Redis集群流量复制怎么搞,实际操作和注意点聊聊

做个“复读机”

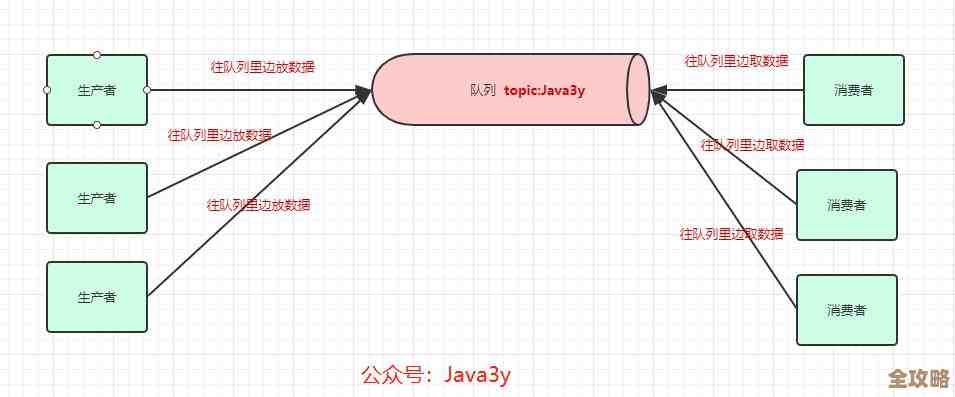
你自己想一下,实现这个目标最直接的办法是什么?就是在客户端和Redis集群之间,插一个“中间人”,这个中间人把客户端发给源集群的请求全部记下来,然后自己不当家不做主,原封不动地再转发给目标集群一份,客户端完全感觉不到这个中间人的存在,它还以为自己在直接和源集群玩呢。

现在市面上有几个现成的工具可以当这个“复读机”,最出名、用得最多的可能就是唯品会开源的 redis-migrate-tool 和阿里云内部的 RedisShake,下面我主要结合 RedisShake 的思路来聊,因为它设计得比较清晰。

实际操作的大概步骤
- 准备两个集群:你的源集群(正在服务的)和目标集群(新的、空的),确保目标集群的容量和配置至少不低于源集群,不然流量一打进去就挂掉了,复制也就没意义了。
- 部署并配置“复读机”工具:以
RedisShake为例,你需要下载它的二进制文件,然后重点就是写一个配置文件,这个配置文件里最关键的就是要写好两边集群的地址、密码(如果有)、以及指定模式为sync(同步,即实时复制)或rump(只复制存量数据),我们这里要流量复制,肯定是选同步模式。 - 先做全量同步:当你启动工具时,它会先做一次全量数据拷贝,把源集群里现有的所有数据先一股脑地搬到目标集群,这个过程中,工具会记录下当前复制到的数据位置(类似于一个快照点)。
- 自动切换为增量实时复制:全量数据搬完后,工具不会停,它会立刻开始监听源集群新的写命令,从刚才记录的那个快照点开始,把所有新进来的写入、修改、删除命令,实时地、一条一条地转发给目标集群,到这个阶段,就实现了真正的流量复制。
过程中必须要注意的几个坑
- 网络延迟和带宽是最大敌人:这个“中间人”部署在哪里非常关键,最理想的当然是和你的源集群、目标集群在同一个机房的内网环境,如果你把工具放在自己的办公电脑上,去复制云端集群的流量,那网络延迟会非常高,这个“复读机”很快就会成为瓶颈,不仅拖慢真实客户端的请求,还可能因为堆积太多命令没转发而导致内存爆掉或者数据严重滞后。(来源:RedisShake官方文档及实践常见问题)
- 目标集群的性能必须过关:你复制的可是生产流量,如果目标集群的机器配置比源集群差,或者网络带宽不够,它根本处理不过来这么多请求,结果就是目标集群的CPU飙高、内存不足、请求超时,你这不叫压测了,叫直接打垮,所以目标集群的规格最好能比源集群高一点,留点余量。
- 注意Key的过期时间(TTL):这是个非常隐蔽的坑,Redis的
EXPIRE命令是设置一个绝对的过期时间戳,如果你的源集群和目标集群的系统时间不一致,会导致同一个Key在两边过期的时间点不一样,数据就对不上了,虽然像RedisShake这样的工具会尝试处理这个问题,但最保险的做法是确保两台集群的机器时间同步。(来源:Redis数据迁移与同步的常见陷阱) - 监控,监控,还是监控:你不能把工具一开就撒手不管了,必须死死地盯着几个指标:
- 延迟:工具转发命令的延迟有多高?如果延迟持续增长,说明目标集群处理不过来或者网络有瓶颈。
- 数据差异:定期用一些工具(
redis-full-check,通常和RedisShake配套)对比一下两个集群的数据是否完全一致。 - 工具本身资源消耗:这个“复读机”本身的CPU和内存占用高不高?别流量没把集群压垮,先把中转工具压垮了。
- 对源集群的影响要心中有数:虽然工具的原理是只读式地监听,但对源集群还是会有非常轻微的影响,主要是网络带宽上多了一个消费者,对于绝大多数场景这点影响可以忽略,但如果你源集群的网络已经到极限了,那就要特别小心。
- 过滤掉不该复制的命令:你可能不希望复制所有流量,一些临时的、用于监控的Key,或者目标集群里已经有一些测试数据,你不想被覆盖,好的工具都支持配置过滤规则,只复制特定前缀或模式的Key,这个要根据你的实际业务需求来设定。
总结一下
搞Redis集群流量复制,技术上不算黑科技,核心就是找个可靠的“复读机”工具,真正的挑战不在于怎么配,而在于过程中的细节把控:网络要快、目标要强、监控要勤、时间要准,把它当成一次小型的实战演练,每一步都稳扎稳打,才能达到验证新集群或者平滑迁移的目的,千万别想当然地以为配置完启动就万事大吉,不然很可能复制没成功,还惹出一堆麻烦。
本文由芮以莲于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/81927.html