Redis到底能不能真当数据库用?它的革命性到底在哪儿,值得深聊一下

关于Redis能不能真当数据库用,这事儿得掰开揉碎了说,简单粗暴的答案是:能,但有前提,而且你得非常清楚你用它来存什么、怎么存。 把它当成像MySQL、PostgreSQL那样的传统关系型数据库的完全替代品,那多半会掉坑里;但如果你用它来承载特定类型的数据和业务场景,它不仅能当数据库,甚至能带来革命性的性能体验。
要理解这一点,得先看看Redis的“革命性”到底在哪儿,这得从它的设计初衷说起,Redis的作者Salvatore Sanfilippo(别名antirez)当初就是为了解决一个非常具体的问题:如何应对大量数据的实时读写,同时保证极低的延迟。 传统磁盘数据库(像MySQL)在数据量大、并发高的时候,I/O(输入/输出)瓶颈就成了致命伤,因为磁盘读写速度跟内存根本不在一个数量级,Redis的革命性突破就在于,它彻底抛弃了磁盘,将数据完全放在内存中操作。
根据antirez在早期博客和访谈中的思路,他的核心思想是:与其不断地优化磁盘I/O,不如绕过它。 内存的价格在下降,而访问速度是磁盘的成千上万倍,把所有数据放在内存里,所有的读写操作都在内存中完成,这样就能轻松应对每秒数万甚至数十万的请求,延迟可以低到亚毫秒级别,这种速度的提升是数量级的飞跃,对于需要实时响应的场景(比如微博的点赞数、评论数,电商的秒杀库存,游戏玩家实时状态)是颠覆性的,这就是Redis最核心的革命性所在:它把数据库的性能基准从“秒级、毫秒级”提升到了“微秒级”。

但凡事都有两面性,把数据全放内存带来了无与伦比的速度,也带来了最明显的软肋:数据持久化和成本。
-
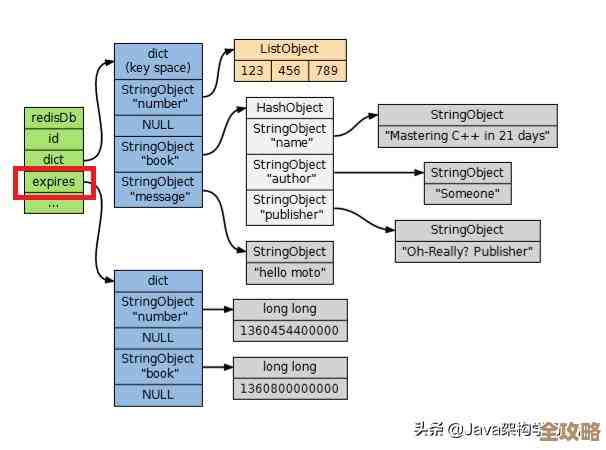
数据持久化问题:内存是易失性的,一断电数据就没了,Redis当然考虑了这点,它提供了两种主要的持久化机制:RDB(快照)和AOF(日志),但这里就有取舍了,RDB是定期全量备份,如果服务器在两次备份之间宕机,会丢失一段时间的数据,AOF是记录 every write operation,数据安全性高,但文件会越来越大,恢复速度慢,即使你同时开启两者,也无法做到像传统数据库那样在保证高性能的同时实现绝对的、实时的数据不丢失(即ACID中的Durability),如果你用Redis存的是核心的、绝对不能丢的财务交易数据,那风险极高。

-
成本问题:内存比硬盘贵得多,这意味着用Redis存储海量数据(比如几个TB的用户日志)的成本会非常高昂,而用硬盘存储则经济实惠得多。
回到最初的问题:Redis到底怎么当数据库用?

答案是:把它用作“主数据库”时,必须严格筛选数据类型和业务场景。
最适合用Redis当主数据库的数据,通常长这样:
- 数据结构简单但访问极频繁:比如用户的会话(Session)、购物车、排行榜、计数器(文章阅读量、点赞数),这些数据模型正好对应Redis的String(字符串)、Hash(哈希)、Sorted Set(有序集合)等丰富的数据结构,操作起来非常高效。
- 允许少量数据丢失:比如一个用户的会话丢失了,最坏的结果就是让他重新登录一下;一个视频的点赞数在宕机时丢了100个,虽然不爽,但并非灾难,这种对数据丢失有一定容忍度的场景,Redis的持久化机制是足够应付的。
- 需要极致的读写速度和低延迟:这是Redis的看家本领。
在实践中,更常见、也更稳妥的用法是 “混合架构”:用Redis作为缓存(Cache) 或加速层,放在传统数据库(如MySQL)前面,热点的、频繁访问的数据从Redis中读取和计算,减轻后端数据库的压力;而所有数据的最终“真相来源”仍然落在安全可靠的关系型数据库中,这种架构结合了内存的速度和磁盘的持久性,是互联网应用最经典的搭配。
Redis的革命性在于它用“全内存”的设计哲学,重新定义了数据库的性能上限,为实时应用提供了可能,它绝对可以当作数据库来使用,但它是一种特化的、为速度和简单数据结构而生的数据库,而非通用的“万金油”,用它之前,务必想清楚:你的数据是否值得用内存的成本来换取微秒级的速度?你的业务是否能承受潜在的数据丢失风险?想明白了这些,你就能判断Redis在你的架构里,到底是当之无愧的主将,还是冲锋陷阵的前锋了。
(主要思想来源参考了Redis创始人antirez的博客文章、访谈以及《Redis设计与实现》一书中的核心观点。)
本文由水靖荷于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/71662.html