Redis模块化开发其实可以有些新玩法,试试看这些方法能不能帮你更灵活地搭建系统

最近在琢磨Redis的使用,发现大家用Redis,很多时候就是当个缓存或者存个会话,但其实它的潜力远不止于此,如果我们换一种思路,用模块化的眼光去看待Redis,它能帮我们搭建出更灵活、更解耦的系统,这就像玩乐高,Redis提供了各种基础积木块,怎么搭出有趣的建筑,就看我们的想象力了。
别只把Redis当缓存,把它看作“内存数据服务中心”

这个想法是受一篇关于Redis架构思想的文章启发,核心是,别让每个微服务都直接去操作Redis,相反,我们单独建立一个专门负责所有Redis数据操作的服务,可以叫它“缓存服务”或“数据服务”。(来源:某技术社区关于Redis架构模式的讨论)
- 怎么玩?
- 以前:订单服务要查用户信息,用户服务要更新积分,两个服务都直接连同一个Redis实例,写类似的代码,一旦数据结构要变,两个服务都得改。
- 订单服务需要用户信息,不是直接去Redis里取,而是通过一个HTTP接口或者RPC调用,去问这个新建的“数据服务”要。“数据服务”统一负责从Redis里拿数据、转换格式、处理缓存逻辑(比如缓存穿透、雪崩等)。
- 好处在哪?
- 解耦:各个业务服务(订单、用户)不需要关心数据具体存在Redis的哪个结构里,也不需要懂Redis命令,它们只关心业务逻辑,数据怎么存、怎么取,是“数据服务中心”的事。
- 易维护:所有关于Redis的升级、数据结构变更、缓存策略优化,都只需要在这个“数据服务中心”里做一次修改就行了,不影响其他业务服务。
- 安全可控:Redis的访问权限可以收紧,只允许这个“数据服务”的服务器连接,降低了数据库直接暴露的风险。
用Redis的“模块”功能,打造专属工具

Redis从4.0版本开始支持模块化,这意味着我们可以用C语言为Redis开发新的数据类型和命令,这个玩法比较硬核,但想象空间很大。(来源:Redis官方文档关于Modules的介绍)
- 怎么玩?
- 你有个特殊需求:要频繁查询某个商品的浏览次数,并且需要非常精确,用普通的
INCR命令虽然快,但如果并发极高,可能还是会想有没有更优解。 - 这时候,可以自己写一个Redis模块,实现一个名为
product.viewcount的新数据类型,这个类型内部可能用了更高效的数据结构,比如结合了字典和跳表,并提供一个像PRODUCT_INCRVIEW这样的专属命令来操作它。
- 你有个特殊需求:要频繁查询某个商品的浏览次数,并且需要非常精确,用普通的
- 好处在哪?
- 极致性能:为特定场景量身定做的数据结构和命令,性能可能远超通用命令。
- 功能扩展:不再受限于Redis原生的几种数据结构,你可以实现一个支持复杂图计算的模块,或者一个全文搜索引擎模块(RediSearch就是成功的例子),直接把Redis变成一个多面手。
- 业务封装:复杂的业务逻辑可以下沉到模块中,对上层应用只暴露简单的几个命令,应用层代码会变得非常清爽。
利用Pub/Sub和Streams,让Redis成为系统“神经中枢”

Redis自带的发布订阅(Pub/Sub)和更强大的流(Streams)数据结构,是实现模块化通信的利器,这有点像在系统内部搭建了一个小型的“消息队列”或“事件总线”。(来源:多位开发者分享的基于Redis的异步解耦实践)
- 怎么玩?
- 事件驱动架构:当用户成功注册后,用户服务不直接去调用积分服务送积分、不发欢迎邮件,它只需要向一个叫
user.registered的Redis频道(Channel)或者流(Stream)发布一条消息。 - 积分服务和邮件服务提前订阅了这个频道或监听这个流,它们一收到消息,就各自去执行送积分和发邮件的任务,用户服务发完消息就返回了,根本不用等它们处理完。
- 事件驱动架构:当用户成功注册后,用户服务不直接去调用积分服务送积分、不发欢迎邮件,它只需要向一个叫
- 好处在哪?
- 彻底解耦:服务之间完全不知道对方的存在,只通过消息通信,增加一个新的监听者(比如注册后再发个短信),完全不需要修改用户服务的代码。
- 异步化,提高响应速度:主流程(用户注册)变得非常快,耗时长的任务(发邮件)被异步处理。
- 弹性伸缩:如果某天注册用户暴增,邮件处理不过来,可以轻松地多启动几个邮件服务实例来共同消费消息,负载自然就分摊了。
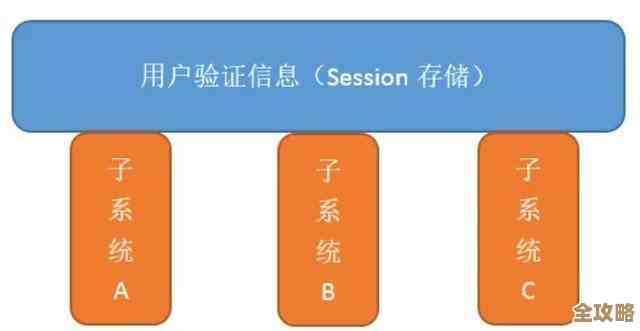
为不同数据类型,建立不同的Redis实例
最简单的模块化就是物理分离,与其把所有数据都塞进一个Redis实例,不如按数据类型或业务重要性进行拆分。(来源:常见的Redis性能优化建议)
- 怎么玩?
把会话(Session)数据放在一个Redis实例A里,把排行榜这类高频读写的数据放在实例B里,再把一些重要的业务配置数据放在实例C里。
- 好处在哪?
- 故障隔离:如果排行榜的某个操作出了问题,导致实例B负载过高甚至崩溃,不会影响到用户正常的登录会话(实例A)。
- 性能优化:可以为不同类型的实例配置不同的内存淘汰策略、持久化策略,比如会话实例可以设置
volatile-lru策略,而配置数据实例可以设置noeviction策略确保不丢失。 - 管理清晰:哪个实例对应哪些数据,一目了然,管理和监控起来都更方便。
跳出“Redis equals 缓存”的固定思维,把它看作一个高性能的、多才多艺的内存数据平台,我们就能用模块化的思想玩出更多花样,无论是通过架构设计上的服务拆分,还是利用其强大的原生功能,目的都是为了构建一个更加灵活、健壮和易于扩展的系统,希望这些玩法能给你带来一些新的启发。
本文由太叔访天于2026-01-06发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/75796.html