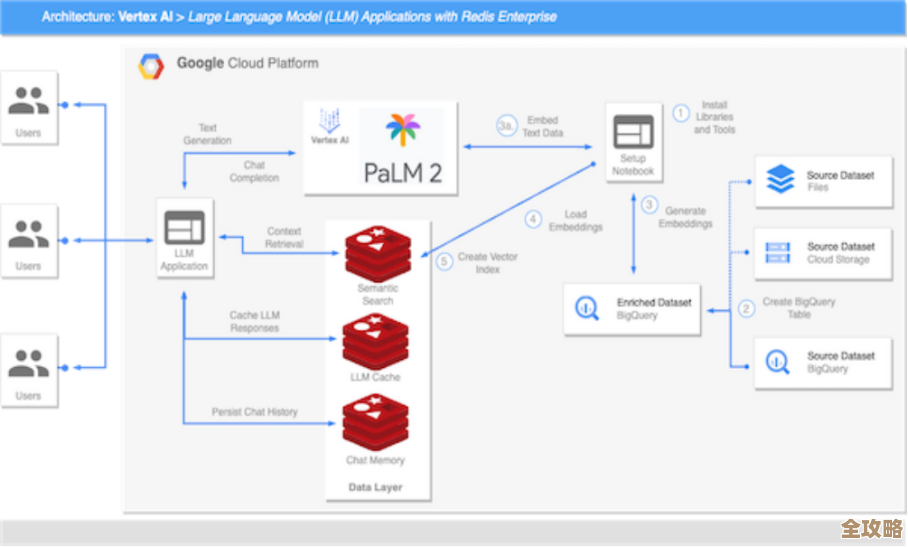
Redis怎么快速拿到目录里所有文件,简单又实用的小技巧分享

网络技术社区和开发者经验分享)
今天咱们来聊一个很实际的问题:怎么在Redis里快速拿到一个“目录”下所有的文件?首先得说明白,Redis本身没有“目录”和“文件”这个概念,它用的是“键值对”,但是呢,我们可以通过一些巧妙的设计,模拟出类似文件目录的结构,这样管理起数据来就方便多了,感觉就像在操作文件夹一样。
为啥需要这个操作?
想象一下,你用Redis存了很多用户的数据,每个用户都有一个独立的空间,存放了他的个人资料、他发的帖子、他的购物车商品,这些数据可能分散在好多不同的键(Key)里面,如果这个用户注销账号了,你想一口气把他所有的数据都清理掉,该怎么办?一个一个键去查、去删?那太慢了,尤其是数据量大的时候,简直是大海捞针,我们需要一个办法,能快速找到所有属于这个用户的键。
核心思路:用Key的命名来模拟目录
Redis虽然没有目录,但Key的名字我们可以随便起啊!这就是最关键的小技巧,我们可以像给文件规定路径一样,给Key起一个带有“路径”结构的名字。
举个最简单的例子,我们要存用户123的资料、帖子和购物车:
- 传统散装存法:
user_profile:123,user_posts:123,user_cart:123,这几个键之间没啥直接联系。 - 模拟目录存法:
user:123:profile,user:123:posts,user:123:cart。
看出来区别了吗?第二种方法,我们用冒号 作为分隔符,把Key组织成了 user:123:profile 这样的形式,这就像是一个文件路径 /user/123/profile.txt,这样一来,所有以 user:123: 开头的Key,天然就都属于用户123了,这个 user:123: 就相当于一个“目录”。
实战技巧:使用 KEYS 命令(简单但需谨慎)
找到了“目录”,怎么把里面的“文件”都列出来呢?最直接想到的命令就是 KEYS。
你想找出用户123的所有数据,直接在Redis命令行里输入:
KEYS user:123:*这个命令里的星号 是一个通配符,表示匹配任何字符,这个命令返回的就是所有以 user:123: 开头的键,嗖的一下,user:123:profile、user:123:posts、user:123:cart 就全都出来了,简单吧?这确实是最快、最直观的方法。
这里有个非常重要的“!
KEYS 命令虽然用起来爽,但在生产环境(就是正式上线的服务器)里一定要非常非常小心,最好不用,为啥呢?因为这个命令是阻塞式的,它会遍历整个数据库的所有键,如果你的Redis里存了几百万、几千万个键,执行一次 KEYS * 可能会导致Redis卡住那么一小会儿,在这期间其他所有请求都得等着,可能就会导致服务超时或者卡顿,大家普遍把 KEYS 命令看作是一个“扫地僧”级别的命令,威力大但容易误伤,只适合在测试环境或者确定没人的维护时段偶尔用一下。
更推荐的实用技巧:SCAN 命令
既然 KEYS 有风险,那有没有更安全的方法呢?有,那就是 SCAN 命令。
SCAN 命令的作用和 KEYS 差不多,也是用来查找匹配模式的键,但它有个绝佳的优点:非阻塞迭代式查找,它不会一次性把所有结果都给你,而是每次只返回一小部分,并给你一个“游标”(cursor),你拿着这个游标再次调用 SCAN,它就从上次停下的地方继续找,这样就把一个大任务拆成了很多个小任务,对服务器的影响就微乎其微了。
怎么用呢?举个例子,还是找 user:123: 开头的所有键:
-
第一次执行:
SCAN 0 MATCH user:123:* COUNT 1000是起始游标,表示从头开始。MATCH user:123:*是指定匹配的模式,和KEYS后面的一样。COUNT 100是建议每次返回的大概数量(不一定精确是100个)。- 执行后,Redis会返回两个东西:一个是下一个游标值(比如是
18),一个是本次扫描到的键的列表。
-
第二次执行:
SCAN 18 MATCH user:123:* COUNT 100- 把上一次返回的游标
18放在命令里。 - 它又会返回一个新的游标和一批新的键。
- 把上一次返回的游标
-
一直重复这个过程,直到返回的游标是
0为止,这就表示整个数据库都遍历完了,所有匹配的键也都拿到了。
你看,虽然 SCAN 用起来比 KEYS 多几步,稍微麻烦一点点,但它胜在安全、礼貌,不会霸占着服务器不让别人干活,这才是生产环境下应该采用的“好公民”做法。
总结一下这个小技巧
- 设计是关键:存数据的时候,就要有意识地用分隔符(比如冒号 )把Key命名成有层次的结构,这叫“命名空间”的设计,这相当于提前把文件分门别类放好了。
- 查询分场景:
- 本地开发或临时排查:图快的话,可以用
KEYS pattern命令,立马就能看到结果。 - 线上生产环境:老老实实用
SCAN命令迭代查找,虽然慢点,但稳定压倒一切。
- 本地开发或临时排查:图快的话,可以用
只要在存数据的时候多花一点心思,做好规划,以后查询和管理起来就能省下大量的时间和精力,这个利用Key命名模拟目录,再用 SCAN 命令安全遍历的小技巧,可以说是Redis日常使用中非常实用的一招了。

本文由称怜于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/83090.html