Java里头数据库怎么分布式搭建和用,聊聊那些架构设计和实际应用的事儿

说到Java里头搞数据库分布式,这事儿说白了就是一台数据库服务器不够用了,比如数据量太大存不下,或者访问的人太多它忙不过来,这时候就得想办法多找几台机器来一起扛,这就像一个小店生意越来越好,一个人忙不过来,就得招伙计、开分店,但这伙计和分店怎么管,里面的门道就多了。
首先聊聊为啥要分布式。 最直接的动力就是“单机顶不住了”,比如你做了一个电商App,像淘宝那样,每天产生海量的订单、用户数据,一台最好的数据库服务器也存不下,再比如双十一的时候,每秒有几十万人同时抢购,同时下单,这种读写压力单台机器根本处理不过来,数据库会直接崩溃,为了系统能支撑更大的规模和更高的并发,分布式是必由之路,来源方面,像阿里巴巴的淘宝、天猫,以及腾讯、字节跳动这些大厂,他们的业务规模决定了从一开始就必须考虑分布式的架构。
具体怎么搭呢?主要有几个主流的路子。
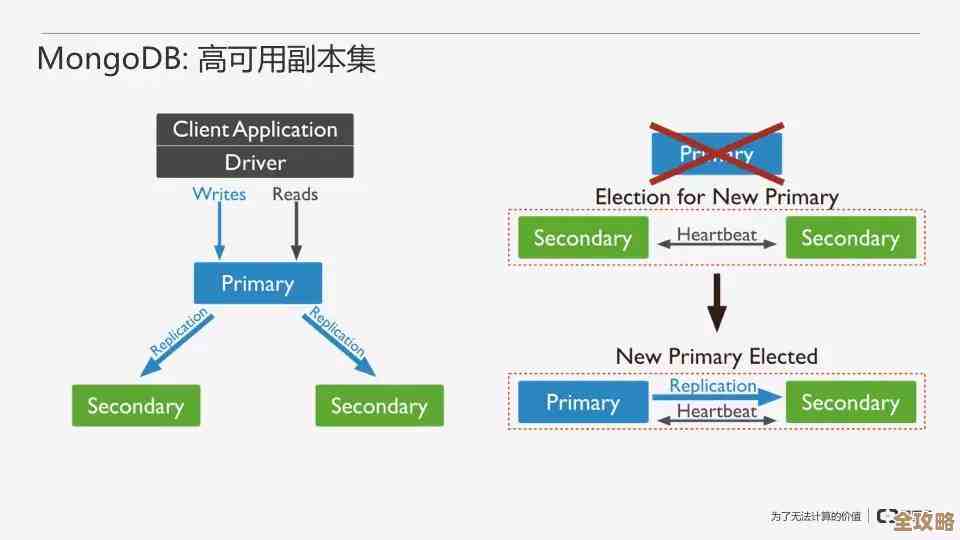
第一个路子,简单粗暴的“主从复制”,这个最好理解,就是弄一个主数据库(Master),专门负责接收数据的写入操作,比如增、删、改,然后挂上好几个从数据库(Slave),主数据库会把写入的数据同步给这些从库,平时读数据的时候,比如用户查询商品、查看订单,就让应用程序去连接那些从库,这样一来,写的压力还是主库一个人扛,但读的压力就分摊给了多个从库,整个系统的读能力就大大提升了,这就像是公司里有一个总经理负责拍板做决策(写),然后有一堆助理(读)负责把决策传达和执行下去,MySQL自带的主从复制功能就是干这个的,在Java程序里,通常用一些中间件(比如ShardingSphere-JDBC)或者配置多个数据源,就能轻松实现读写分离,这是最基础、最常用的一种分布式玩法。
第二个路子,难度升级的“分库分表”,当数据量大到连一个主库都存不下的时候,主从复制就不够了,这时候就得把数据拆开,分散到不同的数据库服务器上去,这又分两种拆法:一种是“垂直分库”,按业务模块来分,比如把用户相关的表放在一个数据库,订单相关的表放在另一个数据库,商品相关的再放一个,这样每个数据库更专注,减少了单库的压力,另一种是“水平分表”,也叫“分片”(Sharding),这是最核心的,比如你有一张用户表,有10亿条数据,一台机器存不下,你就可以定个规则,比如按用户ID的尾号,尾号是0-3的放在第一个数据库,4-6的放第二个,7-9的放第三个,这样每个数据库只存一部分数据,压力就分摊了,在Java里,像ShardingSphere、MyCat这样的中间件就是专门帮我们透明地处理分库分表规则的,让程序员写代码时还像操作单个数据库一样简单,但实际上数据已经分布到各处了,这个方案非常考验架构师的设计能力,比如按什么字段分片才均匀,怎么处理跨分片的查询和事务,都是难题。
第三个路子,直接用现成的“分布式数据库”,上面两种算是“自己动手,丰衣足食”,但管理和维护起来很复杂,所以现在很多公司会选择直接采用新型的分布式数据库,比如TiDB、OceanBase、CockroachDB等,这些数据库生来就是分布式的,它们自己在底层把数据分片、复制、负载均衡这些脏活累活都干了,然后对外提供一个像单机MySQL一样的接口,Java程序直接用标准的JDBC去连接它就行,几乎不用改代码,感觉上还是在用一个大号的、永远不会挂的MySQL,这对于业务开发团队来说,省心太多了,像拼多多、美团这些快速发展的公司,很多业务就迁移到了TiDB上,以应对爆发式增长的数据量。
实际应用中的挑战和考量。 分布式不是银弹,带来好处的同时也引入了一堆新问题,比如最头疼的“分布式事务”,一个操作要同时更新好几个数据库,怎么保证要么全部成功,要么全部失败?现在常用的有最终一致性方案(比如通过消息队列异步补偿)或者使用Seata这样的分布式事务框架,还有就是“跨分片查询”,比如你要统计全站订单总额,就得把每个分片的数据都汇总一次,效率很低,这就要求在设计分片规则时,要充分考虑业务的查询模式。
在Java的世界里,数据库分布式搭建是一个从简到繁、根据业务量力量力而行的过程,从小规模的读写分离,到复杂的分库分表,再到采用一站式的分布式数据库,每一种选择背后都是业务需求、团队技术实力和运维成本之间的权衡,核心思想始终没变:通过增加机器,用空间换时间,换性能,换容量,让系统能够支撑业务的持续发展。

本文由邝冷亦于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/82536.html