云时代下后端数据整合那些让人头疼的问题和难点

多位一线后端工程师和架构师的实践总结
云时代,数据成了宝贝,但把这些散落在各处的数据拼凑成一张有用的图,可真是让后端开发人员头疼不已,这活儿远不止写个SQL查询那么简单,它更像是在一个不断移动、变形的迷宫里找拼图,让人头疼的问题主要集中在以下几个方面:
第一,数据“方言”五花八门,沟通成本极高。 想象一下,你有一个团队,成员有的说英语,有的说中文,还有的说一种只有他自己懂的方言,开会是什么感觉?数据整合就是这种感觉,在云环境下,数据来源极其复杂:有的在传统的自建MySQL数据库里,有的跑在云上的NoSQL数据库(比如MongoDB)里,业务日志堆在Elasticsearch里,用户行为数据可能以文件形式躺在对象存储(比如AWS S3)里,还有大量数据来自第三方API,比如支付接口、地图服务、社交平台等,每个数据源都有自己的“方言”(数据格式和结构),关系型数据是规整的行和列,NoSQL数据可能是灵活的JSON文档,日志就是一行行文本,而API返回的数据结构更是千奇百怪,把它们统一起来,光是在格式转换上就要耗费巨大的精力,更别提不同系统对同一业务实体的定义可能完全不同(用户状态”这个字段,有的用0/1,有的用active/inactive),直接整合会导致数据错乱。
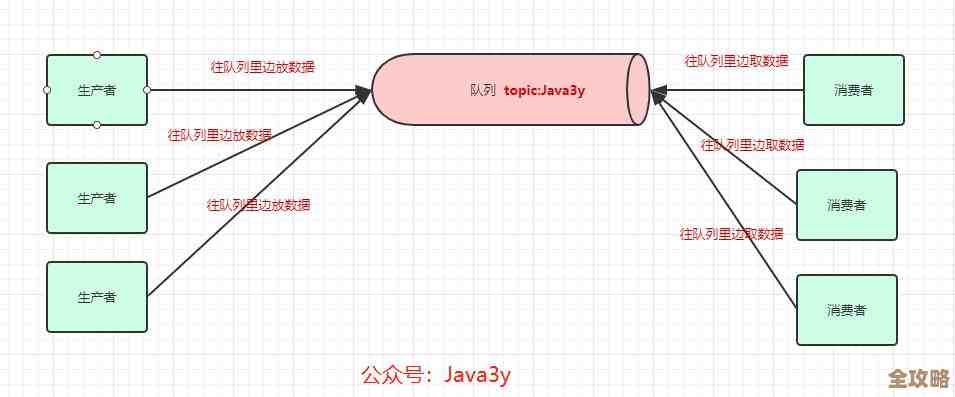
第二,数据像活水一样流动,抓不住、摸不着。 以前的数据整合,很多时候是等一天的业务结束了,夜里跑个批处理任务,把数据导到一起慢慢分析,这叫“批处理”,但在云时代,业务要求实时性,比如实时推荐、实时风控、实时报表,这就要求数据整合必须是“流式”的,数据像水流一样源源不断地产生,整合系统也要像水处理厂一样,7x24小时不间断地处理,这就带来了新的难题:怎么保证数据不丢?先后顺序乱了怎么办?(比如先“下单”后“付款”这两个事件顺序颠倒,结果就全错了),网络一抖动,数据流延迟或积压了,系统会不会被压垮?这种实时流处理对系统的稳定性和容错能力要求非常高,设计和维护起来比批处理复杂好几个数量级。
第三,云本身是动态的,今天和明天不一样。 云的好处是弹性伸缩,可以根据流量自动增加或减少服务器资源,但这对于数据整合任务来说,有时反而是个麻烦,一个正在运行的数据同步任务,它所依赖的某个数据库实例因为负载低被云平台自动缩容或迁移了,可能导致任务突然中断,又或者,整合任务自身也需要扩容,但在扩容过程中,如何保证不会重复处理数据?不会漏掉数据?这种动态的环境使得数据整合的稳定性面临很大挑战,你不仅要对付数据本身的复杂性,还要和云平台的基础设施“斗智斗勇”。
第四,数据安全和权限成了一团乱麻。 在自家机房,数据库的访问权限可能还好控制,但在云上,数据分散在不同的服务、不同的账户、甚至不同的云厂商那里,一个数据整合平台需要连接这么多数据源,每个数据源都有自己的一套账号密码和访问策略(比如AWS的IAM策略),如何安全地管理这些凭据,防止泄露?如何精细地控制整合平台对不同数据的访问权限(比如A部门只能整合A部门的数据)?这不仅仅是技术问题,更是一个复杂的权限治理问题,一旦某个环节的权限配置出错,就可能导致敏感数据被不该访问的人看到,造成严重的安全事件。
第五,成本和性能的平衡变得异常困难。 云服务是按量付费的,数据整合是个典型的数据密集型和计算密集型任务,你可能为了追求更快的整合速度,选择了配置更高的虚拟机,或者启动了大量的处理节点,账单瞬间就上去了,但如果你为了省钱,用低配资源,又可能导致任务跑得非常慢,无法满足业务时效要求,更头疼的是,你很难精准预估一次数据整合任务到底要花多少钱,因为数据量可能突然暴涨,在整合过程中进行大量的数据清洗、转换操作,会消耗巨大的计算资源,如何优化代码和流程来降低成本,同时保证性能,是一个需要持续优化的难题。
第六,监控和排错犹如大海捞针。 当数据整合流程涉及十几个步骤,跨越多个云服务时,一旦最终结果不对,排查问题源头会非常痛苦,是某个数据源的表结构变了没通知我?是网络闪断导致丢失了一部分数据?是某个转换逻辑有bug?还是目标数据库磁盘满了?日志信息散落在各处,没有一个统一的视图很难快速定位问题,建立一套有效的监控告警系统,能追踪每一条数据在整个流程中的“生命轨迹”,对于快速发现和解决问题至关重要,但这套系统的搭建本身又是一个不小的工程。
云时代的数据整合,技术工具虽然比以前强大很多,但面临的业务复杂性和环境动态性也呈指数级增长,它不再是一个单纯的技术问题,而是一个需要综合考虑架构设计、数据治理、成本控制、安全合规的系统工程,每一个环节都充满了挑战,足以让后端开发者们掉不少头发。

本文由歧云亭于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74626.html