ORA-00489错误导致ARB进程挂了,远程修复和排查思路分享

前段时间,我们遇到了一个比较棘手的生产数据库问题,当时是晚上,监控系统突然告警,提示数据库的某个备库(Dataguard备库)的ARB进程(Archiver Process)异常终止,导致主库传输过来的归档日志(Archive Log)无法在备库上正常应用,数据同步中断。
问题现象与初步判断
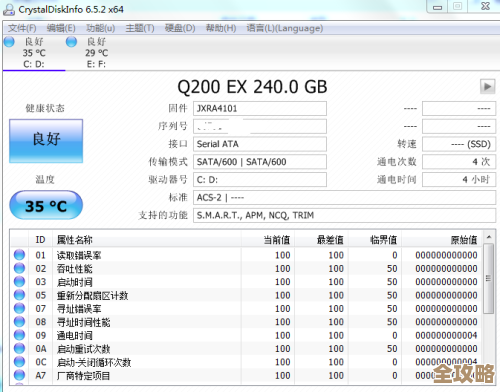
我通过远程连接到备库服务器,检查了数据库的告警日志(Alert Log),这是排查Oracle数据库问题的第一步,也是最关键的一步,在告警日志中,我清晰地看到了错误信息:
ORA-00489: 无法自动创建或替换已知的进程:ARB0
Errors in file /u01/app/oracle/diag/rdbms/stdby/stdby/trace/stdby_arb0_12345.trc:
ORA-00489: 无法自动创建或替换已知的进程:ARB0日志里还显示ARB进程尝试启动但立即失败,紧接着就是进程挂掉的记录,这个错误代码ORA-00489的字面意思是Oracle无法自动创建或替换一个它“知道”的进程,这里特指ARB0进程,ARB进程是Dataguard环境中专门负责接收和应用归档日志的进程,它挂了,数据同步自然就停了。
深入排查:为什么ARB进程起不来?
看到ORA-00489,我的第一反应是进程数可能达到了系统或数据库的限制,Oracle数据库运行在操作系统上,会受到两层限制:操作系统级别的用户进程数限制和数据库内部的最大进程数参数限制。
-
检查操作系统级限制(Linux/Unix环境): 我立刻执行了
ulimit -u命令,查看当前Oracle用户允许的最大进程数,结果显示是一个数值,比如65536,这个值看起来是足够的,通常不会是因为这个限制,但为了保险起见,我也核对了/etc/security/limits.conf文件,确认Oracle用户的配置没有在近期被意外修改。
-
检查数据库级参数: 这是最可能出问题的地方,我连接到备库实例(可能处于MOUNT状态或READ ONLY WITH APPLY状态),查询了相关参数:
processes: 这个参数定义了数据库允许同时连接的最大操作系统进程数,我查询了当前值show parameter processes,发现设置是1500。sessions: 基于processes参数衍生而来,通常没问题。- 关键检查点:当前已使用的进程数。 我执行了SQL查询:
select count(*) from v$process;,查询结果让我发现了问题所在:当前已存在的进程数量已经非常接近甚至达到了processes参数设定的1500上限!
问题根源分析
为什么备库的进程数会这么多?备库通常只有少量的应用进程和后台进程,不应该有这么多连接,我进一步排查:
- 使用
select program, count(*) from v$process group by program;查看进程类型分布,发现有很多来自中间件服务器IP的“sqlplus”或应用程序连接。 - 立刻意识到:这个备库可能被错误地用于了一些查询报表业务,或者有大量的无效连接没有及时释放,导致连接数耗尽。 由于总的进程数配额被这些“不务正业”的连接占满了,当ARB进程因为某种原因(比如日志切换)需要重启时,系统发现已经没有空闲的“进程槽”可供分配,于是抛出了ORA-00489错误,ARB进程就无法正常启动。
远程修复步骤

找到原因后,修复思路就清晰了:释放多余的连接,为ARB进程腾出资源,然后重启它。
-
清理无效连接(谨慎操作):
- 我需要识别出哪些是非核心的、可以杀掉的会话,我查询了
v$session视图,根据PROGRAM,MACHINE,LAST_CALL_ET(最后一次调用经过的秒数)等字段,找出长时间空闲的、来自报表服务器或特定应用的会话。 - 重要: 在备库上杀会话要特别小心,确保不会杀掉维持Dataguard同步的核心后台进程(如MRP等),我仔细过滤,只选择那些明显是用户连接的SESSION_ID。
- 使用
alter system kill session 'SID, SERIAL#' immediate;命令逐个杀掉这些空闲或非必要的会话,每杀一批,就检查一下v$process的计数是否下降。
- 我需要识别出哪些是非核心的、可以杀掉的会话,我查询了
-
重启ARB进程:
- 当进程数回落到安全水平(比如远低于
processes参数上限)后,我尝试重启ARB进程,对于物理备库,这通常意味着重启Redo Apply服务。 - 如果备库处于“READ ONLY WITH APPLY”状态,我先停止应用:
alter database recover managed standby database cancel; - 然后重新启动应用:
alter database recover managed standby database disconnect from session; - 再次查看告警日志,确认ARB进程已经成功启动,并且开始正常应用归档日志,与主库的差距逐渐缩小。
- 当进程数回落到安全水平(比如远低于
-
根本解决与预防:
- 临时扩容: 为了防止问题短期内再次发生,我临时将数据库的
processes参数适当调大(例如从1500调到2000),这是一个动态参数,可以直接修改:alter system set processes=2000 scope=both;。 - 寻找根源: 联系相关业务团队,确认为何有大量连接连到备库,如果是合理的只读查询,需要评估并正式设置合适的
processes参数值,如果是不合理的连接,则需要从应用端切断连接源。 - 设置监控: 在监控系统中,增加对备库“当前进程数”与“最大进程数”比值的监控告警,设定一个阈值(如80%),当接近限制时提前告警,以便我们提前干预,避免问题再次发生。
- 临时扩容: 为了防止问题短期内再次发生,我临时将数据库的
这次ORA-00489错误的排查,核心思路是“资源耗尽”,ARB进程挂掉只是一个表象,根本原因是数据库的总进程资源被其他连接占用,导致关键进程无法正常工作,排查路径非常直接:查告警日志 -> 检查系统级和数据库级资源限制 -> 分析资源占用情况 -> 释放资源 -> 恢复服务 -> 从根本原因上预防,在Dataguard环境中,务必严格控制备库的连接,避免其承担计划外的业务负载,是保持数据同步稳定的关键。
本文由革姣丽于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/77276.html