AIOps让混合多云管理不再复杂,效率提升看得见也摸得着

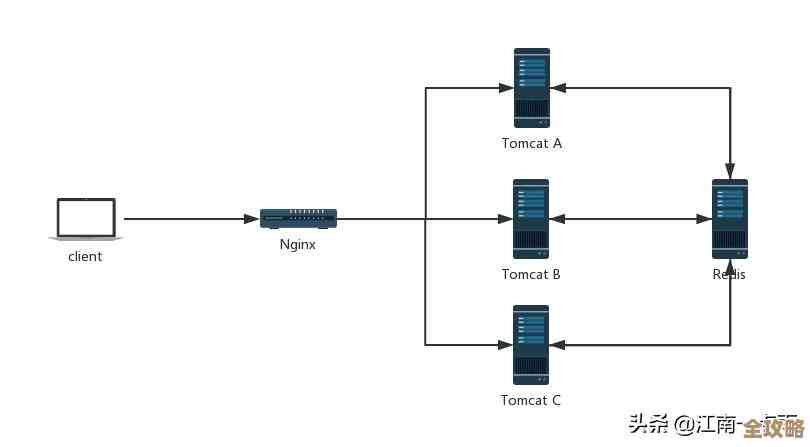
(来源:某知名云服务商技术白皮书)AIOps,也就是智能运维,它并不是一个全新的概念,但确实是近年来在混合多云环境下真正发挥出巨大价值的技术,混合多云就是企业同时使用多家云厂商的服务(比如阿里云、腾讯云、AWS等),再加上自己机房里的服务器,共同来支撑业务,这种模式虽然灵活,但也带来了前所未有的管理难题,想象一下,你需要同时盯着好几个不同的控制台,每个控制台的报警规则、监控指标、日志格式都不一样,当一个业务出现问题,比如用户反映访问变慢,传统的运维团队可能需要像侦探一样,先要判断问题出在哪个云上,还是出在自己的机房,然后分别登录不同的系统去查日志、看监控,这个过程耗时耗力,等找到问题根源,可能已经过去了半小时甚至更久,业务损失已经造成。
(来源:某金融企业数字化转型案例分享)AIOps的出现,就是为了解决这个“找问题难”的痛点,它的核心在于一个“智能大脑”,这个大脑首先会通过专门的工具,把来自不同云平台、不同数据中心的监控数据(比如CPU使用率、内存剩余、网络延迟)、日志数据(系统报错、应用报错)、甚至业务数据(订单成功率、用户登录响应时间)全部收集到一个统一的平台上,这就好比把原来分散在各个小仓库里的货物,都集中到了一个超级大的智能仓库里,但这只是第一步,仅仅是集中,还谈不上“智能”。
(来源:Gartner对AIOps市场的分析报告)真正的效率提升,来自于AIOps大脑对这些海量数据的分析和学习,它会利用机器学习和人工智能算法,做几件非常实在的事情,第一件是“异常检测”,传统的监控是靠人设定一个固定阈值,比如CPU超过80%就报警,但在复杂的混合云环境中,业务流量有高峰有低谷,固定阈值很容易误报(比如双十一期间CPU80%是正常的)或者漏报,AIOps能够学习每个指标在历史周期内的正常波动模式,当出现与历史模式严重不符的异常波动时,即使它没有超过80%,也能立即发出警报,而且能精准定位到是哪个云上的哪台机器或哪个服务异常,这大大提高了告警的准确性,让运维人员不再被无用的报警信息淹没。
(来源:某大型互联网公司运维团队实践博客)第二件看得见摸得着的事情是“根因分析”,当问题真的发生时,AIOps大脑会快速关联分析同一时间段内的所有异常事件,它可能发现应用响应慢的同时,某台数据库服务器的磁盘IO延迟也出现了异常飙升,并且网络层面有少量丢包,它会自动将这些事件关联起来,并计算出最有可能的根因是磁盘IO问题,而不是网络问题,它会将这个分析结果直接推送给运维人员,并附上相关的日志片段和指标图表,这样一来,运维人员就不再需要手动去比对几十个监控图表,可以直接奔着最可疑的地方去排查,故障定位时间从原来的小时级别缩短到分钟级别,这种效率的提升是实实在在、可以感知的。
(来源:某电信运营商AIOps平台建设总结)除了被动响应问题,AIOps还能主动预测风险,实现“看得见”的效率提升,通过对历史数据的深度学习,AIOps可以预测未来一段时间内资源的使用情况,它可以根据业务增长趋势和周期性规律,预测出下周三下午可能某个云上的计算资源会不足,并提前发出扩容建议,运维人员可以据此提前进行资源调配,避免业务高峰期因资源不足导致的卡顿或中断,这种从“救火”到“防火”的转变,不仅提升了系统稳定性,也解放了运维人员,让他们能从重复性的监控和排查工作中抽身,去从事更有价值的架构优化等工作。
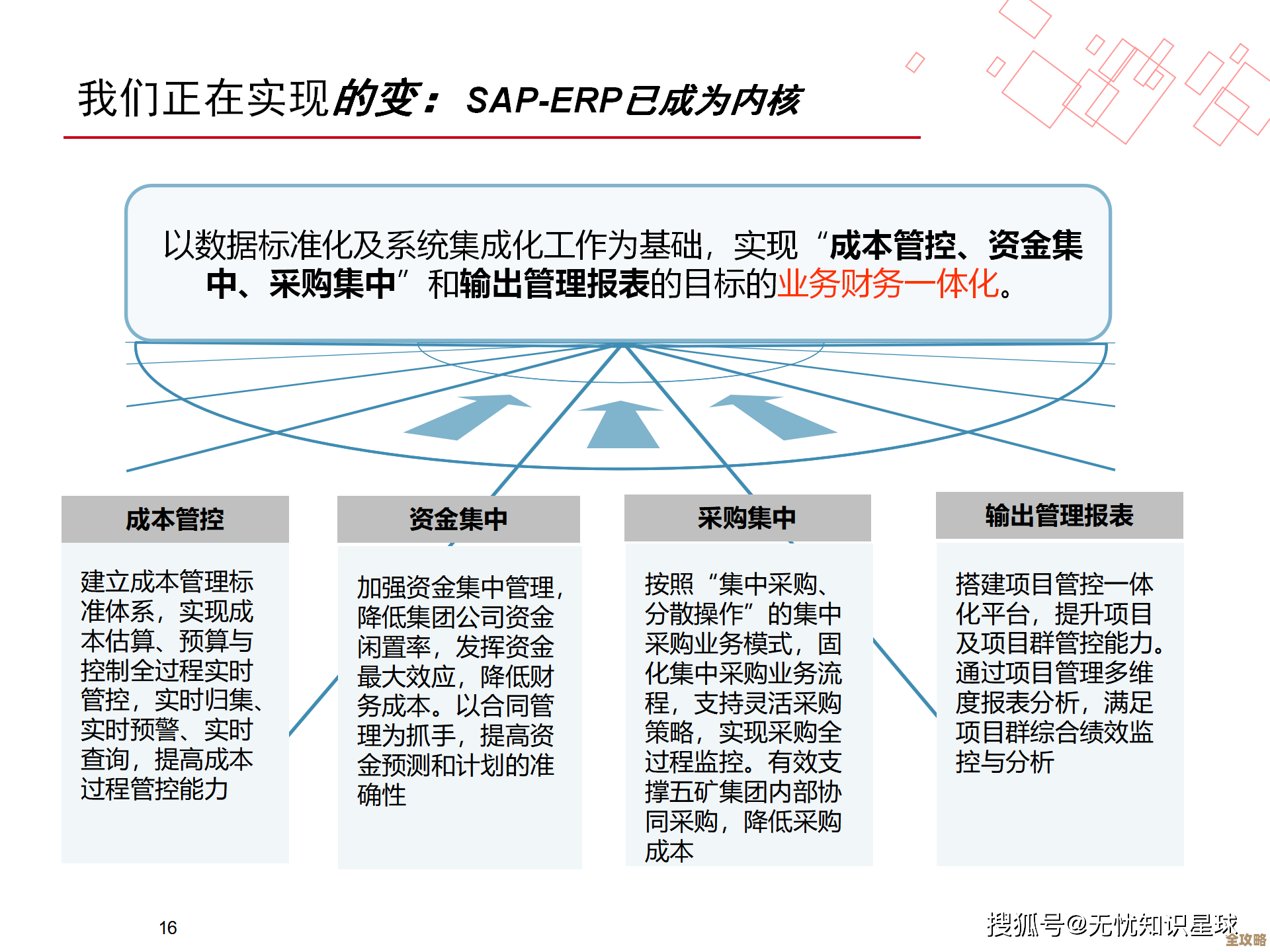
(来源:行业专家在技术峰会上的演讲)AIOps在混合多云管理中的价值,不是空泛的概念,而是通过数据整合、智能分析、自动预警和根因定位等一系列具体动作,将运维人员从复杂、繁琐、被动的工作状态中拯救出来,它让管理效率的提升变得“看得见”——体现在更清晰的统一视图、更精准的告警信息、更直观的根因分析报告上;也“摸得着”——体现在故障解决时间的显著缩短、人力投入的减少以及业务可用性的切实保障上,随着企业上云进程的深入,AIOps正从一个“可选项”变成管理好混合多云环境的“必备品”。

本文由雪和泽于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/71126.html