Redis里用Map命令查数据,感觉挺方便的,就是怎么用才高效呢?

“Redis里用Map命令查数据,感觉挺方便的,就是怎么用才高效呢?”这个问题问得特别好,Redis的Hash类型(也就是你提到的Map)确实是使用最频繁的数据结构之一,用好了事半功倍,用不好反而会成为性能瓶颈,下面这些方法都是从实际使用经验和Redis官方最佳实践中总结出来的,咱们一条一条说。
第一,关键中的关键:别把整个大Map当单个键来用。
这是新手最容易掉进去的坑,比如你要存一个用户信息,有用户ID、姓名、年龄、城市、签名等等几十个字段,如果你图省事,把一个包含所有字段的大JSON字符串存成一个键值对,set user:10001 '{"name":"张三", "age":30, ...}',那就要出问题了。
为什么不好呢?当你只需要修改用户的年龄时,你不得不先把整个JSON字符串取出来,在程序里解析成对象,修改年龄属性,再序列化成JSON字符串,最后整个写回Redis,这个过程涉及一次网络读取、一次网络写入,还有客户端的序列化和反序列化开销,如果这个对象很大,开销非常可观,这个写操作是覆盖式的,并发情况下还可能丢失其他客户端的修改。
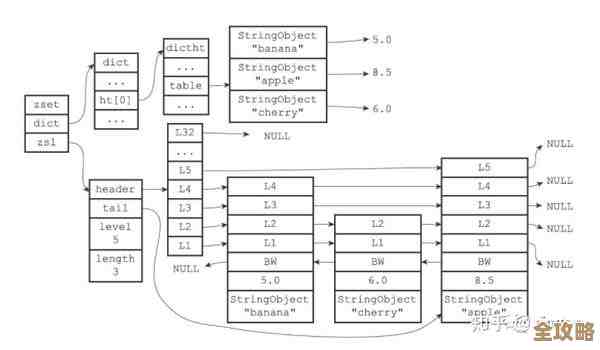
正确的做法是使用Hash,用 hset user:10001 name "张三" age 30 city "北京" 这样的命令,这样,每个用户的详细信息被存储为一个Hash,用户ID作为键名的一部分(user:10001),当你只想改年龄时,直接一条 hset user:10001 age 31 就完成了,只通过网络发送这一个修改,精准高效,Redis内部的操作也非常快。(来源:Redis官方文档关于Hash数据类型的说明)
第二,学会批量操作,减少网络往返次数。
Redis的快,一部分得益于它的内存存储,另一部分就在于它减少了网络通信的开销,一条一条地执行命令,网络延迟会成为最大的敌人,比如你要初始化一个用户的所有信息,如果用循环一次次调用 hset,效率很低。

这时候就要用批量命令,Redis为Hash提供了 hmset(旧版本,但依然常用)或直接使用 hset 支持多字段设置(新版本)。hmset user:10001 name "张三" age 30 city "北京",这一条命令就能设置多个字段,只发生一次网络往返,同样,读取多个字段时,使用 hmget 命令,hmget user:10001 name age,一次就能把姓名和年龄都取回来,而不是先取姓名,再取年龄。(来源:Redis命令参考手册中hmset/hmget命令的示例)
第三,不是所有查询都适合用Hash的HGETALL。
hgetall 这个命令很有诱惑力,一下就把整个Map的所有字段和值都返回给你,感觉很省事,但这是个非常危险的操作!如果你的Hash很大,比如存储了一篇文章的详细内容,有几百个字段,hgetall 会一次性把几百个字段的数据全部通过网络从Redis服务器传输到客户端,这会大量消耗网络带宽和服务器CPU,如果频繁执行,可能会拖慢整个Redis服务,甚至影响其他业务。
那该怎么办呢?

- 按需索取:大部分时候你并不需要所有字段,坚持使用
hget或hmget来获取你真正需要的字段。 - 如果确实需要全部,考虑拆分:如果你确实有场景需要频繁读取整个对象,就要反思这个对象的设计是不是太大了,是不是可以把它拆分成几个逻辑上的小Hash?或者,这个数据的使用模式是否更适合直接存成一个JSON字符串(前提是它不会被频繁地部分更新)?这是一个权衡。
- 使用HSCAN进行迭代:如果这个巨大的Hash必须存在,而你偶尔需要遍历所有数据(比如数据统计),绝对不要用
hgetall,而要用hscan命令。hscan可以渐进式地、分批次地遍历整个Hash,不会长时间阻塞Redis服务器,对性能影响小得多。(来源:Redis官方关于扫描命令HSCAN的说明,旨在解决KEYS和HGETALL等命令的阻塞问题)
第四,别忘了给Hash的键设置过期时间。
Redis的一个核心优势是可以给任何键(key)设置生存时间(TTL),Hash也是一个键,所以一定要记得用 expire 命令给它设置过期时间,比如缓存用户信息的Hash,可以设置一小时过期,这样能避免无用数据长期占用宝贵的内存空间,很多人只记得给简单的键值对设置过期,却忘了给Hash、List这些复杂结构设置,导致内存被慢慢吃光。(来源:Redis内存管理和过期键机制)
第五,小技巧:控制单个Hash的大小。
虽然理论上一个Hash能存储非常多的字段,但在实际应用中,最好控制一下单个Hash的大小,当Hash内部的字段数量爆炸式增长时(比如成千上万个),其内部数据结构的维护成本可能会增加,虽然这个影响对用户来说通常不明显,但在极端高性能场景下需要考虑,如果一个Hash变得太大,可以考虑按某种规则进行水平拆分,按日期拆分:把一天的用户登录记录存成一个Hash login:20231027,而不是把所有日期的记录都塞进一个巨大的 user:login Hash里。
高效使用Redis Map的秘诀就是:
- 心思细:用Hash结构来精细化操作字段,避免大JSON的整体读写。
- 出手狠:多用批量命令(hmset/hmget),减少网络通信次数。
- 眼光准:慎用
hgetall,多用hmget按需获取,大数据量遍历用hscan。 - 有远见:记得给每个Hash键设置合理的过期时间。
- 懂分寸:避免让单个Hash变得过于庞大。
把这些要点记在心里,你在使用Redis的Map时就能真正发挥出它的高性能优势,而不是不知不觉地制造性能陷阱。”
本文由盘雅霜于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/73461.html