用Redis设备搞数据采集,聊聊怎么实现和那些关键点

想象一下,你的公司有好多台服务器,每时每刻都在产生大量的数据,比如用户点击了什么按钮、服务器自身的CPU使用率、或者电商平台上的每一笔订单,这些数据就像无数个小水滴,你需要把它们收集起来,汇入一个大的“数据湖泊”里,然后再进行分析,Redis在这里扮演的角色,就是一个超级高效、超级快速的“临时水桶”。
为什么选Redis做这个“临时水桶”?
它太快了,数据采集最怕的就是“堵车”,前端应用或者服务器日志系统产生数据的速度可能非常快,如果收集数据的中间件本身速度慢,就会成为瓶颈,导致数据积压甚至丢失,Redis的数据都放在内存里,读写速度是微秒级别的,接收这些高速涌来的数据流毫无压力,这就好比用一条宽阔的高速公路来疏导车流,避免了堵死在乡间小路上。
它数据结构丰富,采集上来的数据格式可能是多种多样的,有时候是一条简单的文本日志,有时候是一个包含多个字段的JSON对象,Redis不是简单的Key-Value存储,它提供了List(列表)、Set(集合)、Sorted Set(有序集合)等多种数据结构,最常用的可能就是List,你可以把它想象成一个队列(Queue),采集端从左边(LPUSH)不停地塞入数据,处理端从右边(RPOP)不停地取出数据处理,天然形成了一个“先进先出”的流水线,非常符合数据采集的场景。

具体怎么实现?
一个最简单的流程是这样的:
-
数据产生端(生产者): 这可能是你的网站后台代码、手机APP,或者是部署在服务器上的一个日志收集脚本(比如用Filebeat),每当有需要采集的事件发生,它们就通过Redis的客户端,执行一条类似
LPUSH data_queue '{"userId": 123, "action": "click"}'的命令,把数据作为一个元素,塞进一个叫data_queue的Redis列表里,这个过程非常轻量,对生产端的影响极小。 -
Redis实例: 它就在那里,忠实地接收并暂时存储所有涌来的数据,它的主要任务就是“接”和“存”,保证数据不丢。

-
数据处理端(消费者): 这是后端的另一个服务,比如用Java、Python或者Go写的,它会不停地(或者批量地)向Redis询问:
data_queue里有新数据吗?然后通过RPOP命令把数据取出来,取出来之后,它可能对数据进行一些清洗、格式化,然后存入到更持久、更适合分析的数据仓库里,比如MySQL、HDFS或者ClickHouse。
这个过程听起来很简单,但在实际做的时候,有几个关键点必须得留心,不然很容易踩坑。
那些必须注意的关键点
第一,数据持久化问题,Redis虽然快,但因为数据主要存在内存里,如果服务器突然断电或者宕机,内存里的数据就全没了,这对于数据采集来说是灾难性的,你必须配置Redis的持久化机制,Redis主要提供两种方式:RDB(在某个时间点给内存拍个快照)和AOF(记录下每一次写操作命令),通常建议至少开启AOF,并且设置为每秒同步一次,这样最多只会丢失一秒的数据,在大多数业务里是可以接受的,你不能把Redis当成一个黑盒子,插上电就不管了。

第二,内存容量管理,内存是有限的,而数据是无限的,如果你采集的数据量非常大,而处理消费的速度跟不上生产的速度,Redis的内存很快就会被塞满,一旦内存满了,Redis的默认策略是会拒绝新的写入请求,这就会导致数据采集中断,所以你需要监控Redis的内存使用情况,并制定策略,可以设置当内存用到80%时,就发出警报,让运维人员介入,或者,你可以使用Redis的“削峰填谷”能力,如果消费端暂时挂了,数据会在Redis里堆积起来,等消费端恢复后,再快速消费掉,但这要求你的Redis内存足够容纳这些“峰值的”数据量。
第三,高可用性,如果你的业务非常重要,不能容忍数据采集服务中断,那么单节点的Redis就有风险,万一这台Redis服务器本身宕机了,整个数据流就断了,这时候就需要搭建Redis集群,比如Redis Sentinel(哨兵)模式或者Cluster模式,简单说,就是弄几个Redis实例组成一个团队,有主有从,主节点挂了,从节点能自动顶上去,保证服务不中断。
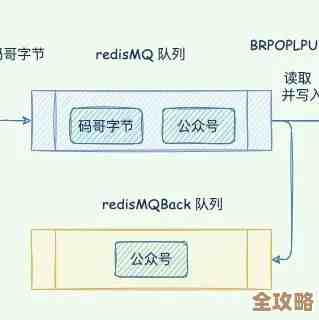
第四,消费者端的可靠性,想象一下,你的处理程序(消费者)从Redis里取出一条数据,正准备处理的时候,自己却崩溃了,这条数据已经被RPOP出来了,Redis里没有了,而消费者也没处理成功,这条数据就彻底丢失了,为了解决这个问题,Redis提供了更可靠的队列方案,比如使用BRPOPLPUSH命令,它可以在从一个列表取消息的同时,把这条消息备份到另一个“处理中”的列表,只有当消费者明确处理完成后,才从“处理中”列表删除它,如果消费者崩溃,监控程序可以把“处理中”列表的消息重新放回主队列,让其他消费者重新处理。
用Redis做数据采集,核心就是利用其内存速度的优势,扮演一个高性能的缓冲区和消息队列,实现起来概念不复杂,但真要用到生产环境,你必须像对待一个重要的基础设施一样对待它,认真考虑持久化、内存限制、高可用和消费可靠性这些实实在在的问题,才能保证你的数据流既快又稳。
(注:以上实现思路和关键点参考了常见的消息队列架构模式及Redis在其中的典型应用场景,如Celery等分布式任务队列的后端就常使用Redis。)
本文由邝冷亦于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/81363.html