网易数据运河系统的设计思路和实际应用分享,聊聊它怎么帮忙处理大规模数据流

网易数据运河系统,听起来名字挺形象的,其实它就是网易为了解决自身海量数据流动问题而自主研发的一套数据同步工具,你可以把它想象成真正意义上的“数据运河”,就像古代京杭大运河把南方的物资源源不断地运到北方一样,这套系统的作用就是把数据从各个源头(比如用户产生的日志、业务数据库等)高效、稳定地“运输”到需要它们的目的地(比如数据仓库、实时计算系统等)。
为什么要造这个“运河”?—— 解决的问题
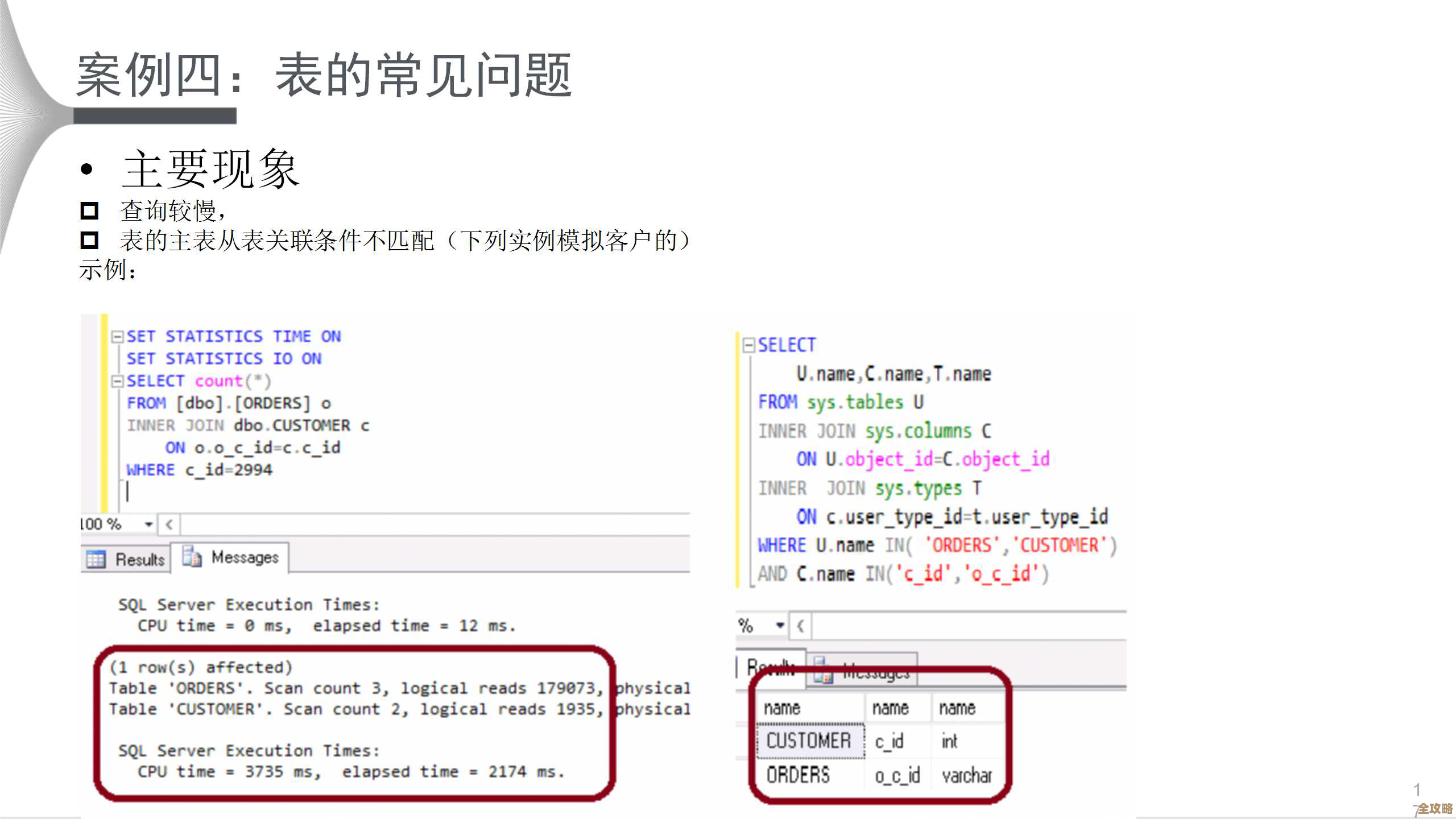
网易的业务非常多,游戏、电商、音乐、邮箱等等,每个业务都会产生巨量的数据,在早期,他们可能也用一些开源的工具来做数据同步,比如阿里的Canal(用于数据库增量日志同步)或者Apache的Flume(用于日志收集),但随着数据量越来越大,业务场景越来越复杂,这些开源工具暴露了一些问题。
根据网易大数据团队的分享,他们主要面临以下几个痛点:
- 数据源多样且复杂:数据不仅来自MySQL、Oracle这类关系型数据库,还有大量的应用日志、前端埋点日志等,不同的数据源需要不同的采集工具,维护成本高。
- 规模巨大,性能要求高:每天要处理的数据量是万亿级别的,峰值流量非常大,这就要求系统必须有极高的吞吐量和低延迟,不能成为数据流中的瓶颈。
- 对数据一致性要求极高:尤其是在金融、电商等场景下,数据绝对不能丢,顺序也不能乱,比如用户支付了一笔订单,这个记录必须准确无误地同步到下游,漏一条或者顺序错了都可能引发大问题。
- 运维监控要到位:这么大规模的系统,如果出了问题不能快速发现和定位,那将是灾难性的,需要非常完善的监控告警体系。
正是因为这些开源工具无法完全满足他们苛刻的业务需求,网易才决定自己动手,打造一个更趁手的“兵器”。
“运河”是怎么设计的?—— 核心设计思路
网易数据运河系统的设计思路,用大白话讲,可以概括为“一个核心目标,两大关键模块,多种可靠性保障”。
一个核心目标就是:像运河一样,让数据流动起来既“量大管饱”又“精准无误”。

为了实现这个目标,系统主要分成了两大部分,有点像运河的“上游码头”和“下游河道”:
-
采集端(Collector)—— 负责从源头“装货”
- 这部分是部署在数据源侧的,针对不同的数据源,它有对应的“适配器”,比如对于MySQL,它会伪装成一个MySQL的从库,实时读取数据库的binlog(二进制日志,记录了所有数据变更);对于日志文件,它会实时监控文件的新增内容。
- 它的设计重点是轻量化和低侵入,尽量少占用业务数据库的资源,不能影响线上业务的正常运行,它要能精确记录自己读取到的位置(比如binlog的位点、日志文件的偏移量),这样即使重启了,也能从断点继续工作,防止数据丢失。
-
传输与处理端(Server)—— 负责“运输”和“初步加工”
- 采集端把数据“捞”上来之后,会发送给Server集群,这个集群是分布式的,可以水平扩展,以此来应对巨大的数据流量。
- Server层做的事情很重要:
- 路由和转发:根据配置好的规则,把数据分发到不同的下游系统,比如把游戏日志发到A集群,把电商日志发到B集群。
- 数据解析和格式化:把从不同源头来的、格式各异的数据(比如binlog的二进制格式、各种日志文本格式)统一解析成一种内部定义好的、标准化的数据格式(比如JSON或Avro),这为后续的处理提供了极大的便利。
- 有限的清洗和转换:可以做一些简单的数据过滤、字段脱敏(比如把手机号中间几位变成*号)等操作。
- 可靠性保障:这是设计的重中之重,系统采用了多副本机制,数据在内存中处理的同时,会持久化到本地磁盘,并且同步到远端的存储(如HDFS)做备份,确保即使某台机器宕机,数据也不会丢,通过严格的顺序保证机制,确保比如同一个数据库主键的更新事件,在下游收到的顺序和它们在源端发生的顺序是完全一致的。
“运河”实际在干嘛?—— 实际应用场景

这套系统在网易内部支撑了非常多的业务,可以说是他们数据体系的“大动脉”。
-
实时数据仓库的血液供应:这是最经典的应用,过去数据仓库的数据更新往往是每天一次(T+1),比如今天看昨天的数据,有了数据运河,业务数据库的任何变更,几乎在秒级就能同步到数据仓库里,使得实时数仓成为可能,业务方可以随时看到当前时刻的销售情况、用户活跃度等,决策速度大大加快。
-
搜索推荐系统的“新鲜食材”:比如网易云音乐的歌单更新、新闻客户端的新闻上线,这些信息需要立刻被搜索到或用于推荐计算,数据运河能把这种“新品上架”的信息实时同步给搜索和推荐引擎,让用户总能接触到最新最热的内容。
-
用户行为分析的基石:APP或网页上的用户点击、浏览、停留时长等行为日志,通过数据运河被实时收集起来,流入像Flink这样的实时计算引擎,这样就可以实时分析用户画像、做异常流量监控、或者触发一些实时的营销活动(比如用户浏览某个商品超过30秒,自动推送一张优惠券)。
-
数据库异地同步和备份:除了供给大数据平台,数据运河本身也是一个强大的数据库同步工具,可以用它来做跨地域的数据灾备,或者把线上数据库的数据同步到线下的查询库,分担主库的压力。
网易数据运河系统的设计思路源于对大规模数据流处理中“高可靠、低延迟、高吞吐、易扩展”这几点核心需求的深刻理解,它不是一个简单的工具替换,而是一套端到端的解决方案,通过将数据采集、传输、轻量级处理等环节无缝衔接并高度可靠化,它成功地让数据在网易庞大的业务生态中顺畅地流动起来,成为了支撑其各项实时化、智能化业务背后的无名英雄。
本文由雪和泽于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74060.html