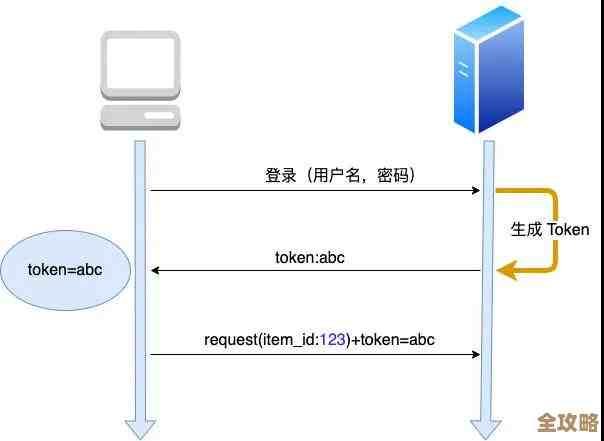
Redis那些设计上的问题越来越明显,很多场景下开始暴露出不少缺陷和不足

主要来源于知乎、掘金、CSDN等技术社区上多位开发者和架构师的讨论与文章,以下是对这些普遍观点的直接汇总:**
很多人提到Redis最核心的问题是其“全内存”特性,虽然内存越来越便宜,但当数据量真正大到一定程度,比如几百GB甚至TB级别时,全内存的成本会变得非常高昂,这不仅仅是硬件成本,还包括运维成本,相比之下,一些新型的键值存储数据库或时序数据库提供了“内存+磁盘”的混合存储模式,热数据放内存,冷数据自动降级到磁盘,在保证大部分性能的同时,极大地降低了成本,Redis虽然通过持久化(RDB/AOF)机制将数据写入磁盘,但它在运行时所有数据必须驻留在内存中,这个设计在应对海量数据场景时显得不够经济。

Redis在持久化机制上存在权衡和风险,它提供了两种主要的持久化方式:RDB快照和AOF日志,但无论选择哪一种,都有明显的缺点,如果选择RDB,它是在某个时间点创建整个数据库的快照,如果服务器在两次快照之间宕机,那么最后一次快照之后的所有数据都会丢失,数据可靠性不高,如果选择AOF,它会记录每一个写操作,数据安全性更高,但AOF文件会持续增长,重写过程(rewrite)即使是在后台进行,也可能对性能造成压力,尤其是在磁盘IO性能不佳的机器上,重写期间可能会引起服务短暂停顿,虽然可以配置为“每秒同步”或“每个操作同步”,但这又会在性能和数据安全之间进行艰难取舍,很多人觉得这个设计不够优雅,总需要小心翼翼地配置和监控。
第三个经常被诟病的问题是单线程模型的局限性,Redis在处理网络请求和执行命令时是单线程的,这避免了锁的竞争,使得Redis非常高效,但这个模型的另一面是,它害怕“慢查询”,任何一个耗时的操作,比如对一个包含百万元素的Set求交集(SINTER),或者误用了KEYS *命令,都会阻塞整个实例,导致所有其他请求的延迟飙升,甚至服务不可用,虽然新版本引入了多线程来处理一些IO任务,但核心的命令执行依然是单线程,在高并发且命令复杂度不可控的场景下(比如作为缓存时,可能被复杂查询穿透),这个设计就成了一个不稳定因素。

第四点是功能单一性带来的架构复杂性,Redis是一个非常纯粹的“数据结构服务器”,它擅长做缓存、简单的消息队列、排行榜等,但一旦业务逻辑变得复杂,需要用到更高级的查询(比如多条件组合查询、模糊查询)、事务支持或者更复杂的分析功能时,Redis就力不从心了,开发者往往需要结合其他组件(如Elasticsearch用于搜索,关系型数据库用于复杂查询和事务)来构建系统,这导致了系统架构变得复杂,需要维护多个组件,并处理数据一致性问题,很多人觉得,如果有一个数据库能同时提供Redis的性能和类似关系型数据库的查询灵活性就好了,所以像TiKV这样的新型数据库开始吸引眼球。
第五,在集群和分布式方面,Redis Cluster虽然提供了分片和自动故障转移的能力,但它的设计也被认为有一些“反直觉”和不够完善的地方,它采用了一种叫做“哈希槽”的分片方式,但客户端需要感知集群拓扑,或者通过支持集群的客户端库来访问,这增加了客户端的复杂度,Redis Cluster的扩容和缩容过程相对繁琐,尤其是在进行数据迁移时,对性能有一定影响,并且需要谨慎操作,相比一些原生分布式设计、对应用透明的数据库(如Cassandra),Redis Cluster的运维复杂度更高。
很多人提到内存管理的问题,当内存用尽时,Redis会根据配置的淘汰策略(如LRU、LFU)来删除数据,但这是一种被动的、影响业务的行为,一旦触发内存淘汰,就意味着有些数据被强制清除了,可能会引起缓存穿透等问题,Redis的内存碎片化问题也比较突出,虽然有一定机制可以整理碎片,但通常需要手动执行MEMORY PURGE命令或重启实例,这在生产环境中是有风险的,持续运行的服务,其内存碎片率可能会逐渐升高,导致实际可用的内存小于物理内存。
本文由帖慧艳于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/71837.html