SQL和Redis到底差在哪儿,咋选用更合适点呢?

这个问题问得特别好,是很多开发者,尤其是刚开始做项目时都会遇到的困惑,简单打个比方,SQL数据库(比如MySQL、PostgreSQL)就像一个规划整齐、需要填表办事的大型图书馆,而Redis则像一个反应超快、但只能记关键小纸条的速记员,它们俩干的活不一样,所以用对地方就事半功倍。
根本差别:从根儿上就不是一回事
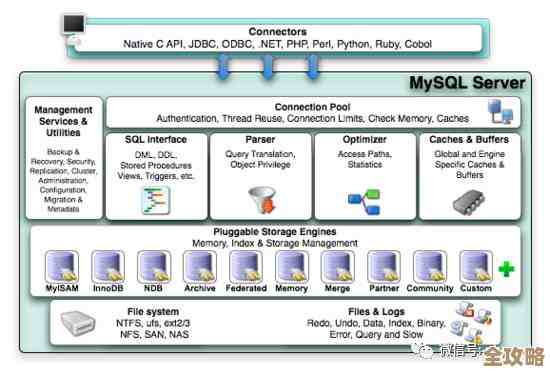
首先得明白,它俩的设计初衷完全不同,根据IBM开发者社区的一篇文章解释,SQL数据库属于“关系型数据库”,核心是“关系”,数据是以严格的表格形式存储的,就像Excel表,表与表之间可以通过主键、外键关联起来,它的强项是保证数据的完整性和复杂性,比如你存一笔订单,订单里有用户信息、商品信息、价格等,这些数据分门别类放在不同的表里,但又通过ID紧密联系在一起,这种结构非常适合处理需要复杂查询和事务(保证一系列操作要么全成功,要么全失败)的场景。
而Redis,根据其官方文档介绍,它是一个“键值存储”数据库,也被称为“内存数据库”,它的结构极其简单:一个键(Key)对应一个值(Value),这个值可以是字符串、列表、哈希、集合等多种形式,但核心模式就是通过Key来快速存取Value,Redis把数据主要放在服务器的内存里,所以读写速度极快,能达到微秒级别,这是硬盘存储的SQL数据库无法比拟的,但它的弱点是,内存比硬盘贵得多,所以通常不能像SQL那样存储海量数据。
具体差别掰开揉碎了看
-
数据模型(怎么存数据):
- SQL:就像建房子,先要画好严谨的设计图纸(数据库Schema),规定好每个表有哪些字段(列),字段是什么类型(整数、字符串、日期等),想改结构(比如加个字段)会比较麻烦,需要执行“ALTER TABLE”这样的迁移操作,数据之间关系复杂,靠JOIN操作来关联多张表查询。
- Redis:就像用便利贴,非常灵活,你不需要预先定义严格的结构,一个Key可以对应一个简单的字符串,也可以对应一个包含多个字段的哈希(Hash)对象,或者一个列表(List)、一个集合(Set),它没有JOIN的概念,数据模型相对扁平。
-
性能速度(谁更快):
- SQL:数据存储在硬盘上,虽然通过索引、缓存等技术可以优化,但最终还是要进行磁盘I/O(输入/输出),这个物理过程是有延迟的,所以它的速度是“相对较快”,适合对响应时间要求不是极其苛刻的常规业务。
- Redis:数据主要放在内存里,内存的读写速度是纳秒级,硬盘是毫秒级,差着好几个数量级,Redis的读写速度是“极快”,常用于对速度有极端要求的场景。
-
数据持久化(断电会不会丢数据):
- SQL:这是它的本职工作,数据写入首先就要保证安全地存到硬盘上,有完善的事务日志等机制,保证数据的一致性(ACID特性),你可以放心地把最重要的核心数据,比如用户账号、交易记录,放在里面。
- Redis:虽然它也提供持久化功能(比如RDB快照和AOF日志),但这更像是“备份”机制,它的首要目标是速度,所以默认情况下数据在内存中,如果配置不当或服务器突然宕机,是有可能丢失一部分最新数据的,Redis里的数据通常被看作是“暂时”的或“缓存”的。
-
查询语言(怎么操作数据):
- SQL:使用标准的SQL语言,功能非常强大,你可以进行非常复杂的查询,比如分组(GROUP BY)、排序(ORDER BY)、多表关联查询等,做数据分析报表非常拿手。
- Redis:有一套自己简单的命令,比如
SET(设置键值)、GET(获取值)、HSET(设置哈希字段)、LPUSH(从列表左边推入)等,操作很直接,但不支持复杂的查询和分析。
那到底该怎么选?看你的业务场景
明白了差别,选择就清晰了,很多时候,一个成熟的项目会同时使用它们,让它们各司其职。
你应该优先选择SQL数据库的情况:
- 核心业务数据:需要强一致性和持久化的数据,比如用户账户信息、订单、支付记录、商品库存(需要精确扣减的)等,这些数据绝对不能丢,也不能出错。
- 需要复杂查询和报表:比如你要做数据分析,需要查询“过去一个月销量前十的商品有哪些,并且按地区分组”,这种需求SQL的JOIN和GROUP BY能力是Redis无法替代的。
- 数据结构稳定:你的业务模型已经比较清晰,数据字段和关系不会频繁变动。
你应该优先选择Redis的情况:
- 缓存:这是Redis最经典的应用,把SQL数据库中经常被查询但又很少变动的数据(比如网站首页的热门文章列表、商品分类信息)放到Redis里,能极大减轻SQL数据库的压力,提升网站响应速度,根据亚马逊云科技(AWS)的文档,缓存是Redis最主要的使用场景之一。
- 会话存储:网站或App的用户登录状态(Session),把Session放在Redis里,用户在不同服务器间跳转时都能快速识别身份,而且可以方便地设置过期时间。
- 高速计数器和排行榜:比如文章的点赞数、商品的浏览次数,Redis的原子操作能保证在高并发下计数准确,而且排序功能实现排行榜非常简单高效。
- 消息队列:利用Redis的列表(List)或发布订阅(Pub/Sub)功能,可以实现简单的消息队列,用于系统间的异步通信和解耦。
- 实时数据:比如实时在线用户列表、游戏的实时排行榜、直播间的弹幕等,需要极低延迟的场景。
别把它们看成是“二选一”的竞争对手,而应该视为“黄金搭档”。用SQL数据库作为可靠的“硬盘”,存放所有重要、核心、需要长期保存的数据;用Redis作为高速的“内存”,存放那些需要被快速访问、可以容忍少量丢失的临时数据或缓存。 这样组合起来,既能保证数据的可靠性,又能获得极致的性能,是现代应用架构中非常普遍和有效的做法。

本文由盘雅霜于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75378.html