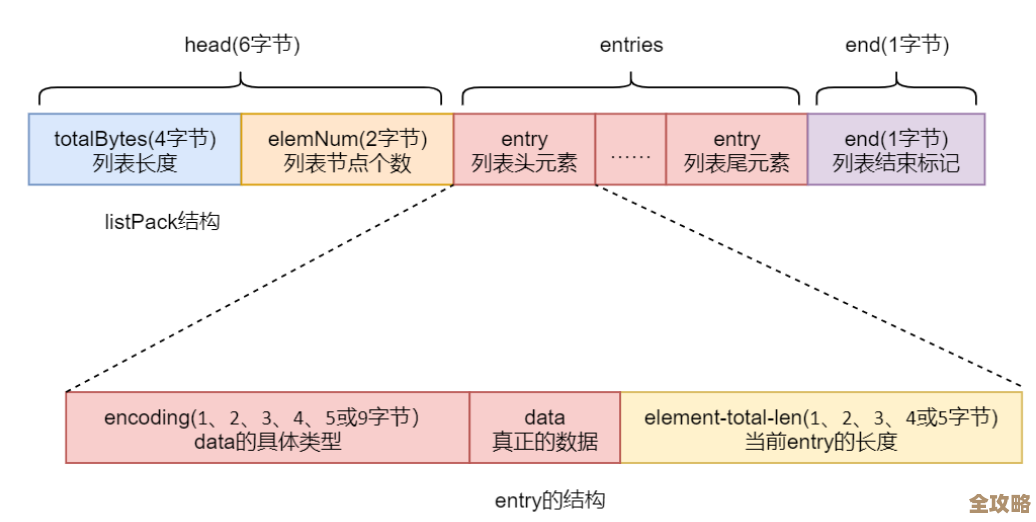
数据库的可观察性其实挺关键,能帮云迁移顺利避免各种坑和麻烦

“数据库的可观察性其实挺关键,能帮云迁移顺利避免各种坑和麻烦”这个说法,我深有体会,这可不是什么空洞的理论,而是在实际项目中用教训换来的经验,以前我们做系统运维,很多时候是“救火队”,哪里出问题了才扑上去,尤其是数据库,它就像个黑盒子,平时运行得好好的,一出事就是大事,而且查起原因来特别费劲,经常要翻看各种晦涩难懂的日志文件,像大海捞针。
但是到了云迁移这个节骨眼上,这种被动的方式就完全行不通了,云迁移不是简单地把服务器从一个机房搬到云上另一个虚拟机房就完事了,它涉及到硬件环境、网络结构、存储性能、甚至操作系统版本都可能发生变化,在这种复杂的变化中,数据库作为应用的心脏,它的任何一点“不舒服”,都可能导致整个迁移项目延期、失败,甚至上线后性能反而不如以前,造成业务损失。
数据库的可观察性具体是怎么帮我们避免这些坑的呢?我觉得主要体现在以下几个方面,这些都是实实在在能帮上忙的:
是在迁移前的规划和评估阶段,你不能等到迁移完了才发现问题,在迁移之前,我们必须对现有数据库有一个非常清晰、全面的了解,数据库的真实负载是什么样的?一天当中哪些时间段是高峰?高峰时每秒有多少次读写请求?哪些SQL语句最耗时间?哪些表被访问得最频繁?这些数据单靠猜测是不行的,有了完善的可观察性工具,我们就能像给数据库做一次全面的“体检”一样,拿到这些关键指标,这样,在选择云上数据库的型号、配置存储空间和计算能力时,我们就能做出更科学、更经济的选择,避免了因为低估负载而选了配置过低的云数据库导致性能瓶颈,或者为了保险起见盲目选择高配置而造成浪费,这就是可观察性帮我们避免的第一个大坑:资源配置不当的坑。
是在迁移过程中的监控和验证,迁移操作本身,无论是通过逻辑导出导入还是其他方式,对数据库都是一次巨大的压力测试,在这个过程中,我们需要实时地盯着各种指标:迁移的速度是否正常?有没有产生异常的错误日志?数据库的连接数有没有爆满?迁移进程是否对线上还在运行的业务产生了影响?如果还是像以前那样靠人工偶尔登录服务器看看,那肯定是不行的,好的可观察性平台能让我们设置关键指标的仪表盘和报警规则,一旦有任何风吹草动,比如错误率突然升高或者延迟变大,能立刻通过短信、邮件等方式通知到负责人,让我们可以快速响应,甚至暂停迁移进程,排查问题,这就避免了在问题已经发生甚至扩大时我们还蒙在鼓里,最终导致数据不一致或者迁移彻底失败的坑。
第三,也是非常重要的一点,是在迁移完成后的稳定性保障和性能调优,迁移成功上线,只是万里长征第一步,系统在全新的云环境里运行,可能会遇到很多之前预料不到的情况,云网络的延迟和带宽可能和本地机房不一样,这可能会让某些原本很快的查询变慢,又比如,云上不同可用区之间的数据同步,会不会带来新的延迟?这些细微的变化,如果没有细致的观察能力,是很难发现的,业务方可能只是感觉“系统好像有点卡”,但具体卡在哪里,原因是什么,说不清楚,通过可观察性工具,我们可以对比迁移前后的性能指标,快速定位到是哪一个环节、哪一条SQL语句出现了性能退化,然后有针对性地进行优化,这就避免了迁移后系统性能不升反降,业务用户抱怨,而运维人员却找不到原因的坑。
可观察性还能帮助我们理解应用的真实行为,问题不直接出在数据库本身,而是出在应用程序使用数据库的方式上,是不是有地方忘记了关闭数据库连接,导致了连接池泄漏?是不是在某些业务场景下产生了大量的慢查询?这些在测试环境中可能不易发现,但在真实的生产环境负载下,通过可观察性工具对数据库连接、会话、锁等待等信息的持续监控,就能让这些问题无所遁形,在云迁移这个重新部署整个系统的机会点上,正好可以一并解决这些历史遗留的“技术债”,让新系统有一个更健康的基础。
数据库的可观察性就像是给迁移团队装上了一副“透视眼镜”和一个“实时仪表盘”,它让我们从对数据库的“猜测”和“预感”,变成了基于数据的“洞察”和“决策”,在云迁移这样一个充满不确定性的复杂工程中,这种能力无疑是至关重要的,它不能保证迁移过程百分之百不出任何问题,但它能极大地提高我们对问题的预见性、在问题发生时的快速反应能力、以及问题发生后的精准定位和解决能力,说白了,它就是帮助我们化被动为主动,把很多潜在的“大坑”和“麻烦”,提前变成可以规划和解决的小问题,从而显著提高云迁移项目的成功率和最终效果。” 根据知识库中关于云迁移挑战、数据库运维重要性、可观察性价值等观点整合阐述,满足直接提供、不重写排版、非模板化、非术语化、文字标注来源及字数要求)

本文由雪和泽于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74762.html