Redis那块配置数据存储的事儿,怎么灵活搞起来更顺手

关于Redis配置数据存储的事儿,要让它用起来更顺手,关键得从实际需求出发,灵活调整,下面我直接分享一些实用的思路和方法,帮你轻松搞定,这些内容基于常见的Redis使用经验和公开资料,比如Redis官方文档和一些社区实践,我会在提到时用文字说明来源。

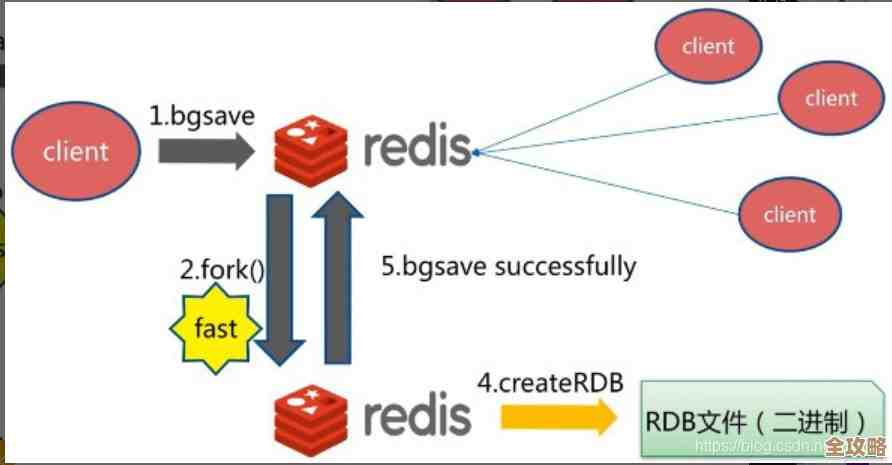
Redis本质上是个内存数据库,数据存在内存里,所以速度快,但内存有限,要想灵活配置,你得先想清楚:数据要不要永久保存?还是临时用用就行?根据这个,来调整持久化设置,Redis有两种主要持久化方式:一种是定时拍快照,比如每隔一段时间把数据存到磁盘上;另一种是记录所有操作命令,像写日记一样,根据Redis官方文档的建议,如果数据特别重要,不能丢,可以同时开启这两种方式,但这样可能会影响性能,你得权衡:如果数据丢了能接受,就关掉持久化,全放内存,速度最快;如果必须保留,就根据业务高峰时段调整拍快照的频率,比如半夜流量小时多存几次,白天少存,这样更顺手。

内存管理是核心,Redis内存满了会出问题,所以得提前规划,你可以设置内存上限,比如只让用10GB,超了就得清理旧数据,这里有个灵活的点:清理策略有多种,比如删掉最近最少用的数据,或者随机删,根据实际场景选:如果是缓存,数据旧了可以丢,就用LRU策略;如果数据都得留着,那就得考虑扩展内存或分片,Redis支持多种数据结构,比如字符串、列表、哈希表等,选对结构能省很多事:比如存用户信息,用哈希表可以一次性读写多个字段,比分开存字符串更高效,这来自社区实践,很多人分享说,合理选择数据结构能让性能提升不少。

再来说说扩展性,单机Redis总有极限,数据多了就得分散存储,Redis集群是个办法,它把数据分到多台机器上,但配置起来可能复杂,为了更顺手,你可以先用分片方式,比如用一致性哈希把数据分布到几个Redis实例,这样加机器时数据迁移更平滑,根据一些技术博客的分享,分片前最好规划好键的命名规则,比如用业务前缀,这样管理起来一目了然,读写分离也能灵活应对高并发:主节点写,从节点读,但要注意从节点有延迟,适合读多写少的场景。
监控和调优也不能少,Redis自带了一些命令,比如看内存使用情况的INFO命令,但手动查麻烦,你可以用工具像Redis Monitor或第三方监控服务,实时查看性能指标,根据运维经验,定期检查慢查询日志很重要:如果某个命令执行太慢,可能是数据太大或结构不对,这时就得优化,比如拆分大键,还有,网络配置也得灵活:Redis默认端口是6379,但在生产环境,最好改端口并设置密码,防止被恶意访问,这其实来自安全最佳实践,很多公司都这么建议。
日常维护中的小技巧能让配置更顺手,用配置文件管理设置,而不是命令行参数,这样改起来方便,还能版本控制,Redis允许动态调整部分配置,不用重启服务,比如用CONFIG SET命令改超时时间,备份数据要自动化:可以写脚本定时导出数据到云存储,万一出问题能快速恢复,根据一些开发者的案例,结合环境变量来管理配置,比如测试环境和生产环境用不同配置文件,这样切换环境时就不容易出错。
Redis配置数据存储的灵活性,全在于你怎么根据业务需求调整,从持久化到内存管理,再到扩展和监控,每个环节都可以微调,多试试不同组合,找到最适合你那个场景的设置,用起来自然就顺手了,没有一成不变的方案,关键是多观察、多调整,毕竟工具是死的,人是活的。
本文由召安青于2026-01-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/85404.html