Redis集群服务稳定性怎么搞,治理那些事儿和提升的路子

关于Redis集群服务稳定性怎么搞,治理那些事儿和提升的路子,我们可以从一些大型互联网公司的实践和公开分享中总结出一些非常实在的经验,这些经验的核心思想很简单:别等出了问题再救火,要把功夫花在平时,用一套系统性的方法去预防、发现和解决问题。
稳定性的基石是“防患于未然”,也就是容量规划和资源隔离。
根据阿里云开发者社区和美团技术团队的相关文章,很多线上故障的根源其实是资源用尽了,某个业务的突然爆发式增长,或者一个没写好的查询命令,就可能拖垮整个Redis集群,第一件要紧事就是做好容量规划,不能等到内存使用率冲到90%以上了才想起来要扩容,要设定一个预警线,比如内存使用率到了70%或者连接数达到某个阈值,监控系统就要提前告警,给运维人员留出充足的时间去处理,这就像给水池加水,不能等到见底了才开水龙头。
资源隔离非常重要,最好不要把公司里所有业务的数据都塞进一个巨大的Redis集群里,一旦这个“巨无霸”集群出问题,所有业务都会瘫痪,更常见的做法是,根据业务的重要程度和流量特点,拆分成多个独立的、规模小一些的集群,把核心的交易数据和普通的用户缓存分开,这样,即使非核心的集群出了问题,也不会影响到核心业务,这就像轮船的防水舱,一个舱室进水了,船不至于沉没。

治理的关键在于“看得清,管得住”,也就是监控、告警和规范。
光有规划还不够,必须得有“火眼金睛”来实时盯着集群的一举一动,监控不能只看最基本的内存、CPU使用率,根据腾讯云数据库和字节跳动技术团队的经验,一些更细致的指标至关重要。慢查询:哪些命令执行得特别慢,它会像高速公路上的事故车一样,堵住后面的所有请求。大Key:一个Key对应的Value特别大,不仅占用大量网络带宽传输,在删除或过期时还可能引起服务短暂停顿。热Key:某一个Key被超高并发地访问,所有的请求都打到了集群中的某台机器上,导致这台机器不堪重负,形成瓶颈。
发现了这些问题,就要有相应的治理手段,对于慢查询,要优化业务代码,避免使用像KEYS *这样的危险命令,对于大Key,要进行拆分或者压缩,对于热Key,可以通过在程序端做本地缓存,或者使用Redis的集群版本来将热Key复制到多个节点上,分散压力,这些治理动作,需要形成明确的开发规范,让所有使用Redis的程序员都清楚什么是好的实践,什么是绝对不能碰的红线。

提升稳定性的路子是“拥抱自动化,为失败做准备”。
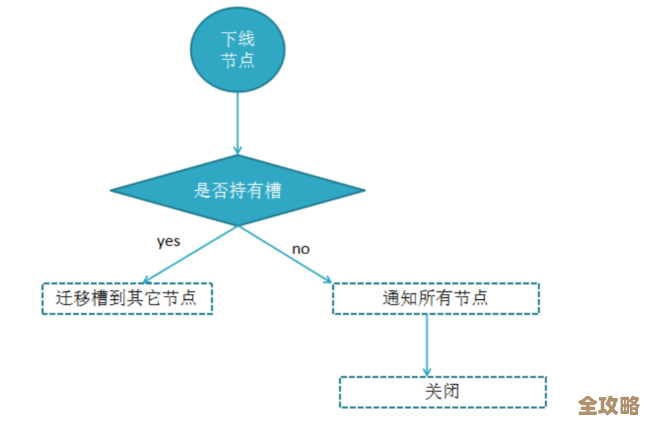
人工操作既慢又容易出错,所有日常操作都应该尽可能自动化,故障自动切换(Failover)、自动扩缩容、自动备份和数据恢复,当某个主节点宕机时,集群应该能自动将一个从节点提升为主节点,并通知客户端连接到新的主节点,这个过程对业务来说应该是无感知或者影响极小,这需要一套成熟的运维平台来支撑。
必须有一个清醒的认识:任何系统都不可能100%不出故障。“韧性”比追求绝对的“稳定”更重要,这意味着,除了让Redis本身更健壮,还要在设计业务系统时,就想好万一Redis完全不可用了怎么办,是否可以降级到直接查询数据库?虽然性能会变差,但至少保证了核心流程能跑通,定期进行“混沌工程”演练,比如在业务低峰期,主动模拟一台Redis节点宕机,检验整个系统是否真的能如预期那样自动恢复和降级,通过这种主动的“破坏性”测试,才能发现系统中隐藏的脆弱点,并加以修复。
提升Redis集群稳定性不是一蹴而就的,它是一个持续的过程,核心就是三件事:事前规划好容量和隔离,事中通过精细化监控和规范做好治理,事后(或者说永远)依靠自动化和容灾设计来兜底。 这套思路来源于众多一线互联网公司在无数次真实故障中总结出的经验和教训。
本文由符海莹于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/74002.html