聊聊红色数据库里redis那些设计技巧和思路,怎么才能算是最佳实践呢

主要参考自Redis官方文档、经典技术博客如Antirez(Redis创始人)的博文、以及《Redis设计与实现》等综合技术社区共识)
聊聊红色数据库里Redis那些设计技巧和思路,怎么才能算是最佳实践呢?这得从理解Redis的本质开始,Redis不是一个放之四海而皆准的数据库,它核心的优势在于两点:一是把所有数据放在内存里操作,所以速度极快;二是它提供了丰富的数据结构,让你能用更贴近业务逻辑的方式来存储和操作数据,最佳实践的核心,就是围绕这两点扬长避短。
第一,关键在于数据模型的设计,用对数据结构。
很多人误以为Redis就是个简单的键值对存储,把复杂的JSON字符串直接塞进去就完事了,这是最浪费Redis能力的做法,Redis的精髓在于它的数据结构:字符串(String)、列表(List)、哈希(Hash)、集合(Set)、有序集合(Sorted Set)等,最佳实践是,你的业务逻辑需要什么样的操作,就选择最适合的数据结构。
Antirez在早期介绍Redis设计的文章中就强调,数据结构是Redis区别于其他存储系统的灵魂,举个例子,如果要存储用户信息(姓名、年龄、城市),不要把它序列化成一个大字符串存成一个键值对,应该用一个哈希(Hash)结构,把用户ID作为键,用户的各个属性作为这个哈希内部的字段和值,这样做的好处是,你可以单独获取或修改用户的某一个属性(比如只更新年龄),而不需要每次都读取和写入整个用户对象,既节省网络带宽又减少序列化开销。
再比如,要实现一个排行榜,有序集合(Sorted Set)就是天作之合,你直接把成员和对应的分数加进去,Redis天然就帮你维护好了排序,取Top N、查看某个人的排名等操作都非常高效,如果你用关系型数据库或者单纯的值存储,实现同样的功能会复杂和缓慢得多,设计时的第一个思路就是:把你的问题“映射”到Redis的数据结构上。
第二,时刻牢记Redis是内存数据库,要精打细算地使用内存。
内存是昂贵的资源,所以最佳实践里,内存优化是永恒的主题,思路有几个层面:
- 控制键的数量:如果有大量的小对象,考虑使用哈希(Hash)结构把它们聚合起来,Redis官方文档在内存优化部分提到,每个键本身都有一些元数据开销,如果你有1百万个用户,每个用户存成一个独立的键,那么就有1百万个键的开销,但如果把这1百万个用户分成1千个哈希,每个哈希里存1千个用户字段,那么键的数量就骤降到1千个,能节省大量内存,但这需要权衡,因为聚合后操作单个字段可能不如直接操作一个键方便。
- 选择合适的数据类型:比如存储数字,就用Redis的数字类型,而不是字符串类型,因为数字类型存储更高效。
- 设置过期时间(TTL):对于缓存性质的数据,一定要设置过期时间,这是防止内存被无用数据占满最基本也是最重要的手段,思路是,任何临时数据都应该有它的“生命周期”。
第三,持久化策略的选择:在可靠性和性能间找平衡。
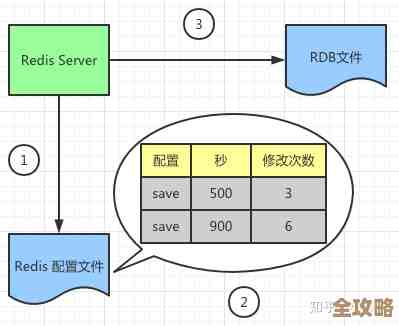
Redis提供了两种持久化方式:RDB(快照)和AOF(追加日志),最佳实践不是二选一,而是理解它们的特点并进行组合。
- RDB:在特定时间点生成整个数据库的快照,优点是文件紧凑,恢复速度快,缺点是可能会丢失最后一次快照之后的数据。
- AOF:记录每一次写操作命令,优点是数据安全性高,最多丢失一秒的数据(如果配置为每秒同步),缺点是文件体积大,恢复速度慢。
根据《Redis设计与实现》中的阐述,常见的思路是同时开启两者,用AOF来保证数据不丢失,作为数据恢复的第一选择;同时定期生成RDB快照,用于备份、快速恢复以及作为AOF重写的基础,这样就在性能和可靠性之间取得了一个不错的平衡。
第四,高可用与扩展性:主从、哨兵和集群。
单点Redis会有故障风险,最佳实践是部署成高可用架构。
- 主从复制(Replication):一个主节点(Master)负责写,多个从节点(Slave)负责读和备份,这实现了读写分离和数据冗余。
- 哨兵(Sentinel):在主从基础上,哨兵是一个独立的进程,它监控主节点是否存活,如果主节点挂了,哨兵会自动从从节点中选举出一个新的主节点,实现自动故障转移,这是实现高可用的常见方案。
- 集群(Cluster):当数据量巨大,单机内存无法容纳时,就需要用集群,集群将数据分片(Sharding)存储在多个节点上,同时具备了高可用和横向扩展的能力,选择集群的时机需要谨慎,因为它增加了复杂性,只有在单机确实无法满足时才应考虑。
第五,一些零散但重要的技巧和思路。
- 避免大键和热点键:一个键对应的值过大(比如一个包含几十万元素的列表),在操作时可能会阻塞Redis较长时间,影响其他请求,同样,一个被极高并发访问的“热点键”也可能成为瓶颈,设计时要尽量拆分大键,对于热点键可以考虑通过增加副本等方式分散压力。
- 管道(Pipeline)和事务:如果需要连续执行多个命令,使用管道可以将多个请求一次性发送,减少网络往返时间,极大提升效率,而事务(MULTI/EXEC)则用于保证一批命令的原子性执行。
- 谨慎使用模糊查询(Keys命令):在生产环境中,避免使用
KEYS *这样的模糊匹配命令,因为当键很多时,它会阻塞服务器,应该使用SCAN命令来增量迭代,虽然慢一些,但不会阻塞服务。
Redis的最佳实践不是一个固定的清单,而是一种设计思路,核心是:深刻理解业务需求,选择最匹配的数据结构;时刻关注内存使用,做好持久化和高可用规划;避免可能导致性能问题的操作,归根结底,就是把Redis用在它最擅长的场景,并按照它的“脾气”来使用它,这样才能让它发挥出最大的威力。

本文由盘雅霜于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74792.html