Redis进程之间到底怎么共享数据,实践中那些坑和经验聊聊

关于Redis进程之间怎么共享数据,首先要明确一点:Redis本身是一个单进程、单线程的模型,我们通常说的“Redis进程”,指的是一个个独立的Redis服务器实例,这个问题实际上是在问:多个独立的Redis实例之间,或者应用程序的多个进程如何通过Redis来共享数据。
核心方式就是把Redis本身作为一个集中的、共享的数据存储中心,所有需要共享数据的进程(无论是同一台机器上的多个应用进程,还是不同机器上的分布式应用)都连接到同一个(或同一组)Redis服务器,通过对Redis进行读写操作来实现数据共享,这听起来很简单,但实践中的“坑”和经验都围绕着如何安全、高效、正确地实现这个“读写”而来。
最基本的共享方式与第一个大坑:脏读脏写
最直接的方式就是进程A把数据写入Redis的一个键(Key),进程B再去读取这个键,进程A计算出了一个结果,执行 SET result_key "final_value",进程B通过 GET result_key 来获取。
- 坑点:竞态条件(Race Condition) 这看起来没问题,但如果进程A的写入操作不是一步完成的,而是需要多个步骤呢?它需要先读取一个旧值,经过计算,再写入一个新值,如果在这个过程中,有另一个进程也来读写同一个数据,就很容易出现数据错乱,这就是经典的“竞态条件”问题。
- 经验:使用原子操作
Redis的绝大多数单条命令都是原子性的,这是它的一大优势,要避免脏写,必须优先使用Redis提供的原子命令来组合你的逻辑。
- 用
INCR/DECR做计数器,而不是自己GETSET。 - 用
LPUSH/RPOP做队列,保证操作的完整性。 - 用
HSET/HGET操作哈希对象的不同字段,有时可以避免对整个大对象进行序列化读写。 - 对于更复杂的逻辑,Lua脚本是终极武器,因为Redis会保证一个Lua脚本在执行时是排他的,脚本中的所有命令会作为一个整体原子性地执行,中间不会被其他命令插入,这是解决复杂竞态问题的关键工具。(来源:Redis官方文档关于Lua脚本原子性的说明)
- 用
共享复杂数据结构与第二个大坑:序列化冲突

我们共享的数据往往不是简单的字符串,可能是列表、对象等,进程A可能用PHP把一个数组序列化成JSON字符串存入Redis,进程B用Java程序读取后,需要反序列化成Java对象。
- 坑点:序列化格式不一致或结构变更 如果PHP和Java对同一个数据结构的序列化/反序列化规则不一致,或者后来某个进程更新了数据结构(比如给对象增加了一个新字段),但另一个进程没有同步升级,就会导致反序列化失败或数据解读错误。
- 经验:制定并遵守统一的序列化协议
- 约定格式:团队内部必须明确规定使用哪种序列化格式,如JSON、MessagePack、Protocol Buffers等,JSON最通用,但MessagePack等更高效。
- 版本兼容:在设计数据结构时,要考虑向前向后兼容,使用Protobuf这种天生支持版本化的格式,或者在使用JSON时,采用“宽容”的解析策略(忽略未知字段)。
- 使用Redis原生数据结构:很多时候,与其把一个对象序列化成字符串存入,不如直接利用Redis的Hash来存储,比如存储用户信息,用
HMSET user:123 name "张三" age 30比存一个JSON字符串更好,因为你可以原子性地更新单个字段,并且节省网络带宽。
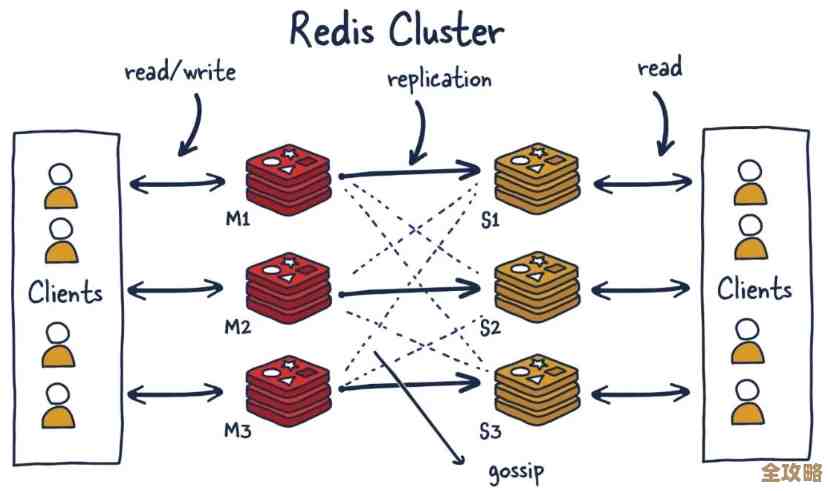
多实例扩展与第三个大坑:数据一致性
当数据量很大或者并发很高时,单个Redis实例会成为瓶颈,我们需要搭建Redis集群(Cluster)或者主从复制(Replication)架构。

- 坑点:主从延迟与脑裂
- 主从延迟:在读写分离架构中,写操作发生在主库,然后异步同步到从库,这意味着进程A写入主库后,进程B立刻去从库读取,可能会读到旧数据,这对于数据一致性要求高的场景是致命的。
- 脑裂:在网络分区发生时,可能会出现原主库和部分从库在一个分区,而客户端和另一个从库在另一个分区,如果客户端连接到了被提升为新主库的从库,并向其写入数据,而网络恢复后,旧主库也会尝试同步数据,导致数据冲突和丢失。
- 经验:根据业务场景选择一致性级别
- 强一致性要求:对于必须读到最新数据的场景,直接读写主库,放弃读从库带来的性能优势,或者使用Redis提供的
WAIT命令,让写操作等待一定数量的从库同步完成后再返回,但这会牺牲性能。 - 最终一致性可接受:对于大多数缓存场景或允许短暂不一致的业务(如文章阅读数),可以容忍主从延迟,享受读写分离的吞吐量提升。
- 理解集群特性:Redis Cluster将数据分片,一个键只存在于某个特定的主节点及其从节点上,客户端需要支持集群协议,能够正确地路由请求,要避免使用那些需要跨节点操作的命令,比如在不属于同一个slot的多个key上执行MGET。(来源:Redis集群规范中对Key分布和跨slot操作的限制)
- 强一致性要求:对于必须读到最新数据的场景,直接读写主库,放弃读从库带来的性能优势,或者使用Redis提供的
分布式锁与第四个大坑:锁的安全性
共享数据时,经常需要互斥访问,这就需要分布式锁,Redis实现分布式锁最经典的方式就是用 SET key random_value NX PX 30000(NX表示不存在才设置,PX设置超时时间)。
- 坑点:误删他人锁与过期时间评估
- 误删锁:进程A获取锁后,如果执行时间过长,超过了锁的过期时间,锁会自动释放,此时进程B获得了锁,接着进程A执行完了,它依然会去释放锁,这就把进程B的锁给释放了,解决办法是,锁的值要是一个随机生成的唯一标识(如UUID),释放锁时要用Lua脚本检查当前锁的值是否还是自己设置的那个,是才能删除。
- 过期时间评估:设置锁的过期时间是个难题,设短了,任务没完成锁就丢了;设长了,万一进程挂掉,其他进程要等待很久,一个常见的经验是,设置一个相对合理的过期时间,然后另起一个“看门狗”线程,在任务执行期间定期去延长锁的过期时间。(来源:Martin Kleppmann的论文《How to do distributed locking》及Redis官方关于Distributed Lock的改进方案)
总结一下核心经验:
- 原子性是基石:坚信单命令原子性,善用Lua脚本处理复杂原子操作。
- 序列化要规范:统一数据格式,并考虑演进和兼容。
- 认知延迟与分区:理解主从、集群架构下的数据一致性妥协,根据业务选择方案。
- 分布式锁非万能:实现一个正确、安全的分布式锁需要很多细节,理解其局限性,在某些极端场景下可能需要更强大的协调系统(如ZooKeeper)。
- 监控是生命线:必须监控Redis的内存使用、慢查询、网络流量、主从同步状态等,很多“坑”在爆发前都是有征兆的。
归根结底,Redis进程间共享数据的核心思想是“共享状态中心化”,而所有的实践经验都是为了让这个中心化的状态在面对并发、故障和扩展时,依然能保持我们期望的正确性和可靠性。
本文由酒紫萱于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/71172.html