那些Oracle RAC维护命令,平时不注意可真麻烦,得看看才行

来源主要是基于Oracle官方文档中关于集群件管理和数据库管理的部分,以及一些资深DBA的实践经验分享。
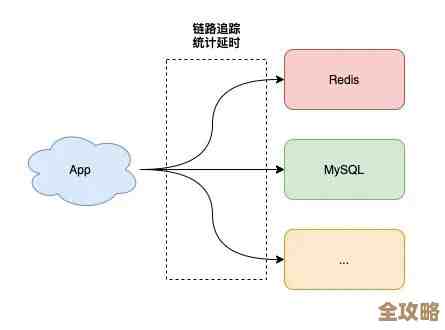
你得知道,RAC环境比单机数据库多了一个集群管理软件,以前叫Oracle Clusterware,现在通常被称为Grid Infrastructure,你的维护工作也得分两部分看:一部分是管集群本身的,另一部分才是管数据库的,很多时候问题出在集群层面,但你光在数据库里捣鼓是没用的。
查看集群状态是第一步,也是最基础的
你不能一上来就sqlplus连进去查数据库,得先确保集群是健康的,最常用的命令是crsctl。
crsctl check cluster 或 crsctl check cluster -all,这个命令会快速检查当前节点或所有节点上集群服务的整体状态,如果这里报错了,那后续的数据库操作很可能都会有问题,有时候你觉得数据库连不上,其实是底层集群服务挂了,先用这个命令看一眼能省很多事。
更详细的查看是用 crsctl status resource -t,这个-t选项会用树形结构显示所有资源的状态,非常直观,你能看到网络、磁盘(表决盘)、扫描IP、监听器、数据库实例等每一个资源的详细情况,是在线、离线还是未知状态,当某个实例莫名其妙挂掉的时候,这是第一个要跑的命令,它能帮你快速定位是哪个环节出了岔子。
管理集群资源的启动和停止
在RAC里,你不能像单机一样随便用shutdown immediate关数据库,更不能直接杀进程,要用集群的方式来管理。
停止数据库的正确姿势是:srvctl stop database -d <数据库名>,这会优雅地停止所有节点上的数据库实例,如果你只想停其中一个实例,比如要在节点1上做维护,可以用 srvctl stop instance -d <数据库名> -i <实例名>。
启动也是类似的,srvctl start database -d <数据库名>,但这里有个容易忽略的点:有时候你用srvctl启动数据库,发现实例没起来,或者监听器没起来,这时候你可能需要检查一下资源的自动启动属性,用 crsctl status resource <资源名> -p 查看资源的详细属性,关注AUTO_START这一项,如果它是never,意味着集群重启后这个资源不会自动启动,需要你手动敲命令,你可以用 crsctl modify resource <资源名> -attr AUTO_START=always 来修改它,避免以后忘记。
网络相关的问题排查
RAC严重依赖网络,网络一出问题就是大问题,除了集群的私有网络,还有一个重要的概念是SCAN(扫描IP),客户端通常连接的是SCAN IP,而不是某个具体节点的IP。
检查SCAN监听器的状态很重要:srvctl status scan_listener,如果SCAN监听器挂了,即使所有节点实例都正常,客户端也可能无法连接。

还有节点的虚拟IP(VIP),如果VIP飘移了,也会导致连接中断,用 crsctl status resource -t | grep vip 来查看各个节点的VIP状态是否正常,有时候网络抖动可能导致VIP短暂失效又恢复,期间就会产生连接错误日志。
表决盘(Voting Disk)和集群文件(OCR)的维护
这是集群的心脏和大脑,平时不动它们,但一旦出问题就是灾难性的,定期检查它们的备份和状态是必须的。
查看OCR备份:ocrconfig -showbackup,系统会自动备份OCR,但最好确认一下备份确实存在并且分布在不同的磁盘上,同样的,表决盘的备份信息可以用 crsctl query css votedisk 来查看其位置和状态。
切记,对OCR和表决盘的任何修改操作(比如恢复、替换)都必须极度小心,并且最好在有经验的DBA指导下或在测试环境充分演练后进行,平时就用查看命令确认它们健康就行。
一些诊断和日志查看命令
出问题了怎么办?看日志,但RAC的日志分布在各个节点上,你得知道去哪找。

集群本身的日志通常在$GRID_HOME/log/<节点主机名>目录下,比如alert.log文件会记录集群级别的告警信息。
数据库实例的日志和单机一样,在$ORACLE_BASE/diag/rdbms/<数据库名>/<实例名>/trace目录下,看alert_<实例名>.log。
有一个很方便的集群诊断工具叫diagcollection.pl,你可以用这个脚本一次性收集所有节点上集群相关的日志,打包成一个压缩包,方便发给Oracle支持进行分析,命令大概长这样:$GRID_HOME/bin/diagcollection.pl --collect --crshome $GRID_HOME,这个命令平时可能想不起来,但真需要找Oracle开服务请求(SR)时,它能帮你大忙。
容易被忽略的“小”命令
olsnodes:这个命令简单直接,就是列出集群中的所有节点名称,看起来简单,但在脚本里判断当前在哪个节点上运行时很有用。
crsctl get node role status:查看节点当前的角色状态,比如是否是Hub节点(在Extended Distance RAC等架构中很重要)。
asmcmd:RAC的数据库文件通常放在ASM磁盘组里,你需要熟悉一些基本的asmcmd命令,比如asmcmd lsdg查看磁盘组空间使用情况,asmcmd ls查看目录等,空间满了可是个大麻烦。
维护Oracle RAC,思路要从单机的“点”切换到集群的“面”,任何一个操作都要考虑到它对整个集群的影响,这些命令就像是你的工具箱,平时可能不觉得怎样,但遇到紧急情况时,能熟练准确地拿出合适的工具,就能快速解决问题,避免长时间的业务中断,定期在测试环境练习这些命令,熟悉它们的输出,是非常有必要的。
本文由瞿欣合于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74441.html