用Redis能不能真让程序跑得快点,效率提升到底靠不靠谱

关于用Redis能不能真让程序跑得快一点,这个问题的答案是肯定的,但前提是得用对地方,它不是一颗包治百病的“万能仙丹”,而更像是一剂针对特定症状的“强效药”,效率提升靠不靠谱,完全取决于你是否把它用在了它最擅长的场景里。

要理解Redis为什么能提速,我们得先看看程序通常为什么会慢,很多时候,瓶颈出在数据库上,比如MySQL这类关系型数据库,它们功能强大,能处理复杂的查询和事务,但就像一辆重型卡车,拉重货很稳,但启动和跑起来肯定不如小车灵活,当大量用户同时请求同一个数据,比如一篇热门文章的详情,数据库就得一次次地吭哧吭哧地从硬盘里把数据读出来,这个磁盘I/O操作是比较耗时的。

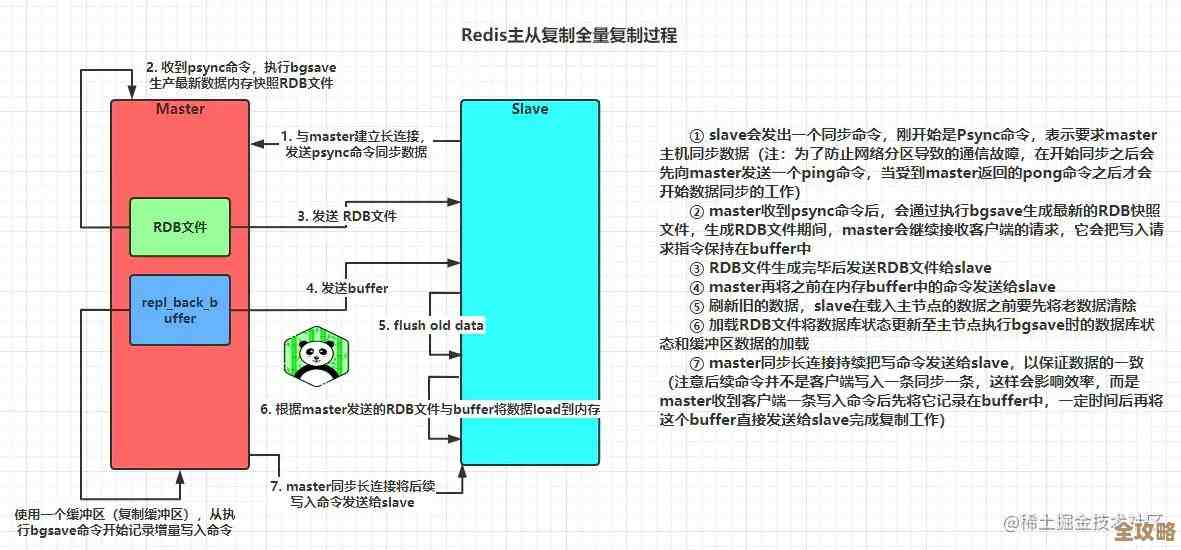
这时候,Redis的价值就凸显了,根据Redis官方文档对其特性的描述,Redis最核心的特点就是把所有数据都放在内存里进行读写,内存的访问速度比硬盘快了几个数量级,大概是几纳秒对几毫秒的差别,这就像是闪电和乌龟赛跑,如果把那个热门文章的数据提前从数据库里取出来,放进Redis,下次再有用户来要,程序就直接从Redis内存里拿,瞬间就能返回结果,速度的提升是立竿见影的,这个过程就是常说的“缓存”,是Redis最经典、最普遍的应用场景,很多大型网站,比如知乎、微博,都大量使用Redis来扛住瞬间的海量访问,这在实际应用中已经被反复验证是有效的。

除了做缓存,Redis在特定类型的数据处理上也能极大提升效率,比如计数功能,微博的转发数、评论数,如果每次+1都要去写数据库,数据库压力会巨大,而Redis提供了天然的支持计数的数据结构,这些操作都在内存里完成,速度极快,然后再定期或批量同步到数据库,这就把数据库的压力降下来了,再比如,排行榜功能,如果用数据库的ORDER BY来做,数据量一大就会很吃力,Redis自带的有序集合(Sorted Set)数据结构,天生就是为排行榜设计的,插入分数、按排名查询等操作都非常高效,还有像秒杀场景,库存查验和扣减需要极高的并发处理能力,利用Redis单线程和原子操作的特性,可以很好地防止超卖问题,这些都是在实践中总结出的可靠用法。
为什么又说它不一定靠谱呢?因为如果用得不对,反而会添乱。数据一致性是个大问题,因为Redis里的数据通常是数据库的一个副本,当你修改了数据库的数据后,需要及时去更新Redis里的缓存(缓存更新),否则用户读到的就是过时的脏数据,这个“及时”的策略很讲究,处理不好就会导致程序逻辑错误,Redis是内存数据库,内存成本比硬盘高得多,你不能把所有的数据都往Redis里塞,必须有选择地存放那些最常用、最需要快速访问的热点数据,虽然Redis本身很快,但如果你的程序瓶颈不在数据库IO,而是在于复杂的业务逻辑计算,或者慢在第三方接口的调用上,那么你加Redis也起不到任何提速效果,这叫没打到痛点上。
还有一点,Redis虽然快,但它不是万能的,它简化了数据模型,不支持SQL那样的复杂查询,也不具备关系型数据库强大的事务保证(ACID),所以它通常是与传统数据库配合使用,作为后者的补充和加速层,而不是替代品。
用Redis让程序跑得更快,这件事是绝对靠谱的,国内外无数互联网公司的技术架构都证明了这一点,但它的靠谱是有条件的,你需要清晰地认识到:你的程序慢在哪里?这个慢点是否正好是Redis能解决的(比如频繁读取数据库造成的IO压力)?你是否能接受并处理好由此带来的数据一致性问题?以及你是否能合理规划内存的使用?想清楚了这些问题,把Redis这把“快刀”用在合适的“刀刃”上,那么它带来的效率提升将是实实在在、非常显著的,如果盲目使用,那可能不仅看不到提速,还会增加系统的复杂度和维护成本。
本文由颜泰平于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://www.haoid.cn/wenda/80673.html