远程访问SQL数据库时延迟太高,怎么才能快点响应呢?

远程访问数据库感觉慢,就像隔着很远的距离打电话,声音总要等一会儿才传过来,这个问题非常普遍,其核心原因就是数据需要经过漫长的网络旅程才能从远处的数据库服务器到达你的应用程序,想要解决它,我们不能只盯着数据库本身,需要从多个层面入手。
最直接也最有效的方法,就是让数据库离你的应用程序近一些,这里的“近”指的是网络路径上的接近,想象一下,如果你的应用服务器在美国东海岸,而数据库服务器在美国西海岸,数据每次传输都要横跨整个美国大陆,延迟自然就高。选择一个地理位置优化的云服务提供商或数据中心是关键,你应该将应用程序和数据库部署在同一个云服务商的同一个可用区(Availability Zone)内,这样它们之间的通信就走的是高速的内网,延迟可以降到极低的毫秒级,甚至更低,如果应用和数据库必须在不同区域,那么至少选择网络连接良好的区域,一些云服务商还提供全球加速网络服务,可以帮助优化跨地域的数据传输路径。
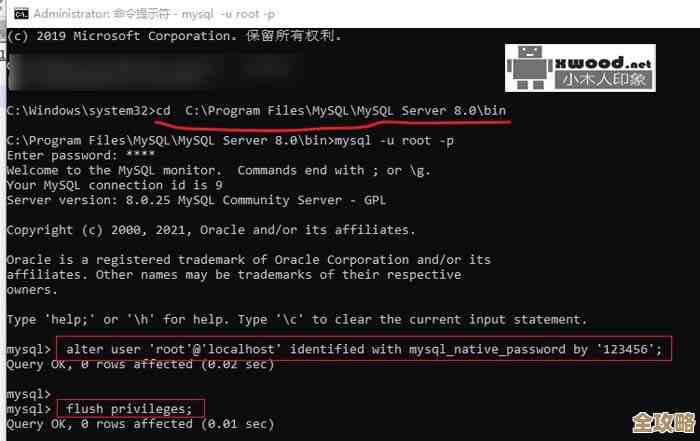
要仔细检查并优化你的数据库查询语句,很多时候,延迟高的罪魁祸首并不是网络,而是效率低下的查询,一个糟糕的查询可能让数据库在后台做了大量不必要的“体力活”,比如全表扫描(就像在图书馆里从第一本书开始逐本查找,而不是用索引目录),导致最终返回结果的时间变得很长,即使网络很快,这个固有的慢查询也快不起来,你应该养成分析查询性能的习惯,大多数数据库系统都提供了查询分析工具(例如MySQL的EXPLAIN命令,PostgreSQL的EXPLAIN ANALYZE),这些工具可以告诉你数据库是如何执行你的SQL语句的,在哪里出现了瓶颈,常见的优化手段包括:为经常用于查询条件的字段创建索引(就像给书加上目录);只查询需要的字段,避免使用“SELECT *”;以及优化表的结构设计,避免复杂的表连接,根据数据库管理领域的普遍经验,超过80%的数据库性能问题可以通过优化查询来解决。
第三,充分利用缓存机制,缓存的核心思想是“用空间换时间”,既然远程访问慢,那我们就把一些经常被查询、但又不太频繁变化的数据暂时存放在离应用更近的地方,这个地方就是缓存,常见的做法是使用Redis或Memcached这样的内存数据库作为缓存层,当应用需要数据时,首先去快速的缓存中查找,如果找到了(这被称为“缓存命中”),就直接返回结果,完全避免了这次远程的数据库查询,速度会得到数量级的提升,只有在缓存中没有找到时,才去查询远程数据库,并将查询结果存一份到缓存中,供下一次请求使用,这种方法特别适用于热点数据,比如网站的首页内容、用户的基本信息等,但需要注意缓存的过期策略,确保数据的一致性。
第四,审视你的应用程序代码逻辑,延迟高是因为应用层进行了不必要的、重复的数据库交互,一个典型的反面教材是“N+1查询问题”:你先查询一个用户列表(1次查询),然后为了列表中的每一个用户(N个),再单独发起一次查询去获取他们的详细信息(N次查询),这样总共进行了N+1次数据库往返,即使每次查询都很快,累积起来的延迟也会非常可观,正确的做法是,尽量通过一次查询或尽可能少的查询来获取所有需要的数据,比如使用表连接(JOIN)或批量查询,减少应用与数据库之间的网络往返次数,对降低总体延迟至关重要。
考虑使用连接池,对于Web应用这类需要频繁处理短时请求的场景,为每个请求都建立一个新的数据库连接是非常耗时的操作,因为建立TCP连接和数据库的认证过程本身就有不小的开销,连接池的作用是预先创建并维护一组活跃的数据库连接,当应用需要与数据库交互时,它直接从池中取用一个现成的连接,用完后归还,而不是关闭它,这样就避免了每次请求都经历漫长的连接建立过程,尤其在高并发场景下,对降低延迟和提升系统吞吐量有显著效果。
解决远程数据库访问延迟高的问题是一个系统工程,你需要从“网络距离”、“查询本身”、“缓存策略”、“应用代码”和“连接管理”这五个方面综合排查和优化,通常情况下,将这些方法结合使用,就能显著提升响应速度,让远程访问数据库的体验变得流畅。

本文由太叔访天于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/80785.html