怎么用Redis快速查所有字段,顺便看看具体步骤和方法

需要明确一点,根据Redis的官方文档和普遍的设计理念,Redis本身并不直接提供一个单一的、万能的命令来让用户像在关系型数据库里执行SELECT * FROM table那样,一次性获取某个键值对中“所有字段”的详细信息,这里的“所有字段”通常指的是哈希(Hash)数据类型中的字段和值,核心方法是使用HGETALL命令,下面将围绕这个核心,详细说明步骤、相关方法以及重要的注意事项。
核心方法:使用 HGETALL 命令
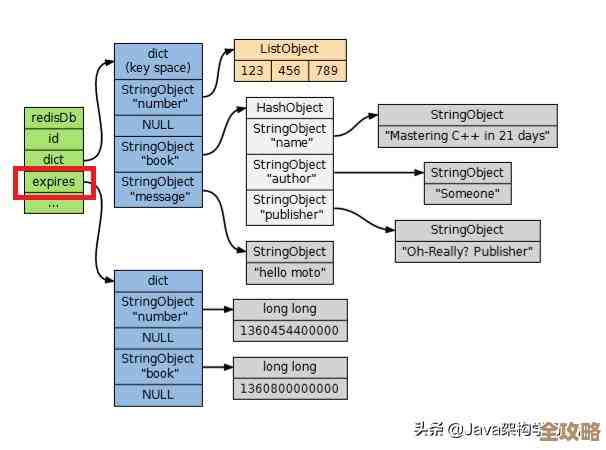
当你在Redis中存储一个对象时,比如一个用户信息,很自然地会使用哈希(Hash)类型,它可以将多个字段-值对存储在一个键(Key)下,一个键为user:1001的哈希,可能包含name、age、email等字段。
-
命令作用:
HGETALL key命令用于获取指定键(key)对应的哈希中所有的字段(field)和值(value),它会以一个列表(List)的形式返回结果,这个列表的顺序是字段1, 值1, 字段2, 值2, ...。 -
具体操作步骤:
-
第一步:存储数据,你需要确保数据是以哈希类型存储的,使用
HSET命令来设置。HSET user:1001 name "张三" age 30 email "zhangsan@example.com" city "北京"这条命令在键
user:1001下,一次性设置了4个字段。 -
第二步:查询所有字段,使用
HGETALL命令来获取这个键下的所有内容。HGETALL user:1001 -
第三步:解析结果,Redis会返回如下内容:
1) "name" 2) "张三" 3) "age" 4) "30" 5) "email" 6) "zhangsan@example.com" 7) "city" 8) "北京"你的客户端程序(如Python的redis-py库)通常会帮你把这个列表转换成更易用的字典(Dictionary)或对象。
-
为什么说这是“快速”的?
根据Redis官方文档对其数据结构的解释,哈希表在Redis内部是通过哈希表实现的,这使得大多数操作,包括HGETALL,的时间复杂度都是O(1),即常数时间复杂度,这意味着,无论这个哈希里存储了10个字段还是100个字段(在合理范围内),HGETALL命令获取所有数据的速度都非常快,因为它只需要一次网络往返和一次内部查找,这比你先用HKEYS命令获取所有字段名,再对每个字段名执行一次HGET命令要高效得多(后者是O(n)次网络往返,效率极低)。
其他相关方法和适用场景
虽然HGETALL是主力,但在某些特定需求下,其他命令也很有用:
-
只想看字段名,不看值:使用
HKEYS- 命令:
HKEYS key - 作用:只返回哈希中所有的字段名(field names),不返回值。
- 示例:
HKEYS user:1001返回1) "name" 2) "age" 3) "email" 4) "city"。 - 场景:当你只需要检查一个哈希对象包含哪些属性时。
- 命令:
-
只想看所有值,不关心字段名:使用
HVALS- 命令:
HVALS key - 作用:只返回哈希中所有的值(values),不返回字段名。
- 示例:
HVALS user:1001返回1) "张三" 2) "30" 3) "zhangsan@example.com" 4) "北京"。 - 场景:相对少见,但如果你确信值的顺序固定且有意义,或者只需要对值进行批量处理时可以使用。
- 命令:
-
查询字段数量:使用
HLEN- 命令:
HLEN key - 作用:返回哈希中字段的数量。
- 示例:
HLEN user:1001返回(integer) 4。 - 场景:快速判断一个哈希对象是否为空,或者统计大小。
- 命令:
非常重要的警告和最佳实践
直接使用HGETALL虽然快,但有一个必须警惕的陷阱,这也是Redis官方文档和许多性能优化指南中反复强调的:
- 警惕大Key问题:
HGETALL命令会一次性将整个哈希的内容拉取到客户端,如果一个哈希存储了成千上万个字段(一个用户的所有行为日志),那么这个命令返回的数据量会非常大,这会导致:- 网络阻塞:巨大的响应体会占用大量网络带宽,可能会影响Redis服务器处理其他请求。
- 客户端内存压力:客户端需要分配大量内存来存放这些数据,可能导致客户端程序变慢甚至崩溃。
- 响应延迟:序列化和传输大量数据需要时间,会导致该命令的响应时间变长。
如何安全地处理大型哈希?
如果你的哈希可能很大,不应该直接使用HGETALL,而应采用以下方法:
-
使用
HSCAN命令:这是官方推荐的用于增量迭代大型集合(包括哈希、集合、有序集合)的命令,它可以分批次的获取数据,避免一次性耗尽资源。- 命令:
HSCAN key cursor [MATCH pattern] [COUNT count] - 作用:基于游标(cursor)的迭代器,每次调用返回一部分字段和值,以及一个新的游标,下次调用时传入这个新游标即可获取下一批数据,直到游标变为0,表示迭代完成。
- 示例(在Redis-cli中):
0.0.1:6379> HSCAN user:large_hash 0 COUNT 100这个命令会从游标0开始,尝试返回最多100个字段-值对。
- 优点:内存和网络压力是可控的,不会对服务器造成剧烈冲击。
- 命令:
-
重新设计数据模型:考虑是否真的需要将一个包含极多字段的对象放在一个哈希里,有时,将其拆分成多个小的哈希,或者使用其他数据结构(如Sorted Set或List)结合关键查询,可能是更优的选择。
要快速查询Redis哈希类型中的所有字段,最直接有效的方法是使用HGETALL命令,它的步骤简单:先用HSET存储,再用HGETALL获取,其速度快的原因是Redis内部高效的哈希表实现,但同时,必须时刻注意“大Key”风险,对于字段数量可能非常多的哈希,务必使用HSCAN命令进行分批迭代查询,这是保证Redis高性能和稳定性的关键实践,对于只需字段名或值的场景,可以选用HKEYS或HVALS命令。

本文由盈壮于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/71659.html