搞懂MSSQL数据库死锁到底咋回事,教你一步步解开那些纠结的锁链

整理自CSDN博客《搞懂MSSQL数据库死锁到底咋回事,教你一步步解开那些纠结的锁链》、腾讯云开发者社区相关技术文章以及一些DBA的实践经验分享)
咱今天就来唠唠这个让很多搞数据库的朋友头疼的问题——MSSQL死锁,你可以把它想象成一条双向单车道上发生的尴尬事:两辆汽车(两个数据库事务)迎面开来,都想通过,但路太窄(资源互斥),结果谁都不肯倒车(都不释放已持有的锁),就这么脸对脸卡死了,谁也动不了,数据库系统一看这架势,没办法,只能“大义灭亲”,挑一个“倒霉蛋”(通常认为回滚代价较小的那个事务)强行终止掉,让另一个事务先过,这就是死锁最形象的比喻。
死锁到底是咋形成的?
说白了,死锁的核心就是四个条件同时满足(来源广泛引用的操作系统/数据库原理中的“死锁四必要条件”):
- 互斥条件:一个资源(比如一条数据记录)一次只能被一个事务锁住,别人想用就得等着。
- 请求与保持条件:事务A已经锁住了资源X,但它还不满足,又想去锁资源Y,在等着Y的时候,它对X的锁死死攥着不放手。
- 不剥夺条件:事务已经占有的锁,不能被其他事务强行抢走,只能等它自己主动释放。
- 循环等待条件:这事有点绕,事务A等着事务B释放某个锁,同时事务B又等着事务A释放另一个锁,形成了一个“你等我,我等你”的循环,就像两个人吵架:“你先道歉!”“不,你先道歉!”,结果僵住了。
在MSSQL里,常见的死锁场景比如:
- 场景一:事务A先更新了表里的第1行(锁住行1),然后想去更新第10行;事务B更新了第10行(锁住行10),然后想去更新第1行,俩事务互相等对方手里的锁,死锁了。
- 场景二:事务A按顺序先锁表X再锁表Y;事务B却反过来,先锁表Y再锁表X,虽然最终都要锁两个表,但顺序不一致,也可能在中间环节形成循环等待。
当死锁发生,MSSQL咋办?
MSSQL肚子里有个专门的“侦探”叫死锁监视器(Lock Monitor),它不会闲着,会定期检查系统里有没有陷入这种循环等待的“冤家”,一旦被它逮到,它不会和稀泥,会立刻出手“裁决”,选其中一个事务作为牺牲品(Victim),把它干掉(回滚这个事务的所有操作),并抛出1205错误,这样,另一个事务就能继续执行下去了,选谁牺牲不是随便点的,一般会挑那个估计回滚起来开销最小、干活最少的事务“开刀”。

咱们怎么一步步解开这些锁链?
光知道原理不行,关键是怎么解决和避免,事后诸葛亮和事前预防都得做。
第一步:逮住它——开启死锁监控
想解决死锁,首先得知道它在哪儿发生、为啥发生,MSSQL提供了工具来记录死锁的“案发现场”。

- 最常用的是开启跟踪标志:比如在SQL Server Management Studio (SSMS)里,可以运行
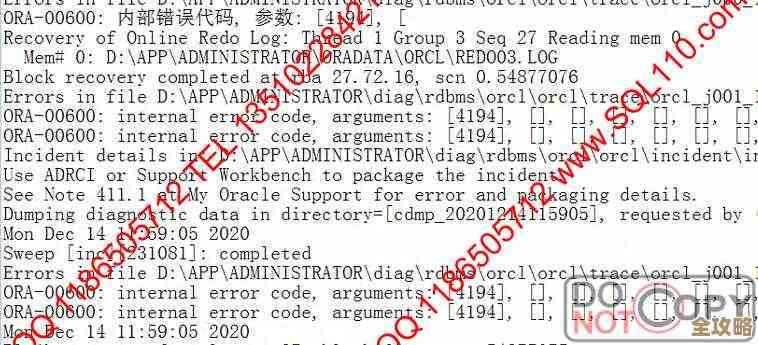
DBCC TRACEON (1222, -1)或DBCC TRACEON (1204, -1),这两个标志会让MSSQL把死锁的详细信息写到错误日志里。(来源:MSSQL官方文档及多种故障排查指南) - 更强大的工具:SQL Server Profiler 或扩展事件 (Extended Events),你可以创建一个跟踪(Trace)或扩展事件会话,专门捕获“Deadlock graph”事件,这个“死锁图”非常直观,像一张关系图,能清晰显示出是哪些会话、在争抢哪些资源、谁等了谁,是分析死锁根源的“神器”。(来源:MSDN技术文档)
第二步:分析它——看懂死锁报告
拿到死锁图或日志后,重点看:
- 受害者是谁? (牺牲的进程ID)
- 参与死锁的各个事务都在执行什么SQL语句? (这是关键!)
- 他们分别已经锁住了什么资源(哪张表、哪几行)?又在等待什么资源?
- 资源的标识符,搞清楚争抢的具体是哪个索引键、哪一页。
第三步:解决与预防它——从根儿上动手
分析出原因后,就可以对症下药了:
- 保持访问顺序一致:这是最重要的一条,如果多个事务都要操作多个表或数据,尽量约定一个固定的顺序(比如都按A表、B表、C表的顺序访问),这样就从源头上避免了循环等待,就像所有车都约定只从一边走,就不会对头卡住。
- 缩短事务长度,尽快提交:事务拖得越长,持有锁的时间就越久,跟别人冲突的概率就越大,能快速做完的操作就赶紧COMMIT,别磨蹭,不要把一些不必要的操作(比如用户确认、复杂的计算)放在事务里面。
- 降低隔离级别:如果业务允许,可以考虑使用低一点的隔离级别,比如读已提交(Read Committed),它比可重复读(Repeatable Read) 或可序列化(Serializable) 持有的锁要少、时间要短,但要注意可能带来的脏读、不可重复读等问题。
- 使用乐观并发控制:比如使用行版本控制(Read Committed Snapshot Isolation 或 Snapshot Isolation),让读操作不用加共享锁,减少锁冲突,但这会增加TempDB的负担。
- 精细化的锁提示:在极少数情况下,可以在SQL语句里谨慎地使用锁提示,
WITH (NOLOCK)来跳过锁(但可能读到脏数据,风险大),或者WITH (UPDLOCK)在查询时提前加更新锁,避免后续升级锁时冲突。但这种方法要非常小心,容易引入新问题。 - 避免长时间的用户交互:千万不要在事务中间弹出个窗口等用户输入,这段时间锁一直占着,简直是死锁的“最佳助攻”。
对付死锁,核心思路就是:先监控捕获,再精准分析,最后通过规范编程习惯(特别是访问顺序和事务长度)来预防,它就像数据库系统的“交通事故”,只要大家(各个事务)遵守“交通规则”,就能极大减少发生的概率。
本文由帖慧艳于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74063.html