MySQL报错MY-012993,ER_IB_MSG_1168问题远程帮你快速修复解决

首先需要说明,错误代码MY-012993实际上是InnoDB存储引擎内部使用的一个错误编号,在MySQL数据库的实际错误信息中,用户更常见到的是与之关联的、更具描述性的错误代码 ER_IB_MSG_1168,这个错误信息通常表现为:InnoDB: A long semaphore wait,它就是数据库内部告诉你:“有一个线程被卡住很久了,导致其他线程都在等它,系统快要不响应了。”
这个错误的核心问题是“信号量等待”,可以把信号量想象成一把钥匙,用来保护一个共享资源,比如一张数据表或者一个索引块,当一个线程(比如一个执行查询的请求)需要修改这个资源时,它必须拿到这把“钥匙”,如果这把“钥匙”被另一个线程长时间占用不释放,那么后面所有需要访问这个资源的线程都只能排队等待,队列会越排越长,最终导致数据库连接池被占满,新的连接无法建立,应用程序就会出现卡顿、超时,甚至完全无法访问数据库的情况。
是什么原因导致了这把“钥匙”被长时间占用呢?根据MySQL官方文档(参考自MySQL官方手册关于InnoDB故障排除的章节)以及常见的运维经验,主要原因可以归结为以下几大类:
第一,存在性能极差的SQL查询。 这是最常见的原因,如果有一条SQL语句没有使用合适的索引,或者需要扫描和处理海量数据(即“全表扫描”),它就会长时间锁定某些资源,一个大表的复杂联表查询、使用了LIKE '%keyword%'这样的模糊查询、或者对没有索引的大字段进行排序(ORDER BY)和分组(GROUP BY),都可能导致执行时间过长,从而长时间持有信号量。
第二,高并发下的资源竞争。 当多个事务试图同时更新同一行数据时,InnoDB的行级锁机制会确保只有一个事务能进行修改,其他事务必须等待,在秒杀、抢购等高并发场景下,对少数热门商品记录的更新会引发剧烈的锁竞争,可能造成等待链,表现为信号量等待。
第三,磁盘I/O性能瓶颈。 如果数据库服务器使用的硬盘(特别是传统的机械硬盘HDD)读写速度很慢,或者当时正承受巨大的I/O压力,那么即使是正常的数据库操作(如读写数据页到缓冲池),也会因为物理磁盘响应迟缓而变慢,这会导致持有信号量的时间被动延长,从而引发等待。
第四,服务器资源不足。 如果数据库服务器的CPU负载长期处于100%,或者内存严重不足,导致系统频繁使用交换分区(SWAP),整个系统的处理能力会急剧下降,所有操作都会变慢,包括获取和释放信号量的过程,从而可能触发这个错误。
第五,罕见的MySQL或InnoDB内部Bug。 在极少数情况下,可能是MySQL软件本身存在的缺陷导致了死锁或资源无法释放,这种情况通常需要升级到更新的MySQL版本来解决。
当这个错误发生时,它通常会记录在MySQL的错误日志文件中,你可能会看到类似这样的日志内容:“[ERROR] [MY-012993] [InnoDB] A long semaphore wait: --Thread 12345 has waited at btr0cur.c line 579 for 241 seconds the semaphore: X-lock on RW-latch...”,这条日志非常关键,它指出了等待发生的具体代码文件、等待的线程ID、以及等待了多长时间。
要快速修复和解决这个问题,不能简单地重启数据库了事(虽然重启能暂时恢复,但根源未除,问题必定重现),需要按照以下步骤进行诊断和根治:
第一步:立即诊断,找到元凶。
- 查看MySQL错误日志:这是首要任务,日志会明确告诉你信号量等待了多久,以及发生在哪个内部函数中,这能帮你判断问题的严重性。
- 使用
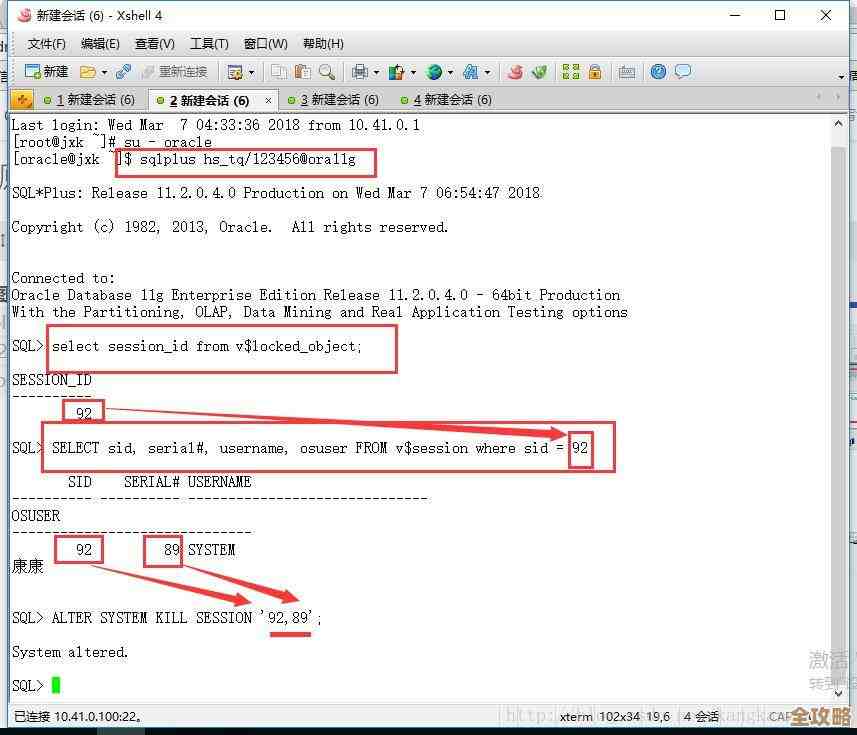
SHOW ENGINE INNODB STATUS命令:连接到MySQL数据库,执行这个命令,在输出的“LATEST DETECTED DEADLOCK”(最新死锁)部分,有时会包含导致阻塞的事务信息,但更重要的是“TRANSACTIONS”(事务)部分,它可以显示当前所有活跃的事务。 - 查询信息模式(Information Schema)表:执行一些查询来找出正在运行的慢查询和锁等待情况。
SELECT * FROM information_schema.INNODB_TRX;:查看当前所有正在执行的事务,关注执行时间(trx_started)过长的事务。SHOW PROCESSLIST;:查看当前所有数据库连接正在执行的SQL语句,重点观察“Time”列数值很大(表示执行了很久)、“State”为“Waiting for ... lock”或类似等待状态的连接,并记录下它们的“Id”和完整的SQL语句。
第二步:实施紧急操作,快速恢复服务。
如果数据库已经几乎无响应,首要目标是恢复服务。
- 终止问题查询:通过上一步找到那些执行时间极长的SQL语句的连接ID(例如是12345),然后执行
KILL QUERY 12345;命令来终止这个特定的查询,如果终止查询无效,可以执行更严厉的KILL CONNECTION 12345;来断开整个连接,这能立即释放被占用的“信号量钥匙”,让其他等待的线程继续工作。 - 谨慎重启:如果上述方法无效,或者有大量连接被阻塞,可以考虑重启MySQL服务,这是最后的手段,因为会中断所有正在进行的业务。
第三步:进行根治优化,防止复发。
紧急恢复后,必须分析根本原因,否则问题还会再来。
- 优化SQL语句:分析你在第一步中找到的那些慢查询,使用
EXPLAIN命令来查看SQL的执行计划,检查是否使用了合适的索引,最常见的解决方案就是为查询条件中的字段添加索引,如果慢查询是SELECT * FROM users WHERE username LIKE '%abc%';,就需要考虑是否能用全文索引(FULLTEXT INDEX)或其他查询方式来优化。 - 优化数据库架构和硬件:
- 架构:对于高并发更新场景,可以考虑引入缓存(如Redis)来减少对数据库的直接压力,或者进行读写分离。
- 硬件:如果I/O是瓶颈,强烈建议将硬盘升级为SSD固态硬盘,这能极大提升数据库的响应速度。
- 调整MySQL配置参数:在某些情况下,可以咨询专业人士后适当调整InnoDB相关的参数,例如
innodb_lock_wait_timeout(控制锁等待超时时间)等,但这不是首选方案,优化SQL和索引才是根本。
遇到MY-012993(ER_IB_MSG_1168)错误,不要慌张,它的核心是“等待”,而等待的根源往往是性能低下的SQL查询,解决问题的标准流程是:首先通过日志和系统表定位到导致阻塞的具体SQL语句或事务,然后果断终止它以恢复服务,最后集中精力分析和优化这条SQL语句(通常是添加索引),从而从根本上解决问题。

本文由雪和泽于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/81377.html