用Redis消息队列来搞有序消息处理,感觉挺实用也不复杂

用Redis消息队列来搞有序消息处理,感觉挺实用也不复杂,这个想法其实挺自然的,因为Redis本身速度飞快,而且它提供的数据结构,比如列表(List)和有序集合(Sorted Set),天生就适合用来模拟队列的行为,当我们在谈论“有序消息处理”时,通常指的是消息按照某种顺序被生产出来,并且消费者也严格按照这个顺序来一个一个地处理,不能乱套,一个用户先下了订单,然后才付款,最后才是发货,这三个消息就必须按顺序处理,如果发货的消息跑到了最前面,那系统就乱套了。
为什么是Redis,而不是专业的消息队列?
像RabbitMQ、Kafka这些都是非常专业的消息中间件,功能强大,但它们也相对重一些,搭建、配置和维护都需要一定的成本,对于很多中小型项目,或者是对消息队列功能要求不那么极致的场景,专门引入一个大家伙可能有点“杀鸡用牛刀”的感觉,这时候,Redis的优势就体现出来了,很多项目本身就已经在用Redis做缓存了,那么再利用它来实现一个轻量级的消息队列,几乎是零成本的,Redis的性能非常高,对于消息量不是天量级别的场景,完全够用。
最直接的玩法:利用List结构
Redis的List数据结构,底层实现是双向链表,它支持从左边插入(LPUSH),从右边取出(RPOP),或者从右边插入(RPUSH),从左边取出(LPOP),这简直就是为队列量身定做的。

- 生产者:每当有一个需要按顺序处理的任务时,比如用户完成了一个步骤,就使用
LPUSH命令(或RPUSH,取决于你定义的方向)将一个消息放入一个特定的List中。LPUSH order_queue '{"userId": 123, "action": "place_order"}',这样,后产生的消息会在List的头部(或尾部)。 - 消费者:启动一个或多个后台工作进程,不断地使用
BRPOP命令从这个List中阻塞地取出消息。BRPOP的好处是,如果队列是空的,它会一直等待,直到有消息到来或者超时,这样就不会白白浪费CPU资源去循环空转,取出的消息,就是按照生产者放入的顺序来的,先进先出(FIFO),保证了顺序性。
这种方式非常简单直观,代码写起来也快,但它有一个小问题,就是它不保证消息的“可靠性”,什么意思呢?就是消费者从队列里用 BRPOP 取出消息后,这条消息就在Redis里消失了,如果消费者在处理这个消息的时候突然崩溃了,还没来得及处理完,那这个消息就永远丢失了,这对于一些对数据准确性要求不高的场景可能还行,比如发一条通知日志,但对于订单、支付这类关键业务,这是绝对不能接受的。
更靠谱的玩法:使用Sorted Set和List组合拳
为了解决消息可能丢失的问题,我们可以想个办法,让消息被“安全”地取走,一个常见的思路是借鉴RabbitMQ里的ACK(确认)机制,用Redis怎么模拟呢?可以结合使用List和Sorted Set,或者利用Redis的发布订阅(Pub/Sub)但加上持久化方案,不过这里说一个更常见的基于List的“可靠队列”模式。

这个模式需要一点点技巧:
- 预备队列和工作队列:我们准备两个List,一个叫
pending_queue(预备队列),一个叫processing_queue(处理中队列)。 - 生产者不变:还是把消息
LPUSH到pending_queue。 - 消费者取消息:消费者不使用简单的
RPOP,而是使用RPOPLPUSH这个原子性命令,这个命令非常关键,它能原子性地从pending_queue的右边弹出一个消息,并同时把这个消息LPUSH到processing_queue中,这一步确保了消息不会丢,它只是从一个队列转移到了另一个“正在处理”的队列。 - 消费者处理消息:消费者开始处理这条消息。
- 确认完成:如果处理成功,消费者再使用
LREM命令从processing_queue中移除这条消息,这样,这个消息的生命周期就结束了。 - 处理失败怎么办?:如果消费者在处理过程中崩溃了,那么这条消息会一直留在
processing_queue里,我们需要有一个额外的“监控程序”或“补偿机制”,定期去扫描processing_queue里停留时间过长的消息(比如超过5分钟),认为它们处理超时了,然后再把这些消息重新放回pending_queue的头部,让其他健康的消费者重新处理。
这种方法虽然比第一种要复杂一些,需要维护两个队列和一个处理超时的逻辑,但它实现了基本的可靠性,保证了消息至少会被处理一次(at-least-once delivery),顺序性也依然保持。
一些需要注意的坑
用Redis搞消息队列虽然方便,但也有一些局限性要知道:
- 没有高级功能:像专业消息队列那样的消息路由、分组消费、流量控制、回溯消费等高级功能,Redis是没有的,如果你的业务场景需要这些,那还是得用专业的。
- 持久化策略:Redis的持久化有RDB(快照)和AOF(日志)两种,你需要根据对消息丢失的容忍度来配置合适的持久化策略,如果配置不当,Redis服务器宕机可能导致内存中的消息丢失。
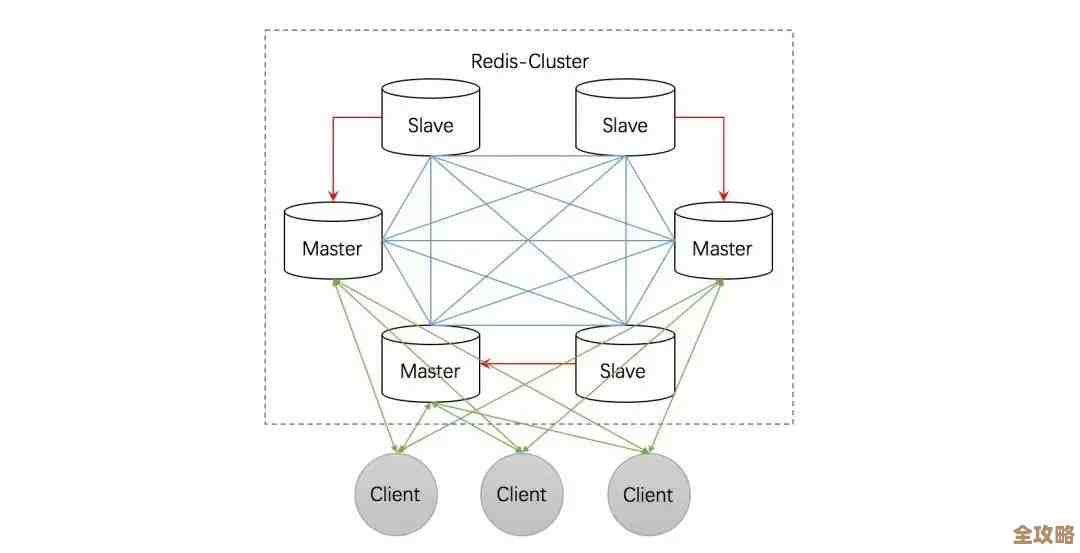
- 集群问题:在Redis集群模式下,一个List会整个存储在一个节点上,如果这个List非常大,可能会导致集群数据分布不均匀。
RPOPLPUSH这类涉及多个key的操作在集群模式下可能会受限,需要特别注意。 - 消息堆积:如果生产者速度远大于消费者,消息会在Redis内存中大量堆积,有撑爆内存的风险,这就需要监控队列长度,并设置上限或及时扩容。
用Redis消息队列来处理有序消息,是一个在特定场景下非常经济实用的技术选型,它特别适合那些消息量不大、业务逻辑相对简单、但又需要保证顺序和一定可靠性的后台任务,比如发送交易成功的邮件/短信、更新用户积分、清理缓存等,它的魅力就在于,利用一个已有的、熟悉的工具,通过一些巧妙的组合,就能解决实际问题,避免了引入新系统的复杂性,只要清楚地了解它的能力和边界,它就能成为一个非常好用的利器。
本文由瞿欣合于2025-12-28发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:http://www.haoid.cn/wenda/70001.html