双11背后那些数据库技术的变化和升级,阿里巴巴是怎么撑起超级工程的

根据阿里巴巴官方技术博客“阿里技术”在历年双11后发布的技术复盘文章,以及一些技术负责人的公开分享,我们可以梳理出双11背后数据库技术变化升级的脉络,看阿里巴巴是如何一步步撑起这个超级工程的。
早期:手工时代的“人肉运维”与瓶颈初现
在双11的早期阶段,大概2010年前后,阿里巴巴面临的数据库挑战非常直接,当时主要使用的是传统的关系型数据库,比如Oracle,这些数据库在平时表现稳定,但到了双11零点,交易量瞬间爆发,就像千军万马要同时过一座独木桥,数据库立刻成为最脆弱的瓶颈。

根据阿里技术文章描述,那时的状态可以说是“人肉运维”,工程师们需要提前好几个月进行“容量规划”,估算需要多少台数据库服务器,到了双11当天,技术人员严阵以待,像消防队员一样,随时准备处理数据库的“报警”,比如CPU使用率飙升、慢查询增多等,他们常用的手段很原始但有效,比如在零点高峰期手动关闭一些不重要的统计功能,或者把流量从一台压力大的数据库“切”到另一台压力小的上,这种方式高度依赖工程师的个人经验和临场反应,风险极高,一次操作失误就可能导致整个系统瘫痪。
中期:去“IOE”与自研分布式数据库OceanBase的崛起
阿里巴巴意识到,依赖国外的商业数据库和高端硬件(即IOE体系:IBM小型机、Oracle数据库、EMC存储)不仅成本高昂,而且无法从根本上解决双11这种特有场景的极限压力,他们启动了去“IOE”战略,核心就是用廉价的普通PC服务器替代昂贵的小型机,并开始自研能跑在这种集群上的分布式数据库。

这就是OceanBase诞生的背景,根据OceanBase创始人阳振坤的多次分享,OceanBase的设计理念与传统数据库完全不同,它不再追求单台机器的强大,而是通过软件技术将许多普通服务器组织成一个整体,就像蚂蚁搬家,一只蚂蚁力量小,但成千上万只蚂蚁可以搬动比自身重很多倍的食物。
OceanBase采用了“分布式”架构,它可以把一张巨大的用户订单表,自动切分成很多小块,分散存储到上百台甚至上千台服务器上,当双11来临,一笔交易可能只涉及到其中一两台机器,其他机器可以并行处理其他交易,这样就实现了压力的分摊,解决了单点瓶颈的问题,它通过数据多副本复制技术,任何一台服务器宕机,系统都能自动切换到备用副本,保证了数据的可靠性和服务的高可用性,OceanBase在2017年首次全面承担了双11的核心交易流量,并经受住了考验,标志着阿里巴巴在数据库层面具备了世界级的自主研发能力。
全面云原生化与智能化运维

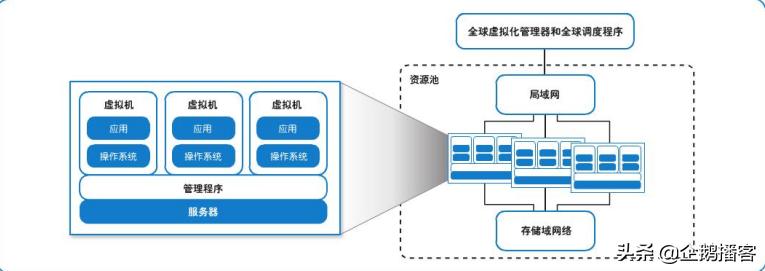
近几年,双11的数据库技术进入了“云原生+智能化”的时代,根据阿里云数据库团队的分享,他们的核心思路是让数据库资源像水和电一样,可以按需分配、弹性伸缩。
“云原生”意味着数据库服务完全构建在云计算基础设施之上,在双11之前,系统可以根据历史数据预测流量高峰,自动提前“扩容”,快速增加计算和存储资源,而无需人工干预,在双11结束后,系统又会自动“缩容”,释放不必要的资源,大大节约了成本,这种弹性能力是传统物理机时代无法想象的。
另一个重要变化是“智能化运维”,阿里巴巴将人工智能和机器学习技术应用到了数据库的管控中,根据“阿里技术”的文章介绍,他们开发了名为“达灵”的智能管控平台,这个平台可以实时监控所有数据库实例的健康状况,不再需要工程师24小时盯着屏幕,它能够自动发现异常,比如某个SQL查询突然变慢,并能够进行根因分析,甚至自动进行优化或故障处理,实现了“自动驾驶”式的运维,这极大地降低了运维人员的负担,也提高了系统的稳定性。
阿里巴巴撑起双11这个超级工程的数据库技术演进路径非常清晰:从早期依赖国外商业软件、手工运维的被动局面,到中期通过自研分布式数据库OceanBase实现技术突破,解决可扩展性和高可用性的核心难题,再到近期利用云原生和智能化技术,实现极致的弹性效率和自动化运维,这个过程不仅是技术的升级,更是从“人治”到“技治”的理念转变,最终让庞大的数据库系统在双11的惊涛骇浪中,变得像一艘拥有智能导航和自动驾驶功能的超级巨轮,稳健前行。
本文由寇乐童于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/77717.html