Redis里zadd到底怎么用才能真提升性能,聊聊zadd和redis那些事儿

说到Redis里的zadd,很多人觉得不就是往有序集合里加个成员和分数嘛,命令那么简单,有啥性能可谈的?但你要是真这么想,可能就错过了Redis给你准备的“性能大礼包”了,今天咱就抛开那些晦涩的术语,聊聊怎么把zadd用得飞起,以及它背后一些有趣的事儿。
首先得明白,zadd的核心是啥?它管的是一个带分数的集合,成员不能重复,但分数可以一样,它最牛的地方在于,既能按成员快速查(像普通的Set),又能按分数排序范围查,这个特性让它成了排行榜、延迟队列、时间轴这些场景的“天选之子”。
那怎么用zadd才能真提升性能呢?关键就在“批量”这两个字上,根据Redis官方文档和大量实践总结,最立竿见影的性能提升技巧,就是避免在循环里一条一条地执行zadd,而是把多个成员-分数对攒起来,用一次zadd命令批量添加。
你想啊,每一条命令从你的客户端发到Redis服务器,都要经历网络传输、命令解析、执行结果返回这一套流程,这个网络往返的开销(Round-Trip Time, RTT),可能比命令本身执行的时间还长,如果你要插入一万个成员,循环一万次,那光网络等待就浪费了海量时间,但如果你把这一万个成员一次性通过一个zadd命令发过去,ZADD myzset 1 "member1" 2 "member2" ... 10000 "member10000",那么网络开销就只有一次,根据Antirez(Redis之父)在早期博客中的论述,这种管道(pipelining)思想是提升Redis性能的首要法则,而批量zadd正是这一思想的具体应用,这个性能提升是数量级的,可能从秒级降到毫秒级。
除了批量,另一个容易被忽略的点是选择合适的数据编码,Redis为了节省内存,会对有序集合动点“小手术”,当元素数量少且成员体积小时,它会用一种叫ziplist(压缩列表)的紧凑格式来存,这样非常省内存,但当元素超过zset-max-ziplist-entries(默认128)或者某个成员大小超过zset-max-ziplist-value(默认64字节)时,它就会自动转成一种叫skiplist(跳跃表)的数据结构,skiplist查询效率很高,但内存占用会比ziplist大。
这对我们使用zadd有什么启示呢?如果你明知这个有序集合会变得非常大,比如要存几十万会员的积分,那你就不用管它,让它用skiplist好了,追求的是极致的查询速度,但如果你是用来存一些临时性的、数据量不大的东西,比如某个直播间一分钟内的在线用户列表(用时间戳做分数),那你就要注意,尽量让成员名保持简短,别瞎起长名字,这样Redis就能一直用更省内存的ziplist来存储,间接提升了整体性能(因为内存省了,能缓存的数据就多了,速度自然快),这个机制在Redis配置文件中有着明确的说明。
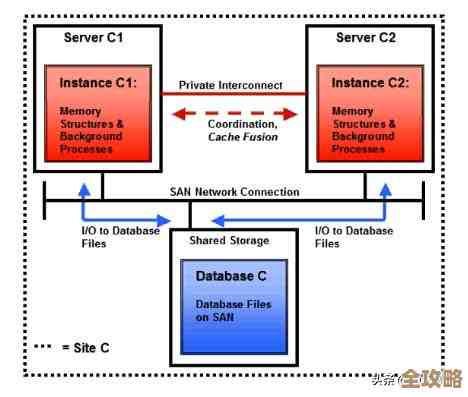
再来聊聊zadd和Redis整体设计那些事儿,Redis是单线程模型的,这意味着它一个核在同一时间只能干一件事,这个设计避免了多线程的锁竞争,让实现变得简单,而且性能依然狂暴,因为它是纯内存操作,但这也带来了一个重要的“规矩”:任何一个命令都不能慢,否则就会阻塞整个服务器。
zadd命令的时间复杂度是O(log(N)),N是集合里的元素个数,这意味着即使集合很大,添加操作也依然非常快,但这里有个潜在的“坑”:如果你一次性批量添加的元素数量实在太庞大了,比如一口气zadd一百万条,这个命令的执行本身还是会消耗可观的CPU时间(虽然还是很快),在这段时间内,Redis就无法处理其他客户端的请求了。“批量”也不是无限制的越大越好,需要根据实际情况找个平衡点,比如每批几千到一两万条,分多次进行,既能大幅减少网络开销,又不会长时间阻塞服务。
别忘了zadd的一些“隐藏技能”,它支持一个叫NX和XX的选项,NX意思是“仅当成员不存在时才添加”,XX是“仅当成员已经存在时才更新”,还有CH选项,它会返回本次操作中被改变的成员数量,包括新增的和分数被更新的,比如你在做排行榜,你只关心分数有没有变化,用ZADD ... CH,就能知道到底有哪些人的排名需要更新,非常实用,这些选项让你用更少的命令完成更复杂的逻辑,本质上也是提升性能的一种方式。
别看zadd命令小,里面的门道可真不少,想让它飞起来:首要秘诀是批量添加,减少网络往返;其次是注意成员大小,利用好编码优化;最后是善用NX/XX/CH等选项,实现更精细化的操作。 理解了这些,你才算真正读懂了Redis设计者的良苦用心,才能让这个高性能的工具在你手里发挥出真正的威力。

本文由畅苗于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/75028.html