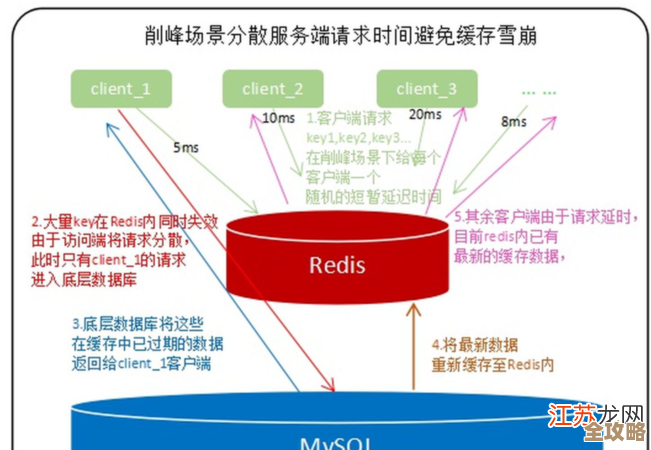
Redis本地性能怎么提升啊,优化技术那些事儿聊聊

首先得明白,我们说“本地性能”,通常指的是 Redis 服务就跑在你自己的物理机或者虚拟机上,不是云服务,这种情况下,性能的瓶颈和优化手段,很大程度上取决于你的硬件和配置,咱们就从一个请求进入 Redis 开始,一步步看哪里可能慢,以及怎么让它快起来。
第一步:网络连接和客户端(来源:Redis官方文档及社区最佳实践)
虽然 Redis 本身单线程处理命令快得飞起,但如果客户端连接和网络传输慢了,整体感觉还是很卡。
- 使用连接池:这是最最基础也是最重要的,不要每次执行命令都新建一个连接,那个开销非常大,用连接池复用连接,能极大减少建立和断开连接的开销,就像你去食堂打饭,每次都重新排队肯定慢,有个固定窗口(连接)一直开着就快多了。
- 使用更高效的序列化方式:如果你的客户端程序(比如用 Java、Python 写的)和 Redis 之间要传输复杂的对象,需要先序列化成 Redis 能存的数据格式,选择一个速度快、体积小的序列化工具(Protocol Buffers、MessagePack,或者语言内置的高效模块)能减少网络传输的数据量,从而提升速度。
- 管道技术(Pipeline):如果你有一大批命令要执行,比如要插入一万个键值对,别一个个发,用 Pipeline 把多个命令打包成一个请求发过去,Redis 一次性处理完再打包结果返回,这能极大地减少网络往返的次数,提升吞吐量,效果立竿见影,这就像搬砖,一块一块搬累死,用小车一次推一车就快多了。
第二步:Redis 自身的内存和数据结构(来源:Redis深度历险核心原理与应用实践)
Redis 的数据都放在内存里,所以怎么用内存是关键。
- 选用合适的数据结构:这是提升性能和节省内存的“王牌”,不要什么都用普通的 String 类型来存,存储一个用户的粉丝列表,用 Set 或 Sorted Set 比用 String 拼接高效得多,想存储一个对象的多个字段,用 Hash 结构比把整个对象序列化成 String 再存,通常更省内存,而且可以单独操作某个字段,Redis 官方有个经典的例子:同样存储一个用户信息,用 String 需要序列化整个对象,用 Hash 可以每个字段独立存储和访问,内存可能更省,灵活性也更高。
- 控制键的长度:键(Key)本身也是要占内存的,别把键名起得又臭又长,
user:information:profile:basic:123456,虽然可读性好,但浪费空间,在可读性和长度间做个平衡,u:info:123456就好很多,当你有上亿个键时,这省下的内存就非常可观了。 - 使用更紧凑的数据结构:Redis 在后期版本提供了一些优化后的数据结构,当 List、Hash、Set 的元素数量较少且元素体积较小时,会采用一种叫
ziplist(压缩列表)的紧凑编码方式来存储,能节省大量内存,你可以在配置文件里调整启用这些编码的阈值。hash-max-ziplist-entries 512意思是,当 Hash 的字段数不超过 512 个,且每个字段的值长度不超过hash-max-ziplist-value配置的字节数(64 字节)时,就用 ziplist 存储,合理设置这些参数,用一点点 CPU 换大量内存,非常划算。
第三步:持久化带来的磁盘 I/O 影响(来源:Redis设计与实现)
Redis 为了数据不丢,有 RDB 快照和 AOF 日志两种持久化方式,但它们都可能影响性能。
- RDB 快照:是某个时间点的数据全量备份,执行
bgsave命令或到达配置的保存条件时,Redis 会 fork 一个子进程来干这个活,fork 操作本身在数据量大时可能会卡顿一下,因为要复制父进程的页表,子进程持久化过程中,如果系统内存紧张,可能会引发大量的磁盘交换(Swap),导致性能骤降,优化方法是:确保机器有足够的内存,并给系统留出富余,别把内存刚好用完。 - AOF 日志:记录每一个写命令,更安全,但写盘频率高,你可以配置
appendfsync策略:always是每个命令都刷盘,最安全也最慢;everysec是每秒刷一次,是性能和安全性的折中,也是默认推荐;no让操作系统决定何时刷盘,性能最好,但可能丢失较多数据,对于大多数场景,everysec就够了,AOF 文件会越来越大,Redis 提供了bgrewriteaof来重写 AOF,消除中间命令,只保留最终数据的命令,这个重写过程也和 RDB 一样会 fork 子进程,所以同样要注意内存问题。
第四步:系统层面和硬件的“硬功夫”(来源:各类运维经验总结)
Redis 的性能天花板最终取决于硬件。
- 内存要大,速度要快:这是废话,但是真理,内存不足是一切问题的根源,在预算内选择频率更高的内存条也有帮助。
- CPU 不是核心但也很重要:Redis 是单线程模型,主流程只用一个 CPU 核心,所以高频 CPU 比多核 CPU 对 Redis 更有利,持久化、网络传输等操作会用别的核心。
- 磁盘速度:如果用了 AOF 或者 RDB,磁盘的 I/O 能力至关重要,一块高性能的 SSD 硬盘对持久化性能提升巨大,能显著减少因为持久化造成的延迟,避免使用传统的机械硬盘。
- 操作系统配置:有几个系统参数可以调优。禁用透明大页(Transparent Huge Pages),这个功能在某些 Linux 发行版上默认开启,但它在内存分配时的不确定性可能导致 Redis 在持久化 fork 子进程时出现严重的延迟问题,关闭它通常能带来更稳定的性能,另一个是
vm.overcommit_memory设置为 1,这可以避免在 fork 时因为内存申请失败而报错。
总结一下:
提升 Redis 本地性能是个系统工程,不是改一个参数就万事大吉,你得:
- 先监控:用
INFO命令或者监控工具看看慢查询、内存使用情况、持久化状态,找到真正的瓶颈。 - 从应用端入手:检查客户端是否用了连接池、Pipeline,数据结构用得是否合理,这步往往投入小,见效大。
- 优化 Redis 配置:根据数据特性和业务容忍度,调整内存淘汰策略、持久化策略、各种数据结构的编码阈值。
- 夯实基础:确保硬件(尤其是内存和磁盘)给力,并做好关键的系统参数调优。
没有放之四海而皆准的最优配置,最好的配置是适合你业务场景的那个,多测试、多观察,才是优化的不二法门。

本文由酒紫萱于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/81897.html