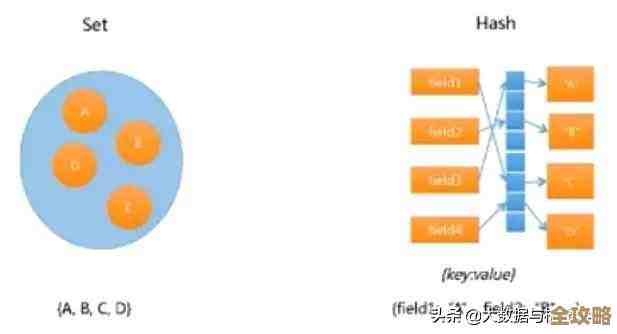
选择合适的数据结构 这是提升效率和节省内存的根本。
- 不要用多个独立的键来存储一个用户的多个字段,应该用一个Hash结构。
- 需要存储有序且需要范围查询的数据,用Sorted Set比手动排序高效得多。
- 需要判断某个元素是否存在(如防止缓存击穿),用Bloom Filter(可以通过Redis的Bitmap实现)比直接查询数据库或String类型省很多内存。
- 根据Antirez(Redis创始人)在博客中的多次强调,使用高效的数据结构是优化Redis性能最有效的手段之一,往往能带来数量级上的提升。
-
谨慎使用那些会阻塞服务器的命令 比如
KEYS命令,在生产环境大数据量下会直接导致Redis服务器短暂不可用,应该使用SCAN命令来渐进式地遍历,类似的还有对大集合执行SMEMBERS,可以考虑用SSCAN。
想要Redis存数据飞快,核心思路是“减少网络往返次数”和“降低服务器CPU开销”。
- 通道(Pipeline) 是解决网络延迟的利器。
- 将通道与Redis内置的批量命令(如MSET) 结合,是黄金组合。
- 连接池是基础保障,避免了连接开销。
- 良好的键名设计和选择最高效的数据结构是从根本上提升效率和节省资源。
在实际项目中,通常需要先进行压力测试,找到瓶颈所在(是网络延迟?是CPU?还是内存?),再针对性地选择上述技巧进行优化。

本文由称怜于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/76151.html