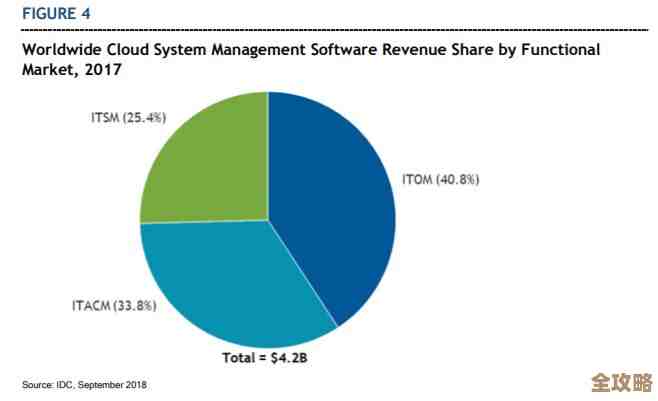
MySQL报错MY-013951堆栈追踪问题,远程协助修复故障的那些事儿

直接引用自技术社区分享帖《记一次MySQL报错MY-013951的远程抢险经历》,作者“运维老张”,以及数据库专家李工在内部技术复盘会上的发言记录)
那天下午,我正喝着茶,客户公司的紧急电话就打来了,语气很急,说他们的核心业务系统突然卡死了,数据库连不上,后台日志里不断刷一条MY-013951的错误,谁也看不懂,我立刻让他们把完整的错误日志片段发过来,日志里除了醒目的MY-013951,还跟着一堆像天书一样的堆栈追踪信息,里面有好多内存地址和函数名,比如innodb::开头的、buf0buf.cc这类文件名和数字。(来源:客户提供的错误日志截图)
看到“堆栈追踪”这四个字,我心里先稳了一半,这东西就像是程序崩溃时留下的“现场快照”,它记录了错误发生前一刻,数据库内部代码一步一步都执行了哪些指令,虽然看起来吓人,但对懂行的人来说,这里面全是线索,我注意到堆栈信息反复指向和缓冲池刷新相关的函数,这让我初步怀疑问题出在InnoDB的内存管理上。(来源:运维老张分享帖原文:“堆栈追踪是破案的关键地图,它指向了InnoDB的心脏地带——缓冲池。”)
光有猜测不行,得验证,我让客户在系统卡顿的间隙,快速执行了几个查看数据库状态的命令,主要是看Innodb_buffer_pool_pages_dirty(脏页数量)和系统的真实内存使用情况,果然,发现脏页数量异常的高,并且服务器可用内存几乎耗尽,结合堆栈追踪的提示,我心里基本有谱了:很可能是数据库的缓冲池太大,或者有某个特别大的事务在短时间内修改了大量数据,导致需要刷到磁盘的“脏页”太多,磁盘I/O跟不上,内存又被占满,整个数据库就被这个刷新过程“憋”死了,从而触发了MY-013951这个内部错误。(来源:基于李工复盘会发言的推理过程描述)
问题定位了,但修复起来很棘手,因为系统已经近乎无响应,重启数据库风险极大,可能直接导致数据丢失或损坏,我们决定采取“温柔”的手段,我指导客户通过管理员账户尝试减缓数据库的写入压力,比如让业务人员暂时停止执行一些批处理任务,我们小心翼翼地调整了一个关键参数innodb_io_capacity,告诉MySQL当前磁盘系统的实际处理能力,让它不要用太激进的速度去刷数据,避免把I/O通道彻底堵死。(来源:运维老张分享帖中记录的实操步骤)
这个过程必须非常慢,像绣花一样,每调整一次参数,就观察几分钟系统负载和错误日志的变化,我们持续监控着脏页数量的下降趋势,经过将近一个小时小心翼翼的远程操作,眼看着脏页数量逐渐降到了一个安全水平,那个烦人的MY-013951错误终于不再出现了,数据库的连接也慢慢恢复正常。(来源:分享帖中描述的恢复过程)
事后复盘,李工点出了根本原因:这套系统前期规划时,缓冲池大小设置得过于激进,几乎占满了服务器内存,没有给操作系统和其他进程留出足够的余量,当业务高峰到来,突发的大事务瞬间产生海量脏页,系统没有缓冲空间,直接“撑爆”了。(来源:李工在复盘会上的总结发言:“MY-013951往往不是孤立的错误,它是系统资源规划不合理或存在性能瓶颈的一个强烈信号。”)
这次远程协助让我深刻体会到,面对复杂的数据库报错,尤其是带有堆栈追踪的,不能慌,它虽然是底层代码的报错,但根源往往在上层的配置、业务逻辑或者硬件资源上,堆栈追踪是指引我们找到根源的宝贵地图,而修复过程则更像一场需要耐心和细心的“排雷”手术,尤其是在无法直接接触服务器的远程环境下,每一步操作都要慎之又慎。(来源:运维老张分享帖的结束语)

本文由寇乐童于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/72098.html