神州云科讲的那个超高可用架构,感觉就是为了让应用能一直稳稳地跑下去吧

关于神州云科所讲述的“超高可用架构”,其核心目标确实如您所感,就是为了让关键的应用和服务能够一直稳定、持续地运行下去,就像给重要的业务上了一道又一道的保险,根据神州云科在多个技术交流场合所阐述的理念,他们并不是在空谈一个遥远的概念,而是着力于解决企业在数字化过程中最头疼的问题:如何避免业务因为各种意想不到的故障而中断。 很实在,这个架构承认故障是不可避免的,硬件会老化、网络会波动、软件会有缺陷,甚至整个数据中心都可能遇到电力或自然灾害问题,他们的思路不是去追求一个永远不坏的“神话系统”,而是建立一个“坏了也能快速恢复、甚至让用户感觉不到坏了”的韧性体系,神州云科在分享中多次强调,其架构设计的出发点就是接受故障,并管理故障。
那么具体怎么做呢?从他们的讲述中可以归纳出几个很接地气的层面:
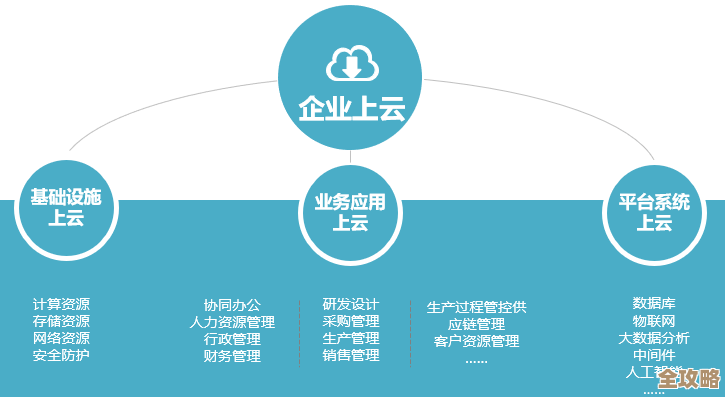
第一是消除单点,好比说,如果只有一个电源,电源一坏全公司停电,他们的做法就是给所有关键的地方都准备“备胎”,服务器不是一台,而是一组,互相备份;网络线路不止一条,是多条同时工作;存储的数据也不会只放在一个磁盘或一个机柜里,神州云科提到,他们的方案会确保从计算、存储到网络,任何一个单独的部件出问题,都有其他部件能立刻顶上,业务不会停摆。
第二是快速切换,光有备胎还不够,换胎的速度是关键,如果一台服务器宕机了,需要人工去排查、重启、恢复数据,可能几小时就过去了,业务损失巨大,他们讲的架构里充满了“自动化”的智慧,通过软件实时监控所有组件的健康状况,一旦发现某个主要部件不行了,系统会自动、快速地把工作任务和流量,切换到之前准备好的健康部件上,这个切换过程非常短,往往在用户还没察觉到“卡了一下”之前就完成了,神州云科在介绍中常以“无缝切换”来形容这个目标。
第三是数据不丢,业务能跑起来,核心是数据,如果服务器切换过去了,但数据没了或错了,那一切也是白费,他们特别注重数据的持久性和一致性,通过实时或近实时地将数据复制到多个地方(比如同城的另一个机房,甚至远在另一个城市的机房),确保哪怕一个地方的数据完全损毁,也能从另一个地方找回来,而且尽可能找回的是最新的数据,他们用“数据多活”或“多副本”这样的表述来强调数据的安全性。
第四是预防和预警,高可用不只是事后的补救,更是事前的预防,神州云科讲的架构里,通常包含全面的监控系统,就像7x24小时在岗的“健康医生”,不断检查着系统的心跳、体温和负荷,它能提前发现一些异常迹象,比如磁盘空间快满了、某个服务响应变慢了,并在问题真正爆发成故障之前就通知管理员处理,把问题扼杀在萌芽状态。
他们往往会谈到容灾演练,再好的架构设计,如果从来没实际检验过,也是纸上谈兵,神州云科建议,要像消防演习一样,定期主动去模拟各种故障(比如故意关闭一台服务器、切断一条网络线路),来验证整个切换和恢复流程是否真的如设计般顺畅,通过这种不断的演练,来完善流程、增强信心,确保真遇到事儿时能不慌乱。
神州云科所讲的超高可用架构,其内容就是围绕“持续稳定”这个目标,构建一个从底层硬件到上层应用、从本地到异地、从故障应对到主动预防的立体化防护体系,它不是为了追求技术的炫酷,而是实实在在地解决业务连续性的痛点,让企业的应用在面对真实世界中的各种不确定风险时,能够“一直稳稳地跑下去”,这一切的讲述,都基于他们对企业IT运维复杂性和业务重要性深刻理解。

本文由寇乐童于2026-01-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/85470.html