Redis性能到底哪里强,聊聊它比Map快的那些细节和原因

最核心的一个区别就是“单线程”与“多线程”的迷思,很多人一听说Redis是单线程的,第一反应可能是:“这不会成为性能瓶颈吗?” 这正是Redis高明的地方,它的核心网络模型和键值读写是由一个线程来处理的,这样做最大的好处就是彻底避免了多线程带来的竞争条件和锁的开销,你想啊,Java的HashMap本身不是线程安全的,如果多个线程同时读写,数据就乱套了,所以要用ConcurrentHashMap这类线程安全的Map,它们内部用了各种复杂的锁机制(比如分段锁),加锁、释放锁这个操作本身是有成本的,而且在线程竞争激烈的时候,线程还会被挂起、等待,这都会消耗大量的CPU时间,Redis直接用单线程干这件事,所有操作都是顺序执行的,像排队一样,没有锁的烦恼,CPU不用把时间浪费在线程调度和锁竞争上,可以全心全意处理请求,这就好比一个收银台,虽然只有一个收银员(单线程),但他手脚麻利,心无旁骛,效率可能比好几个互相碍事、需要不断协调的收银员(多线程竞争)还要高,Redis在新版本中也引入了多线程来处理一些后台任务和网络I/O,但其核心的内存读写命令处理依然是单线程的,这是它保持强一致性和避免竞争的关键。
Redis的数据完全存储在内存中,这是它快如闪电的根本原因,内存的读写速度是纳秒级别的,而机械硬盘是毫秒级别,差了十万八千里,即使是SSD固态硬盘,其随机读写的速度也远远无法和内存相比,我们平常写的程序里,Map的数据也是放在内存里的,这一点上看似一样,但关键在于,当你的Java程序重启后,Map里的数据就全没了,而Redis作为一个独立的进程,它守护着这片内存数据,除非服务器断电,否则数据会一直存在,这就使得Redis可以作为一个高性能的、持久化的共享数据源,供多个应用程序共同访问,普通的Map只是进程内缓存,生命周期和应用程序绑定。
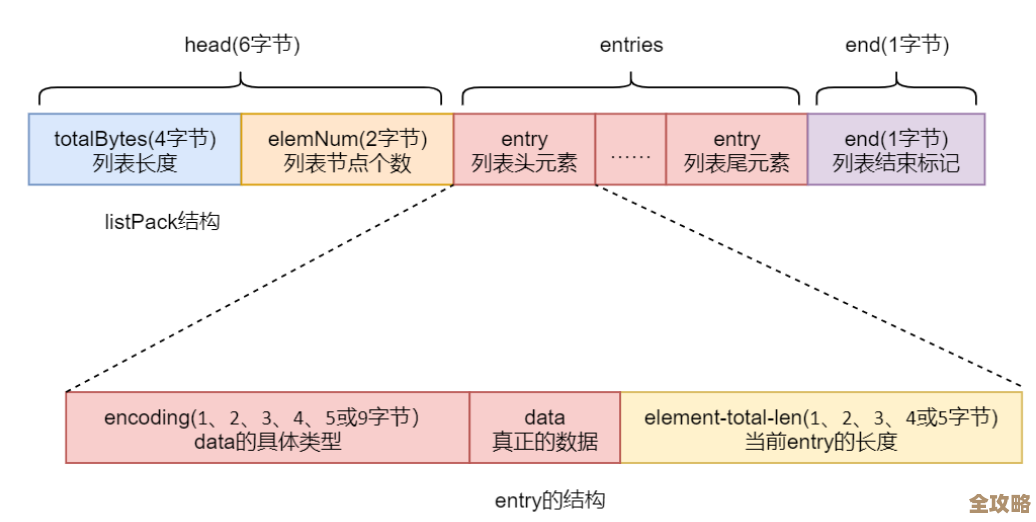
第三,高效的数据结构,Redis可不是简单的键值对存储,它的值可以是多种数据结构,比如字符串(String)、列表(List)、哈希(Hash)、集合(Set)等,这些数据结构都不是凭空设计的,而是针对不同的使用场景做了高度优化,比如它的哈希(Hash)结构,在存储对象时,相比将整个对象序列化成JSON字符串再存储,可以更高效地存取对象的单个字段,节省内存和网络带宽,再比如它的跳跃表(SkipList)实现有序集合(Sorted Set),能够实现高效的区间查询,这些底层数据结构的实现,追求的是极致的性能,可能比编程语言自带的标准库实现得更快。
第四,I/O多路复用,这是Redis单线程模型能处理海量网络连接的关键技术,单线程的Redis如何同时应对成千上万个客户端的连接请求呢?它不会为每个连接都创建一个线程,而是使用I/O多路复用技术(在Linux上通常是epoll),这个技术允许Redis的这个单线程“监听”所有连接上的事件(比如哪个连接有数据可读了),当某个连接有请求到达时,epoll会通知Redis的主线程,主线程再去处理,这样,这个单线程就能高效地管理大量的网络连接,而不会因为等待某个连接的I/O操作而阻塞住,这就像一个高效的餐厅服务员,他不需要一直站在一个桌子旁等客人点菜(阻塞),而是同时照看多个桌子,哪个桌子举手示意,他就过去服务,最大化了自己的工作效率。
还要提一下系统层面的优化,Redis的代码非常简洁高效,它尽量避免不必要的系统调用和上下文切换,它采用了内存预分配和惰性删除等策略,比如当一个字符串需要扩容时,Redis不仅会分配当前需要的空间,还会多分配一些预备着,以减少后续修改时再次分配内存的开销(类似于Java ArrayList的扩容机制),删除数据时,也可能先标记为删除,后续再异步回收,避免大Key删除时导致的服务器短暂停顿。
Redis比Map快,不是一个单一原因造成的,而是一个系统工程,它用单线程模型避免了锁竞争,用纯内存访问保证了基础速度,用优化的数据结构提升了操作效率,用I/O多路复用支撑了高并发连接,再辅以各种系统级的优化技巧,而普通的Map,只是一个进程内的、缺乏持久化、没有考虑网络并发访问的数据结构,把Redis理解成一个经过深度优化的、具备网络能力和持久化能力的“超级Map”,或许更能理解其性能强大的根源。

本文由度秀梅于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74025.html